6.1.1 ニューラルネットワークロードマップ:線形層、活性化、損失、更新
ニューラルネットワークは魔法ではありません。層はまず重み付き和を計算し、活性化で信号の形を変え、学習では重みを調整して loss を下げます。
まず流れを見る
Section titled “まず流れを見る”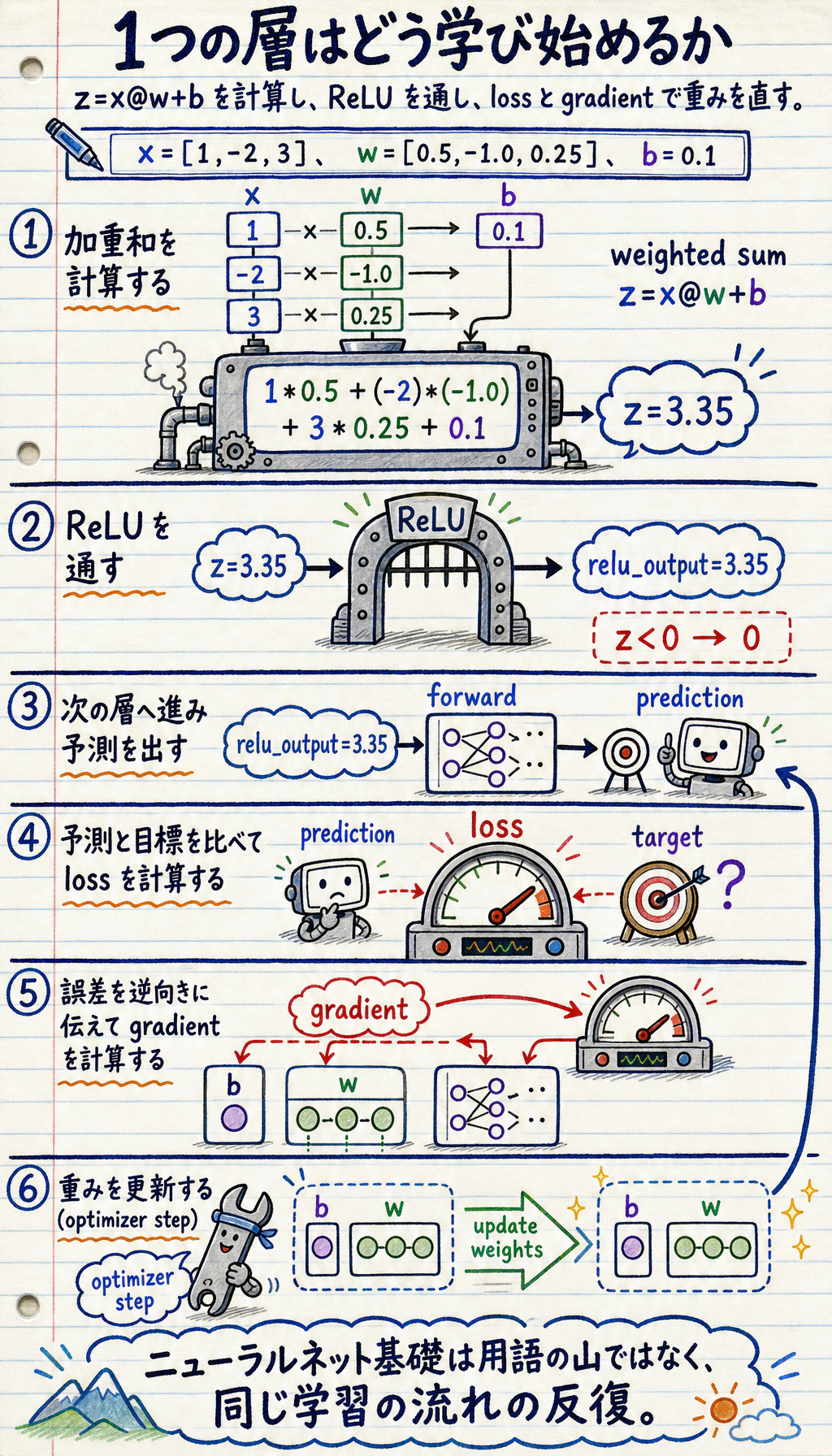
このループを覚えます。
入力重み付き和活性化loss勾配重み更新
| 用語 | 最初の意味 |
|---|---|
| ニューロン | 重み付き和とバイアス |
| 活性化 | ReLU などの非線形変化 |
| 順伝播 | 予測を計算する |
| 逆伝播 | 誤差への責任を計算する |
| オプティマイザ | 勾配で重みを更新する |
ニューロンを1つ動かす
Section titled “ニューロンを1つ動かす”nn_first_loop.py を作り、torch をインストールしてから実行します。
import torch
x = torch.tensor([[1.0, -2.0, 3.0]])weights = torch.tensor([[0.5], [-1.0], [0.25]])bias = torch.tensor([0.1])
linear_output = x @ weights + biasactivated = torch.relu(linear_output)
print("linear_output:", round(linear_output.item(), 3))print("relu_output:", round(activated.item(), 3))出力:
linear_output: 3.35relu_output: 3.35線形出力が負なら、ReLU はそれを 0 にします。この小さなゲートによって、多層ネットワークは非線形パターンを表せます。
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | まず見ること |
|---|---|---|
| 1 | 6.1.2 ML から DL へ | sklearn の後に何が変わるか |
| 2 | 6.1.3 ニューロンと活性化 | 重み付き和、バイアス、ReLU |
| 3 | 6.1.4 順伝播と逆伝播 | 予測、loss、勾配 |
| 4 | 6.1.5 オプティマイザ | SGD、Momentum、Adam の直感 |
| 5 | 6.1.6 正則化 | 過学習を抑える |
| 6 | 6.1.7 重み初期化 | 安定した開始点 |
| 7 | 6.1.8 任意の歴史背景 | backprop、CNN、RNN、Attention、Transformer がなぜ現れたか |
6.1 の終わりに、次の 4 行メモを残します。
- 一層
- 入力 @ 重み + バイアス
- 非線形性
- activation により、重ねた層が曲線的なパターンをモデル化できる
- 学習フロー
- forward → loss → backward → optimizer step(前向き計算、損失、逆伝播、最適化ステップ)
- デバッグ最初
- 形状、損失、勾配、更新を確認する
このメモは、後で PyTorch、CNN、RNN、Transformer を読むときの小さな地図になります。
1つの層を input @ weights + bias として説明し、活性化が何をするかを言え、loss、勾配、オプティマイザを1つの学習ループとしてつなげられれば合格です。
確認の考え方と解説
- 合格レベルの答えでは、tensor、model layer、loss、
backward()、optimizer update を1つの学習ループとしてつなげます。 - 証拠には、動く小さな実験、tensor shape の確認、説明できる loss または validation curve を含めます。
- shape mismatch、loss が下がらない、過学習、data leakage、Attention/Transformer の data flow を説明できない、といった失敗例を1つ言えればよいです。