8.1.8 RAG 評価
この節を終えると、あなたは次のことができるようになります。
- RAG を 1 回のデモだけで良し悪し判断してはいけない理由を理解する
- 検索評価と回答評価の違いを整理する
- 小さなサンプルで簡単な指標を計算する
- 「まず評価し、それから改善する」という開発習慣を身につける
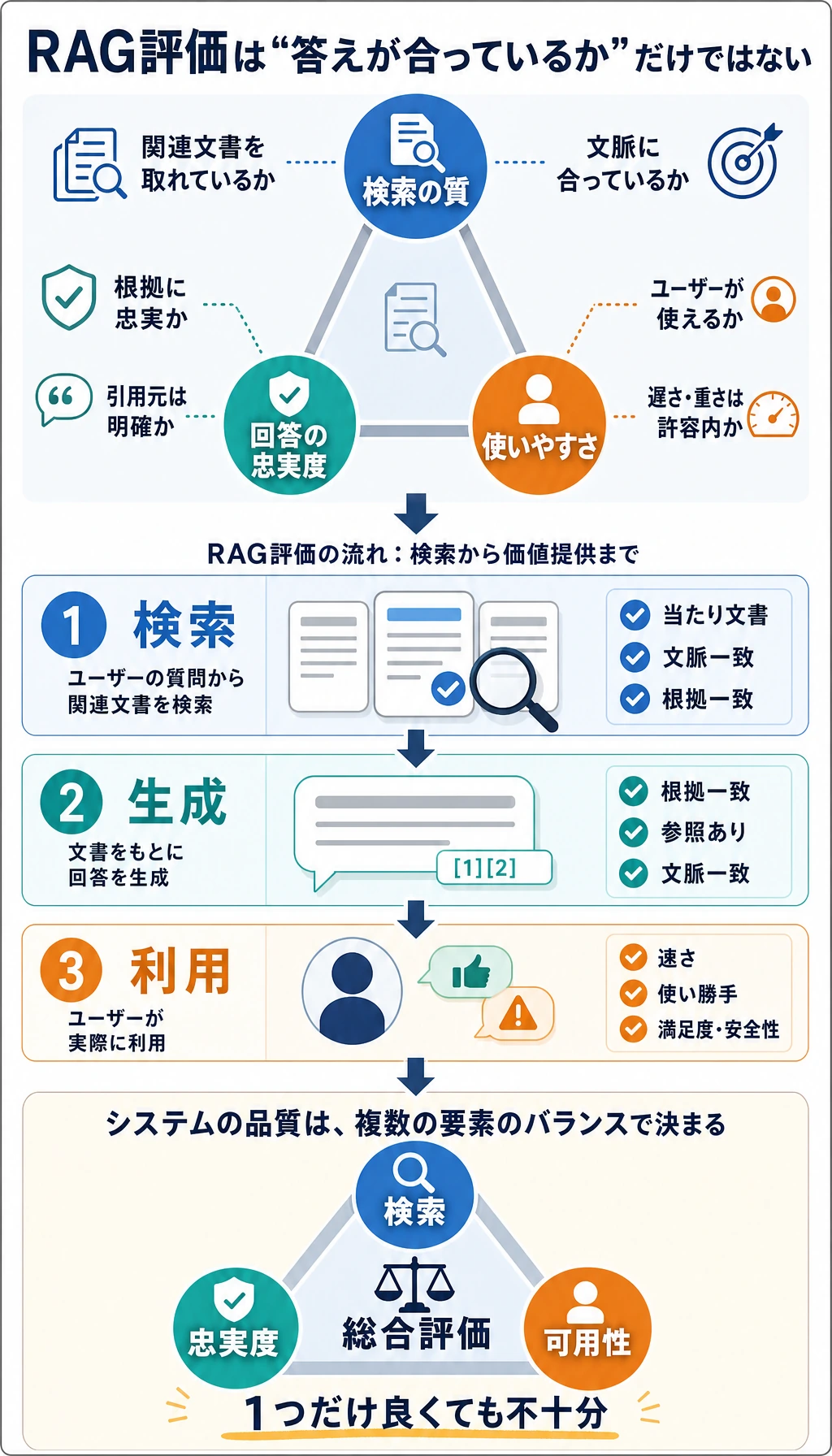
一、なぜ RAG には特に評価が必要なのか?
Section titled “一、なぜ RAG には特に評価が必要なのか?”単一のモジュールではないから
Section titled “単一のモジュールではないから”RAG は 1 つのモデルではなく、少なくとも次の要素を含みます。
- 文書処理
- 検索
- コンテキストの組み立て
- 回答生成
どれか 1 つでも失敗すると、最終的な答えは悪くなる可能性があります。
だから「正解したか」だけでは足りない
Section titled “だから「正解したか」だけでは足りない”次の点も確認する必要があります。
- 検索できなかったのか?
- 検索はできたが、うまく使えなかったのか?
- それとも、回答の文章がうまくまとまっていないのか?
だからこそ、RAG の評価は階層ごとに見る必要があります。
二、第一層:検索評価
Section titled “二、第一層:検索評価”最もよく使う直感的な指標:Hit@k
Section titled “最もよく使う直感的な指標:Hit@k”Hit@k の意味はとてもシンプルです。
正しい証拠が、上位 k 件の検索結果に入っているか?
ユーザーの質問に対する正しい証拠が top-3 にあれば、hit とみなします。
なぜこの指標が重要なのか?
Section titled “なぜこの指標が重要なのか?”正しい資料がそもそも取り出せていなければ、その後の生成で安定して正解するのはほぼ不可能だからです。
つまり、
検索評価は RAG 評価の土台です。
三、第二層:回答評価
Section titled “三、第二層:回答評価”「文章が自然」だけではまったく足りない
Section titled “「文章が自然」だけではまったく足りない”回答評価では、少なくとも次の点を見る必要があります。
- 答えが正しいか
- 根拠があるか
- 勝手に作っていないか
よく見る観点
Section titled “よく見る観点”| 観点 | 注目する点 |
|---|---|
| 正確性 | 事実として正しいか |
| 忠実性 | 与えられた資料に基づいているか |
| 関連性 | ユーザーの質問に答えているか |
| 完全性 | 重要な情報が漏れていないか |
実際の業務では、観点ごとの重要度は異なります。
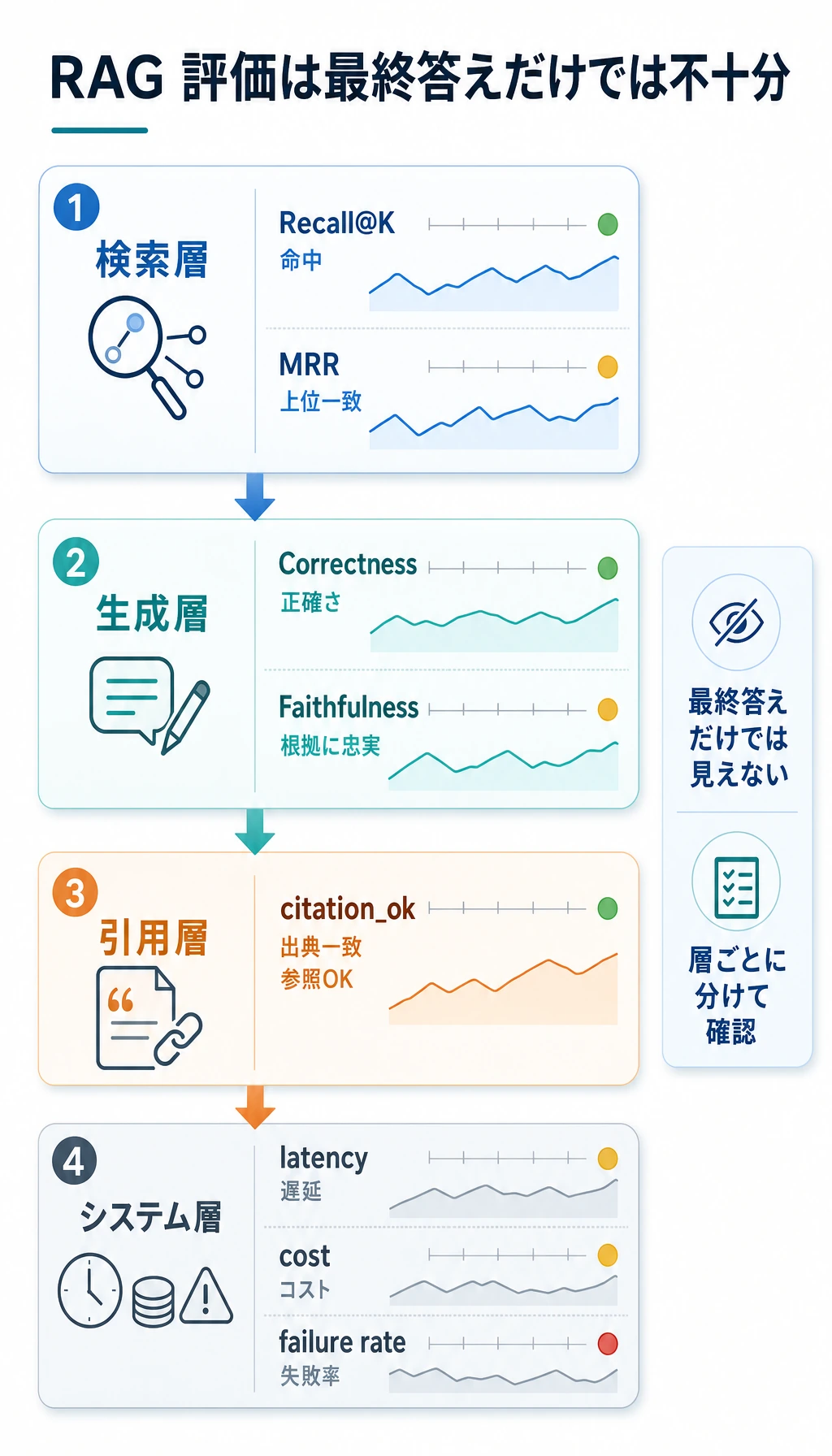
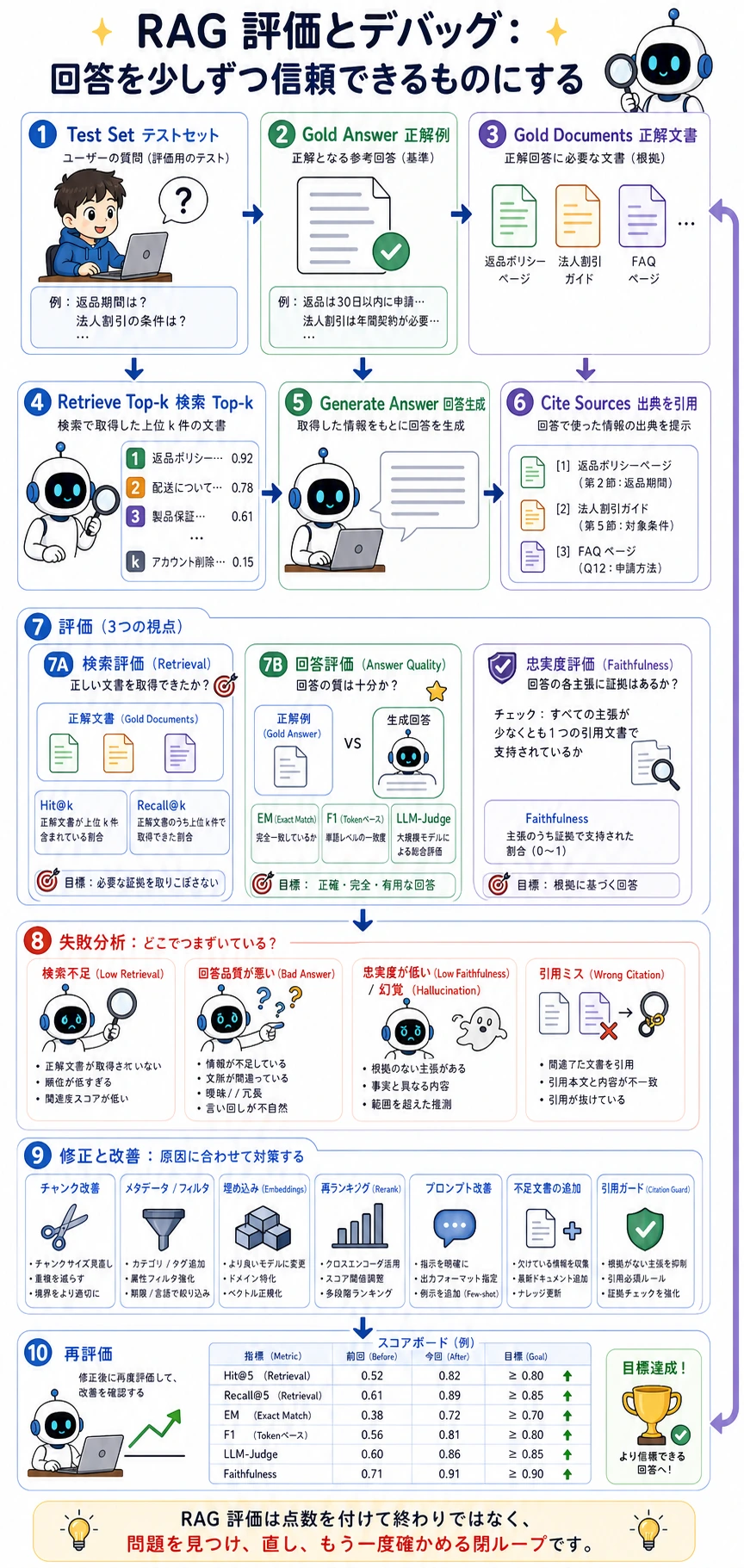
よい評価は 1 回で終わるものではなく、テストセット -> 検索 -> 回答 -> 引用 -> 失敗分析 -> 修正 -> 再評価、というループです。
四、最小の評価データセット
Section titled “四、最小の評価データセット”ここでは、手作業で作ったミニ評価データセットを用意します。
dataset = [ { "question": "いつまで返金できますか?", "gold_doc": "返金ポリシー", "gold_answer": "コース購入後 7 日以内に返金を申請できます" }, { "question": "どうやって証明書を取得しますか?", "gold_doc": "証明書の説明", "gold_answer": "プロジェクトを完了し、テストに合格すると証明書を取得できます" }]
predictions = [ { "retrieved_docs": ["返金ポリシー", "学習順序"], "answer": "コース購入後 7 日以内に返金を申請できます" }, { "retrieved_docs": ["学習順序", "証明書の説明"], "answer": "プロジェクトを完了し、テストに合格すると証明書を取得できます" }]
print(dataset)print(predictions)期待される出力:
[{'question': 'いつまで返金できますか?', 'gold_doc': '返金ポリシー', 'gold_answer': 'コース購入後 7 日以内に返金を申請できます'}, {'question': 'どうやって証明書を取得しますか?', 'gold_doc': '証明書の説明', 'gold_answer': 'プロジェクトを完了し、テストに合格すると証明書を取得できます'}][{'retrieved_docs': ['返金ポリシー', '学習順序'], 'answer': 'コース購入後 7 日以内に返金を申請できます'}, {'retrieved_docs': ['学習順序', '証明書の説明'], 'answer': 'プロジェクトを完了し、テストに合格すると証明書を取得できます'}]このデータは「正解」と「予測」に分けて読みます。gold_doc / gold_answer は参照基準で、retrieved_docs / answer は RAG システムが出した結果です。
五、簡単な Hit@k を計算する
Section titled “五、簡単な Hit@k を計算する”実行できる例
Section titled “実行できる例”dataset = [ { "question": "いつまで返金できますか?", "gold_doc": "返金ポリシー" }, { "question": "どうやって証明書を取得しますか?", "gold_doc": "証明書の説明" }]
predictions = [ { "retrieved_docs": ["返金ポリシー", "学習順序"] }, { "retrieved_docs": ["学習順序", "証明書の説明"] }]
hits = 0for item, pred in zip(dataset, predictions): if item["gold_doc"] in pred["retrieved_docs"]: hits += 1
hit_at_2 = hits / len(dataset)print("Hit@2 =", round(hit_at_2, 4))期待される出力:
Hit@2 = 1.0正しい文書がすべて上位 2 件に入っていれば、この値は 1.0 になります。
この指標の限界
Section titled “この指標の限界”これで分かるのは「取り出せたかどうか」だけです。
次のことは分かりません。
- 何位だったのか
- 回答が本当に正しいのか
なので、これはあくまで最初の一歩です。
六、簡単な回答正解率を計算する
Section titled “六、簡単な回答正解率を計算する”最もシンプルな完全一致(Exact Match)の考え方
Section titled “最もシンプルな完全一致(Exact Match)の考え方”構造化された短い回答なら、まずは素朴な方法で確認できます。
dataset = [ { "gold_answer": "コース購入後 7 日以内に返金を申請できます" }, { "gold_answer": "プロジェクトを完了し、テストに合格すると証明書を取得できます" }]
predictions = [ { "answer": "コース購入後 7 日以内に返金を申請できます" }, { "answer": "プロジェクトを完了し、テストに合格すると証明書を取得できます" }]
correct = 0for item, pred in zip(dataset, predictions): if item["gold_answer"] == pred["answer"]: correct += 1
exact_match = correct / len(dataset)print("Exact Match =", round(exact_match, 4))期待される出力:
Exact Match = 1.0でも実際の場面はそんなに単純ではない
Section titled “でも実際の場面はそんなに単純ではない”同じ正解でも、言い方はいろいろあります。
そのため、実運用では次のような方法もよく使います。
- 意味ベースのマッチング
- LLM-as-a-judge
- 人手によるサンプルチェック
七、忠実性:回答は根拠に基づいているか?
Section titled “七、忠実性:回答は根拠に基づいているか?”「それっぽく見える」より大事
Section titled “「それっぽく見える」より大事”文章としては流暢でも、検索した資料に基づいていないなら危険です。
簡単な確認方法の例
Section titled “簡単な確認方法の例”以下の例はかなり単純ですが、「回答が証拠で支えられているか」を理解する助けになります。
evidence = "コース購入後 7 日以内に返金を申請できます"answer = "コース購入後 7 日以内に返金を申請できます"
faithful = answer in evidence or evidence in answerprint("証拠に支えられているか:", faithful)期待される出力:
証拠に支えられているか: True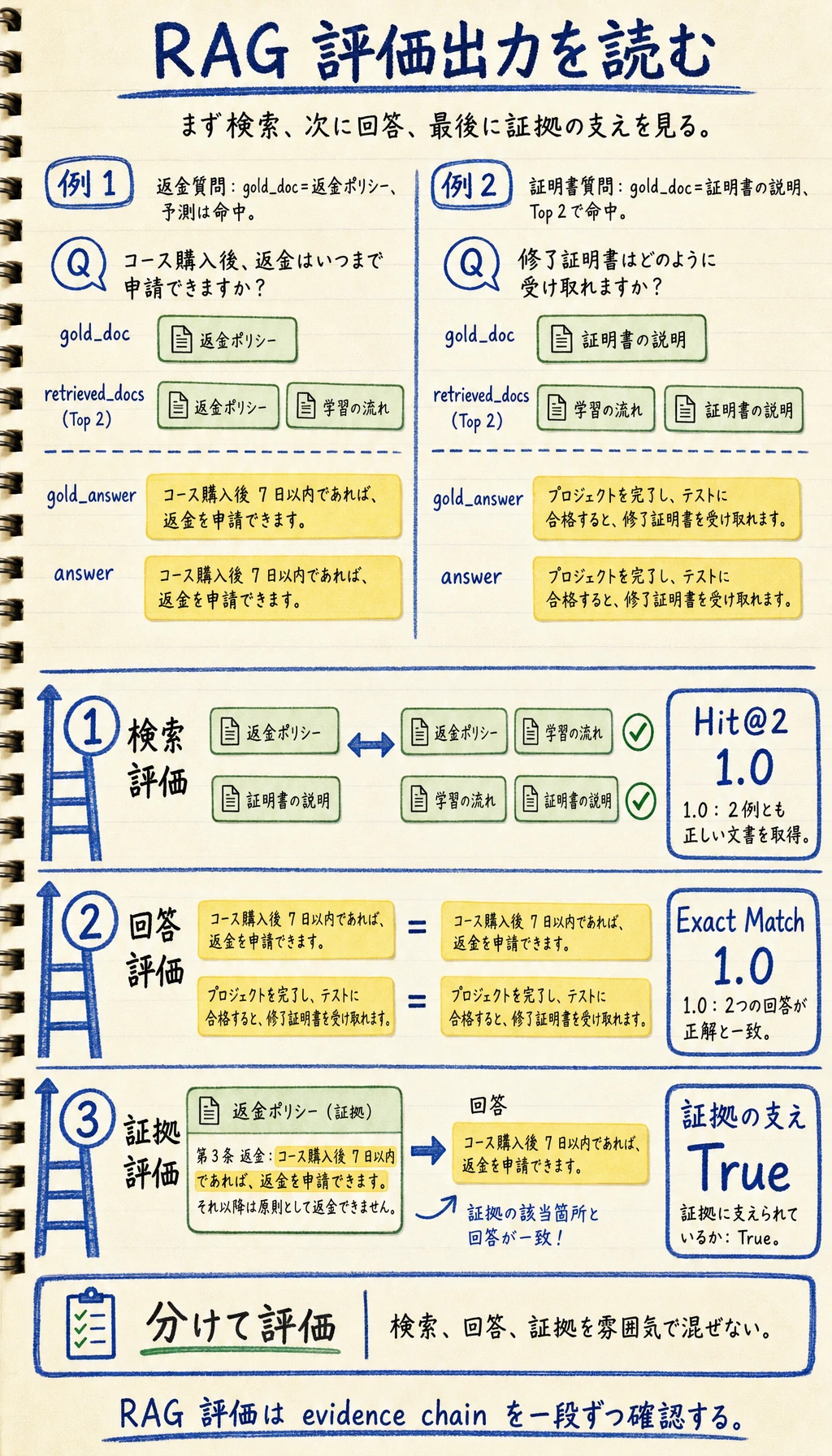
実際のシステムでは、もちろんこんな文字列比較だけではありません。
ただ、考え方としては正しいです。
回答は、できるだけ検索した証拠の中で支えられるべきです。

八、評価データセットはどう作る?
Section titled “八、評価データセットはどう作る?”最小限で使える評価セット
Section titled “最小限で使える評価セット”少なくとも次を含めましょう。
- ユーザーの質問
- 標準回答
- 正しい証拠文書または証拠スニペット
難しさの違う問題を混ぜるのがおすすめ
Section titled “難しさの違う問題を混ぜるのがおすすめ”たとえば次のような問題です。
- 簡単な事実問答
- 同義表現の質問
- 複数段落にまたがる質問
- 混同しやすい質問
評価セットが単一的すぎると、改善結果が実態より良く見えてしまいます。
九、オンライン評価もとても重要
Section titled “九、オンライン評価もとても重要”オフライン評価だけでは全部は分からない
Section titled “オフライン評価だけでは全部は分からない”ローカルのデータセットがどれだけ良くても、実際のユーザー質問を完全にはカバーできません。
よく見るオンラインのシグナル
Section titled “よく見るオンラインのシグナル”たとえば次のようなものです。
- ユーザーの追加質問率
- ユーザーの修正率
- いいね / 低評価
- 人手による品質チェックのサンプリング
成熟した RAG システムでは、通常「オフライン評価 + オンラインフィードバック」をセットで見ます。
十、目標が「知識ベース駆動の SOP 文書アシスタント」なら、何を重視して評価する?
Section titled “十、目標が「知識ベース駆動の SOP 文書アシスタント」なら、何を重視して評価する?”このタイプのプロジェクトは、普通の QA システムとは少し違います。
大事なのは「答えがそれっぽいか」だけではなく、次の点です。
- ポリシー資料を正しく見つけられているか
- 対応ケースを適切に取れているか
- チェックリストと最終的なセクションを正しい場所に置けているか
- 出典をたどれるか
このようなプロジェクトに向いた評価表では、少なくとも次のような層を追加するとよいです。
| 観点 | 何を見るか |
|---|---|
| ポリシー命中 | そのテーマの公式ポリシー資料を見つけられたか |
| ケース検索 | SOP を支える対応ケースを見つけられたか |
| 構造の正しさ | ポリシー、ケース、チェックリストが正しいセクションに入っているか |
| 出典の完全性 | 最終結果を元資料までたどれるか |
まずは次のように理解するとよいです。
SOP 文書プロジェクトの評価は、「答えたか」ではなく「見つけたか、置けたか、引用できたか」を見ることです。
十一、SOP 文書プロジェクトに近い最小評価例
Section titled “十一、SOP 文書プロジェクトに近い最小評価例”dataset = [ { "topic": "返金エスカレーション", "gold_policies": ["重複請求の返金は、取引証拠を添えてエスカレーションする必要がある。"], "gold_cases": ["決済失敗後の重複請求ケースは、支払い証拠を添えて billing にエスカレーションされた。"], }]
prediction = { "policies": ["重複請求の返金は、取引証拠を添えてエスカレーションする必要がある。"], "cases": ["決済失敗後の重複請求ケースは、支払い証拠を添えて billing にエスカレーションされた。"], "source_refs": [{"doc_id": "refund_policy_001", "page_or_slide": 3}],}
print(dataset[0])print(prediction)期待される出力:
{'topic': '返金エスカレーション', 'gold_policies': ['重複請求の返金は、取引証拠を添えてエスカレーションする必要がある。'], 'gold_cases': ['決済失敗後の重複請求ケースは、支払い証拠を添えて billing にエスカレーションされた。']}{'policies': ['重複請求の返金は、取引証拠を添えてエスカレーションする必要がある。'], 'cases': ['決済失敗後の重複請求ケースは、支払い証拠を添えて billing にエスカレーションされた。'], 'source_refs': [{'doc_id': 'refund_policy_001', 'page_or_slide': 3}]}この例は小さいですが、初学者が評価の感覚をつかむのに役立ちます。
- この種のシステムで最終的に評価するのは、たいてい「1 文の答え」ではない
- 1 つの構造化された結果全体である
十二、初学者によくある誤解
Section titled “十二、初学者によくある誤解”1 つか 2 つの成功例だけを見る
Section titled “1 つか 2 つの成功例だけを見る”デモはやる気を出させますが、評価の代わりにはなりません。
回答だけ評価して、検索を評価しない
Section titled “回答だけ評価して、検索を評価しない”これだと、問題がどの層で起きているのか分かりにくくなります。
システムを修正しながら、評価セットを固定しない
Section titled “システムを修正しながら、評価セットを固定しない”固定された評価セットがないと、本当に改善したのか、それともたまたま変動しただけなのか判断しにくくなります。
RAG プロジェクトの評価指標まとめ表
Section titled “RAG プロジェクトの評価指標まとめ表”RAG プロジェクトでは、「答えがそれっぽいか」だけを見てはいけません。より安定した方法は、評価を検索、生成、引用、システムの 4 層に分けることです。
| 層 | 指標 | 説明 |
|---|---|---|
| 検索層 | 命中率、Recall@K、MRR | 正しい資料が見つかったか、上位に来ているか |
| 生成層 | 回答正解率、完全性、一貫性 | 資料に基づいて答えられているか、重要条件を落としていないか |
| 引用層 | 引用カバレッジ、引用の真正性 | 回答中の重要な結論が出典にたどれるか |
| システム層 | レイテンシ、コスト、失敗率 | 実ユーザーに安定して、無理なく提供できるか |
最小評価セットは、まず 20〜50 問ほど用意するのがおすすめです。各問題に標準回答、命中すべき文書、重要な引用を付けておきます。こうしておけば、chunk、embedding、rerank、query rewrite を改善したときに、本当に良くなったのか、それとも一部の例だけ見栄えが良くなったのかを判断できます。
層ごとの失敗原因の切り分け表
Section titled “層ごとの失敗原因の切り分け表”評価の価値は、単に総合点を出すことではありません。次にどこを直すべきかを知ることです。下の表は、実験記録にそのまま使えます。失敗が出たら、まずどの層の問題かを切り分けましょう。
- 検索層: 正しい文書が top-k に入りません。クエリ、chunk、embedding、キーワード一致を確認し、チャンク分割、混合検索、クエリ書き換えを調整します。
- コンテキスト層: 正しい文書は top-k にあるのに、最終コンテキストに入りません。構成、重複除去、長さ制限を確認し、並び順、圧縮、パッキングを調整します。
- 生成層: コンテキストに証拠はあるのに、回答が重要条件を落とします。prompt、回答形式、証拠への従い方を確認し、証拠ベースで段階的に答えるようにします。
- 引用層: 結論は正しいのに引用が支えていません。
source_refs、引用スニペット、回答文を確認し、証拠のない引用を禁止します。 - プロダクト層: オフライン評価は良いのに、ユーザーが何度も追い質問します。実際の質問分布と評価セットの範囲を確認し、オンライン質問を評価セットに追加します。
「最終的に正解したか」だけを見ると、これらの問題は混ざってしまいます。層ごとに切り分けると、改善のアクションがはっきりします。検索が悪いなら prompt をいじる前に検索を直すべきですし、引用が悪いなら答えの自然さだけを見ても意味がありません。
そのまま使える評価記録テンプレート
Section titled “そのまま使える評価記録テンプレート”RAG プロジェクトでは、毎回の評価を固定フォーマットで残すのがおすすめです。最初は十数件でも、単発のデモを見るよりずっと安定して状況を把握できます。
| フィールド | 例 | 用途 |
|---|---|---|
question | コースはいつまで返金できますか? | ユーザーの質問 |
gold_doc | 返金ポリシー | 命中すべき資料 |
gold_answer | コース購入後 7 日以内に返金を申請できます | 標準回答または重要事実 |
retrieved_docs | 返金ポリシー, 学習順序 | 実際に命中した文書 |
answer | 7 日以内に返金を申請できます | システムの回答 |
citation_ok | true | 引用が回答を支えているか |
failure_type | none / retrieval / generation / citation | 失敗原因 |
notes | 正しく命中し、引用も支えている | 人手メモ |
最小の CSV は次のように書けます。
question,gold_doc,gold_answer,retrieved_docs,answer,citation_ok,failure_type,notesコースはいつまで返金できますか?,返金ポリシー,コース購入後 7 日以内に返金を申請できます,"返金ポリシー;学習順序",コース購入後 7 日以内に返金を申請できます,true,none,正しく命中し引用も支えているどうやって証明書を取得しますか?,証明書の説明,プロジェクトを完了し、テストに合格すると証明書を取得できます,"学習順序;証明書の説明",プロジェクトを完了すると証明書を取得できます,false,generation,テストに合格するという重要条件が抜けているこのテンプレートのポイントは、項目が多いことではありません。各サンプルについて、次の 3 つが分かることです。何を命中すべきか、実際に何を命中したか、最終回答は証拠に支えられているか。
SOP 文書 RAG の受け入れ Rubric
Section titled “SOP 文書 RAG の受け入れ Rubric”プロジェクトの目的が SOP 文書や社内運用文書の生成なら、評価は QA の段階だけで終わらせるべきではありません。次の rubric は、ポートフォリオ用プロジェクトの受け入れ基準として使えます。
- 練習レベル: テーマ関連資料を命中し、基本的な回答や断片を生成し、参照ファイル名を表示できます。
- プロジェクトレベル: topic と content_type でポリシー、ケース、チェックリストを検索し、決まった SOP セクションで出力し、重要セクションに出典を付けます。
- ポートフォリオレベル: 固定評価セットと失敗サンプルを持ち、失敗が検索・生成・テンプレートのどれかを説明し、重要な結論を原文までたどれます。
- 面接レベル: baseline、混合検索、rerank を比較し、品質・コスト・レイテンシの取捨選択を説明し、引用の真正性を抽出確認して改善記録を残せます。
この表はそのまま README に入れられます。そうすれば、見る人に「ただ質問に答えるデモを作った」のではなく、「知識ベース駆動システムを工程として評価している」ことが伝わります。
このページを終えたら、この証拠カードを残します。
- クエリ
- 1つのユーザー質問またはテストケース
- 検索チャンク
- chunk id、スコア、ソースタイトル
- 回答
- 引用または出典メモ付きの最終回答
- 失敗確認
- 証拠不足、誤ったチャンク、古い文書、または裏付けのない主張
- 次の行動
- chunking、embedding、reranking、prompt、または eval の変更
この節で最も大事なポイントは次の通りです。
RAG 評価はおまけではなく、システム改善のためのハンドルです。
評価がなければ、感覚でしか改善できません。
評価があれば、どこが悪いのか、変更が本当に効果を出したのかが分かります。
- 評価セットにさらに 3 問追加して、自分で
gold_docとgold_answerを書いてみましょう。 predictionsを変更して、わざと 1 つの回答を間違えさせ、Hit@k と Exact Match をもう一度計算してみましょう。- 考えてみましょう。Hit@k は高いのに、最終回答がよく間違うなら、問題はどの層にある可能性が高いでしょうか?
参考実装と解説
- よい評価質問には、簡単な直接検索、同義表現、permission-sensitive case、紛らわしい near match を少なくとも 1 つ含めます。
gold_docとgold_answerは、model output を見る前に書きます。 - Hit@k は正しい evidence が取れたかを測り、Exact Match は最終回答が期待回答と一致したかを測ります。わざと誤答を入れると、retrieval が正しくても answer metric は下がるはずです。
- Hit@k が高いのに回答が間違う場合、問題は first-stage retriever よりも、generation、context packing、citation、answer verification の層にある可能性が高いです。