5.3.1 教師なし学習ロードマップ:ラベルなしで構造を見つける
教師なし学習は、データにラベルがないところから始まります。モデルは最終的な真実を教えるのではなく、あり得る構造を見つける手助けをします。
まず構造マップを見る
Section titled “まず構造マップを見る”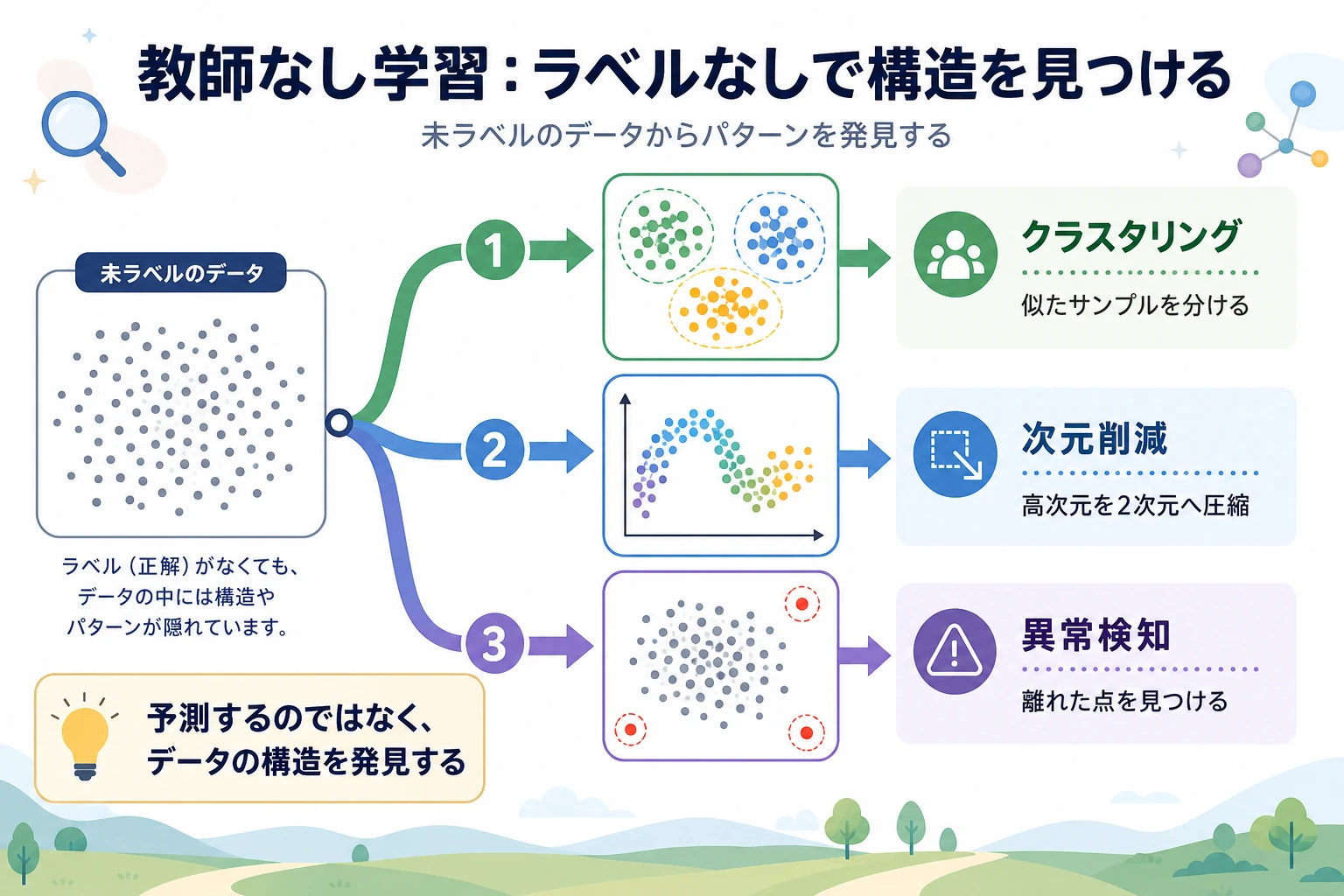
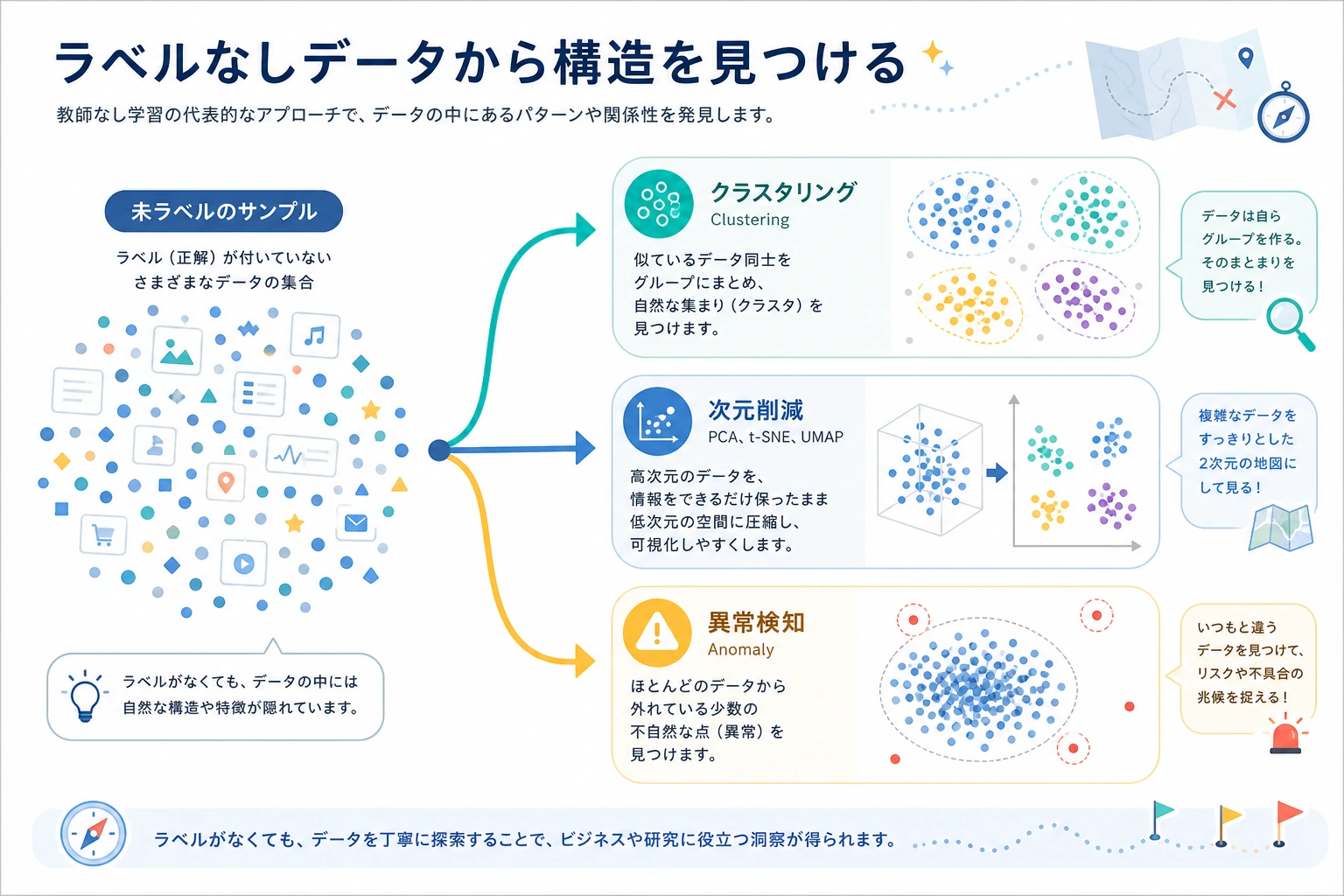
| やりたいこと | まず使うもの |
|---|---|
| 自然なグループを見つける | クラスタリング |
| 高次元データを圧縮する | 次元削減 |
| 普通ではない点を見つける | 異常検知 |
重要なのは「ラベルが正しいか」ではなく、「この構造に証拠と意味があるか」です。
クラスタリング baseline を1つ動かす
Section titled “クラスタリング baseline を1つ動かす”unsupervised_first_loop.py を作り、scikit-learn をインストールしてから実行します。
from sklearn.cluster import KMeansfrom sklearn.datasets import make_blobs
X, _ = make_blobs(n_samples=30, centers=3, random_state=7, cluster_std=0.8)
model = KMeans(n_clusters=3, random_state=7, n_init="auto")labels = model.fit_predict(X)
print("cluster_count:", len(set(labels)))print("first_five_labels:", labels[:5].tolist())print("inertia:", round(model.inertia_, 2))出力:
cluster_count: 3first_five_labels: [2, 0, 0, 1, 0]inertia: 43.44クラスタリングが返すのはグループ番号であり、人間にとっての意味ではありません。グラフ、特徴量の要約、ドメイン解釈が必要です。
このページを終えたら、この evidence card を残します。
- タスク
- clustering、dimensionality reduction、または anomaly detection の目標
- データ表示
- スケーリング済み特徴量、射影、クラスタ、または異常スコア
- 解釈
- このシナリオでグループ、軸、またはアラートが何を意味するか
- 失敗確認
- 任意のクラスタ数、スケーリングの問題、ノイズの多い次元、または誤検知
- 期待される成果
- 解釈と不確実性メモを含む教師なし結果
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | 練習すること |
|---|---|---|
| 1 | 5.3.2 クラスタリング | K-Means、クラスタ解釈、悪いクラスタ数選択 |
| 2 | 5.3.3 次元削減 | PCA、可視化、圧縮 |
| 3 | 5.3.4 異常検知 | 外れ値、しきい値、アラートの証拠 |
探している構造を説明し、教師なしモデルを1つ動かし、出力を絶対的な真実として扱わず慎重な解釈を書ければ合格です。
確認の考え方と解説
- 教師なし学習の出力は、構造についての仮説であり、検証済みの答えではありません。
- よい解釈には、図または特徴量要約、構造への慎重な名前付け、不確実性についての一言が含まれます。
- 最初に確認する失敗点は、スケーリング、恣意的なクラスタ数、ノイズの多い次元、数値上は異常でも文脈上は普通なアラートです。