A.3 AI 发展史:15 个阶段与关键论文
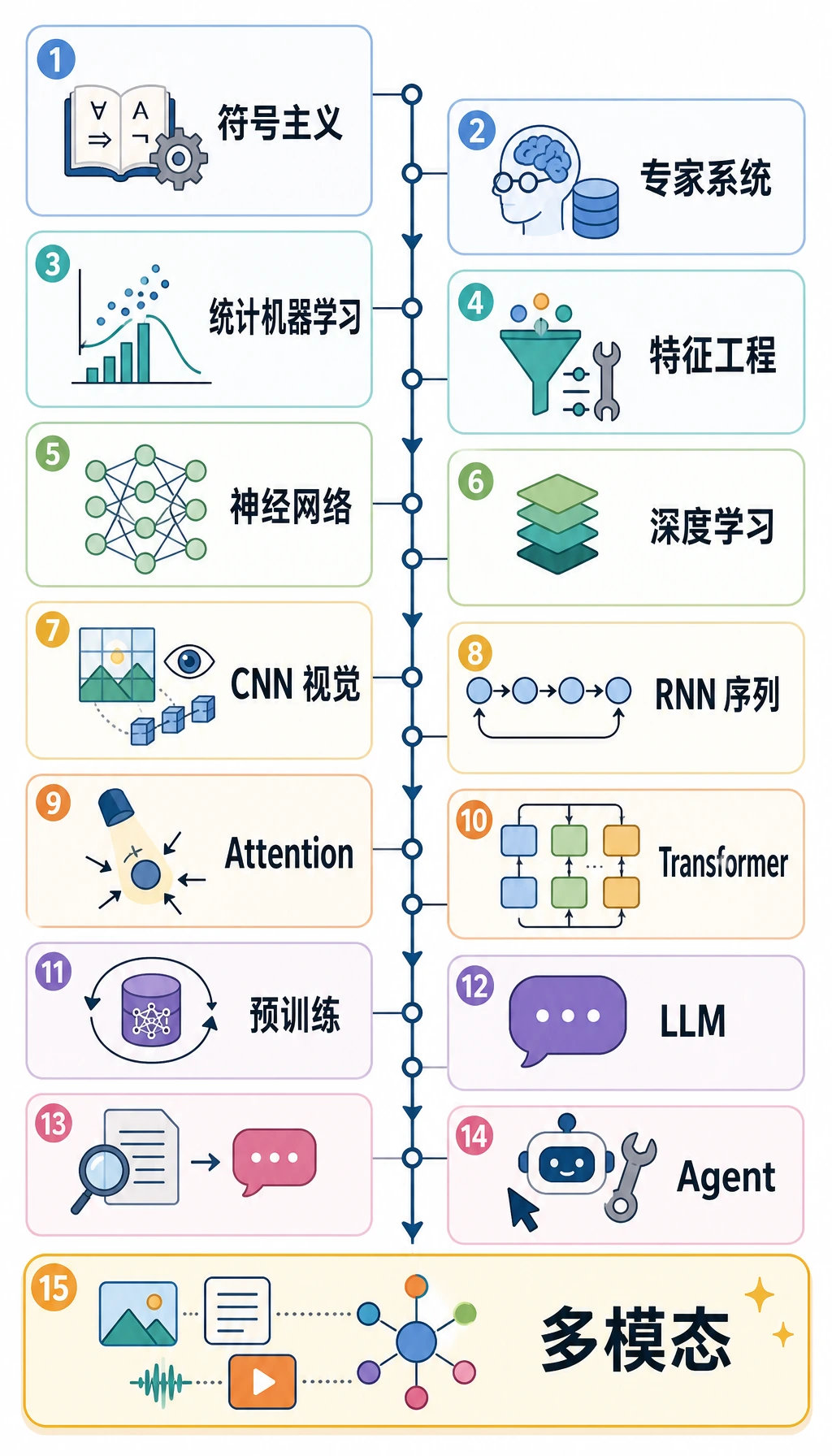
这一页是可选背景材料。它的作用是回答“这个概念从哪里来”,不是让你第一遍就背论文名。
建议按这个顺序使用:
- 先看 15 阶段总图。
- 快速扫一遍阶段表。
- 只挑当前章节相关的阶段看。
- 以后遇到论文名或算法名时再回来查。
15 阶段地图
Section titled “15 阶段地图”| 阶段 | 新人理解 | 对应课程 |
|---|---|---|
| 1. AI 问题被提出 | 机器能不能表现出智能 | 导学 |
| 2. 符号主义 AI | 人写规则,机器按规则推理 | 背景知识 |
| 3. 专家系统 | 把领域知识写成规则软件 | 系统思维 |
| 4. 概率与统计 | 不只靠固定规则,也用证据和不确定性判断 | 第 4 章 |
| 5. 经典机器学习 | 从数据和特征里学习规律 | 第 5 章 |
| 6. 早期神经网络 | 模型开始学习简单决策边界 | 第 5-6 章 |
| 7. 反向传播 | 多层神经网络真正可训练 | 第 6 章 |
| 8. 核方法与集成学习 | SVM、树、森林、Boosting 让 ML 更实用 | 第 5 章 |
| 9. 深度学习突破 | 数据 + GPU + 深层网络打开视觉和语音能力 | 第 6、10 章 |
| 10. 嵌入与序列模型 | 文本变成向量,序列可以被学习 | 第 11 章 |
| 11. Transformer 与预训练 | Attention 让大规模语言模型变得可行 | 第 6-7 章 |
| 12. 大模型与对齐 | 模型开始像助手一样听指令 | 第 7 章 |
| 13. RAG | 模型连接外部知识和引用来源 | 第 8 章 |
| 14. Agent 与工具调用 | 模型能规划、调工具、留下执行轨迹 | 第 9 章 |
| 15. 多模态与 AIGC | AI 处理文本、图像、语音、视频和生成任务 | 第 12 章 |
最重要的规律很简单:每一代都在解决上一代的瓶颈,同时又带来新的工程问题。
把主线看成接力赛
Section titled “把主线看成接力赛”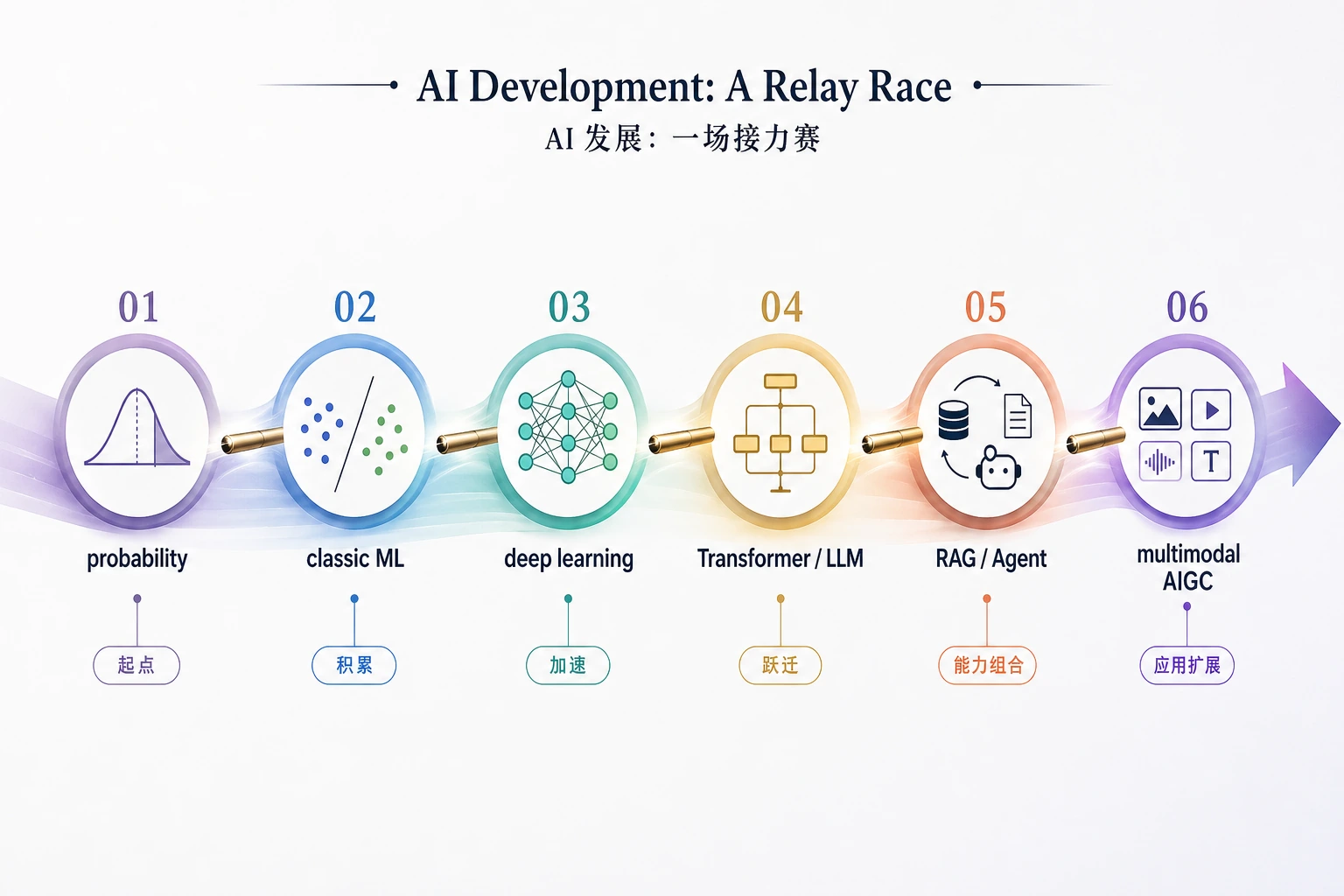
AI 历史比论文清单更像接力赛:
| 接力变化 | 发生了什么 |
|---|---|
| 规则 -> 概率 | 系统从固定逻辑走向不确定证据 |
| 概率 -> 机器学习 | 模型开始从数据里学习规律 |
| 机器学习 -> 深度学习 | 特征不再全靠人工设计,开始被模型学习 |
| 深度学习 -> Transformer | 序列建模更容易规模化 |
| LLM -> RAG / Agent | 模型连接知识、工具和工作流 |
| 文本 -> 多模态 | AI 开始理解和生成多种媒体 |
最值得先记住的 6 个转折点
Section titled “最值得先记住的 6 个转折点”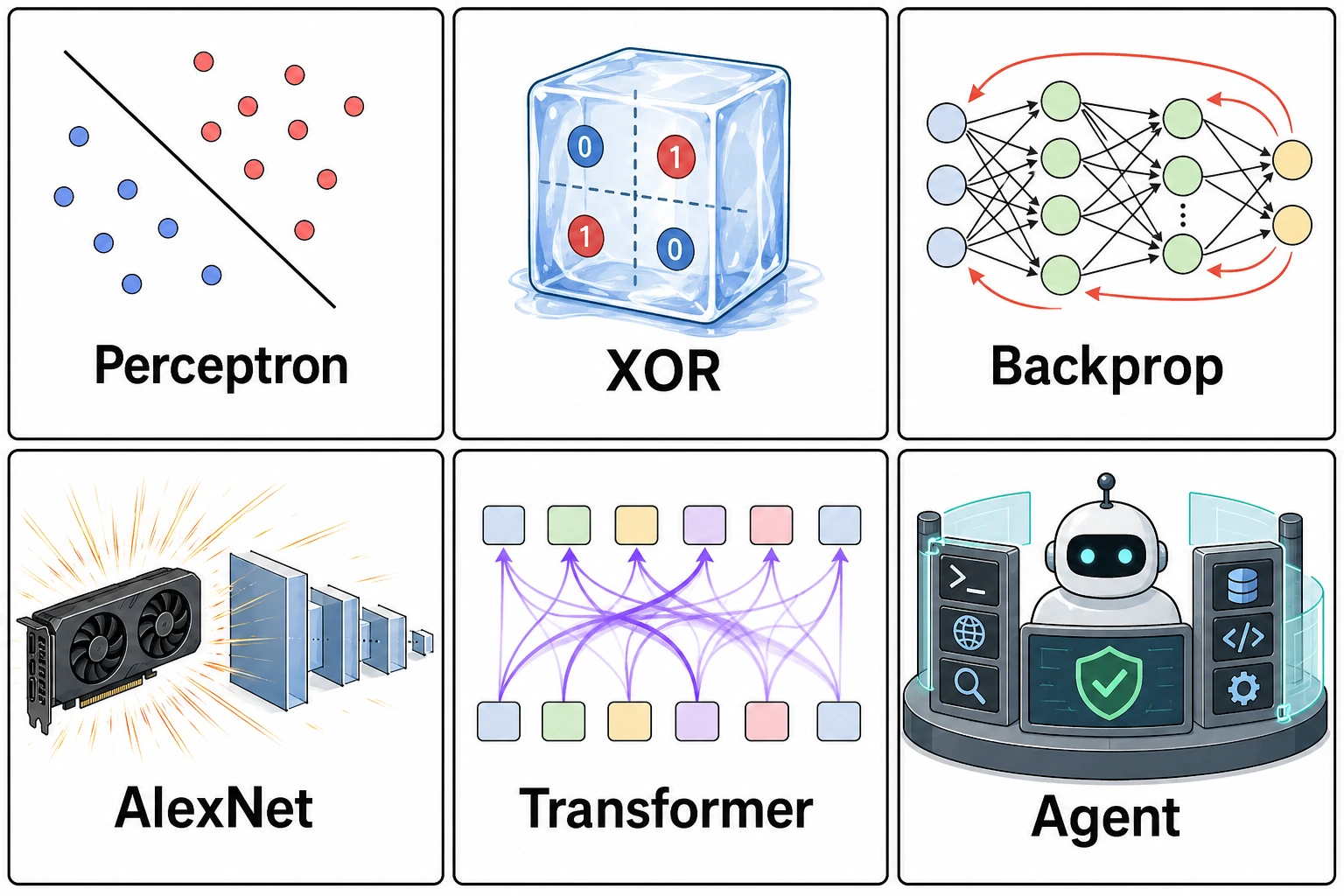
| 转折点 | 新人为什么要关心 |
|---|---|
| 感知器 | 人们第一次强烈感觉机器也许能从数据中学习 |
| XOR 限制 | 提醒我们简单线性模型远远不够 |
| 反向传播 | 多层神经网络开始真正可训练 |
| AlexNet | 数据、GPU 和深层 CNN 让深度学习爆发 |
| Transformer | Attention 改写了序列建模主线 |
| RAG / Agent | 模型从回答文字走向使用知识和工具 |
第一遍不要急着背年份。先记住这条情绪线:希望、受挫、修复、规模化、工程化。
怎么读一个论文节点
Section titled “怎么读一个论文节点”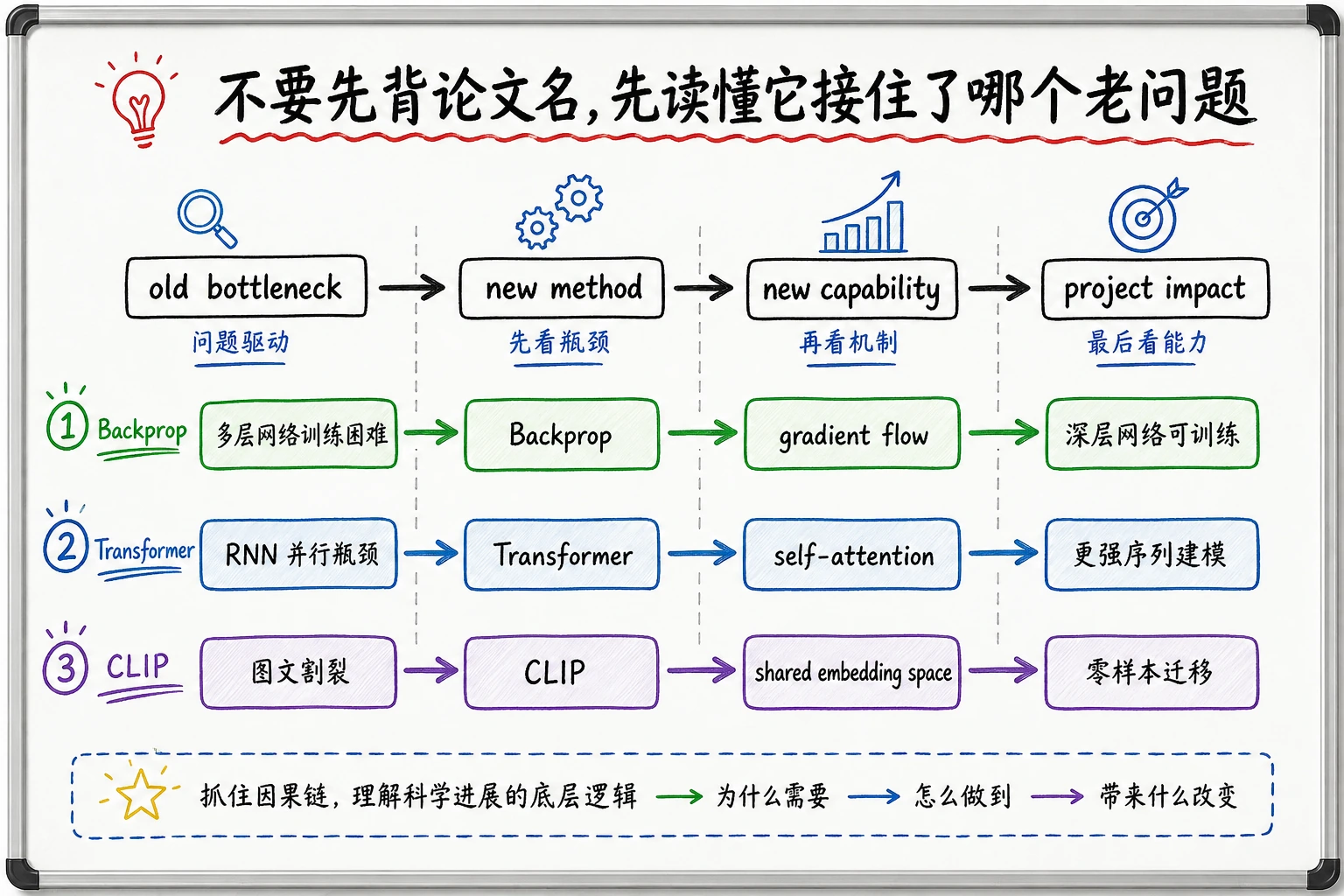
看到任何论文或算法,先问四个问题就够了。答案要短到能放进一张复习卡:
| 问题 | 新人回答模板 |
|---|---|
| 旧瓶颈 | 说清旧限制。以 Transformer 为例,RNN 不易并行,长距离路径成本高。 |
| 新方法 | 说清机制变化。以 Transformer 为例,self-attention 成为关键方法。 |
| 新能力 | 说清什么变容易了。大规模序列建模变得更可行。 |
| 影响项目 | 说清下游系统。LLM、RAG、Agent、多模态项目都继承了这个变化。 |
这已经足够支撑新人建立历史理解。公式细节可以等学到相关章节再看。
按课程主线查关键节点
Section titled “按课程主线查关键节点”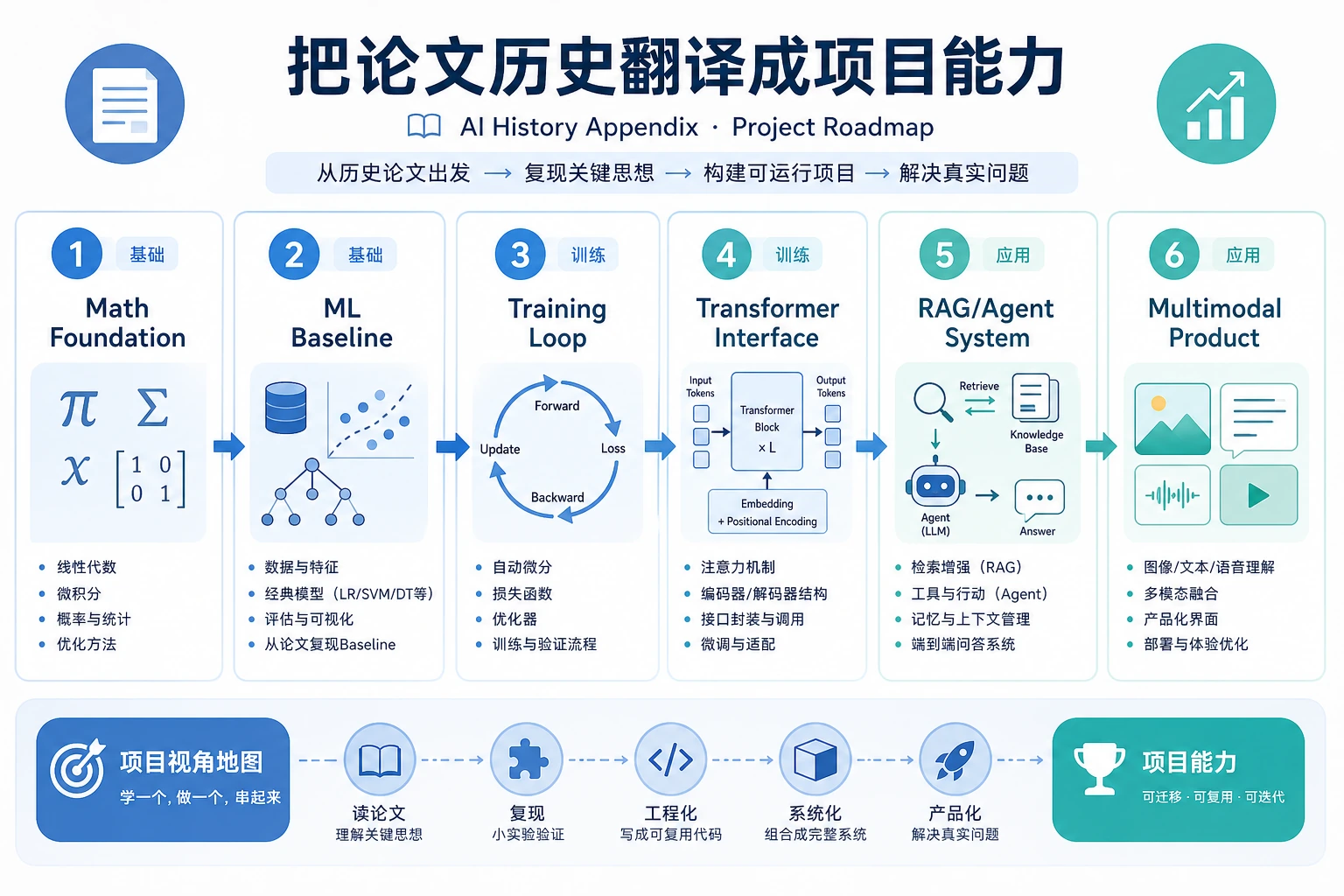
| 课程主线 | 先认识哪些节点 | 为什么重要 |
|---|---|---|
| 数学基础 | Bayes、Shannon、最大似然、EM | 概率、信息量和损失函数 |
| 经典机器学习 | CART、SVM、Random Forest、AdaBoost、XGBoost | 强基线和表格数据工程 |
| 神经网络 | Perceptron、XOR、Backpropagation、LSTM、AlexNet、ResNet | 理解深度、梯度、数据和算力为什么重要 |
| NLP 与大模型 | Word2Vec、Seq2Seq、Transformer、BERT、GPT、InstructGPT | 从词向量走向助手的路线 |
| RAG 与 Agent | RAG、Chain-of-Thought、ReAct、Toolformer | 外部知识、推理轨迹和工具调用 |
| 多模态 | CLIP、DDPM、Latent Diffusion、Whisper、SAM | 文本、图像、语音、视频和生成流水线 |
有些节点是具体论文,有些是算法族或历史转折点。没关系,真正有用的问题始终是:它让什么问题变容易了?
只在学到对应章节时再看这些图。每张分支图都按两个问题来读:旧瓶颈变成了什么,新内容应该回看哪一章?
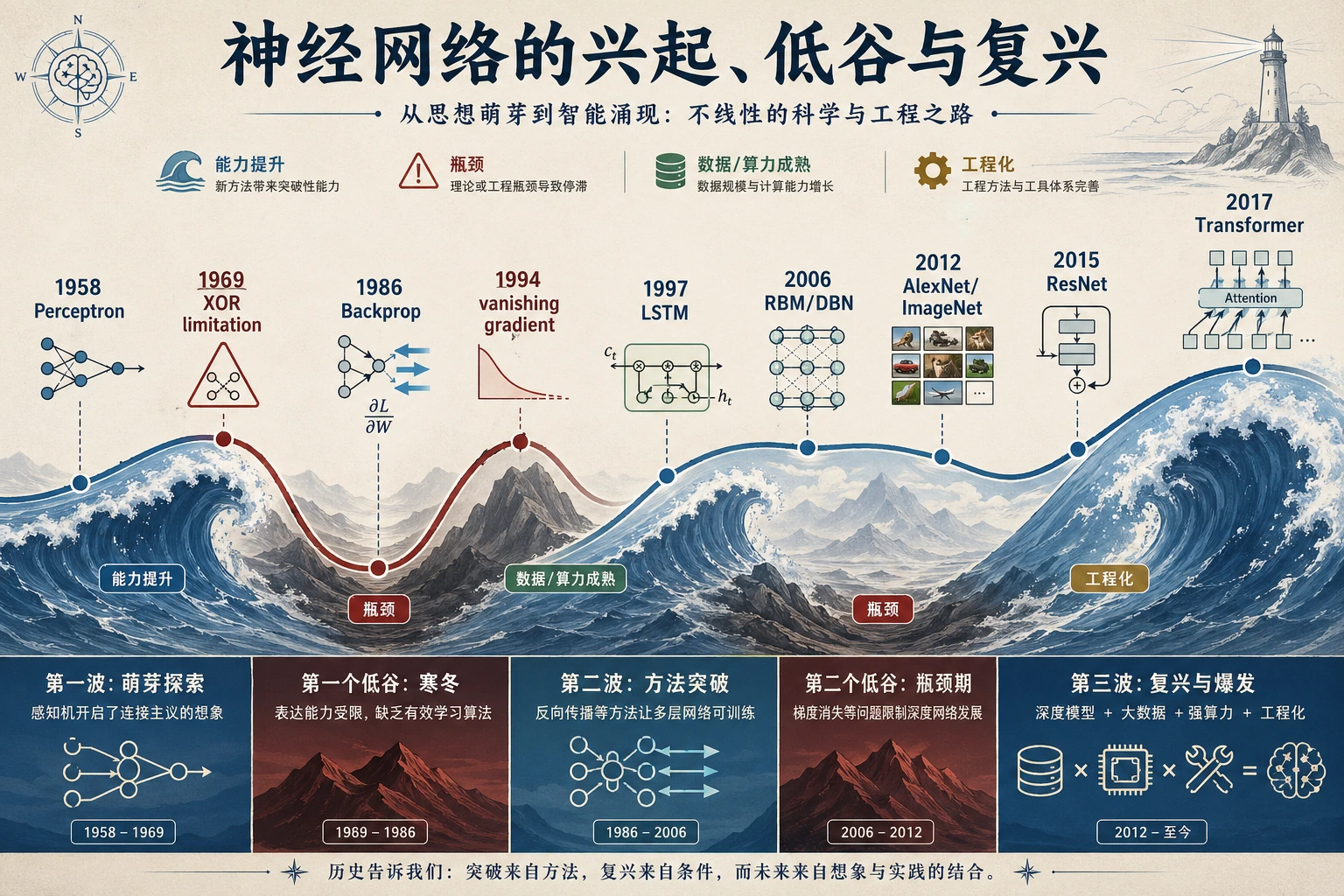
第 6、7 章遇到感知器、反向传播、CNN 或 Transformer 时,再看神经网络浪潮图。重点看热潮、低谷、数据和算力如何交替推动。
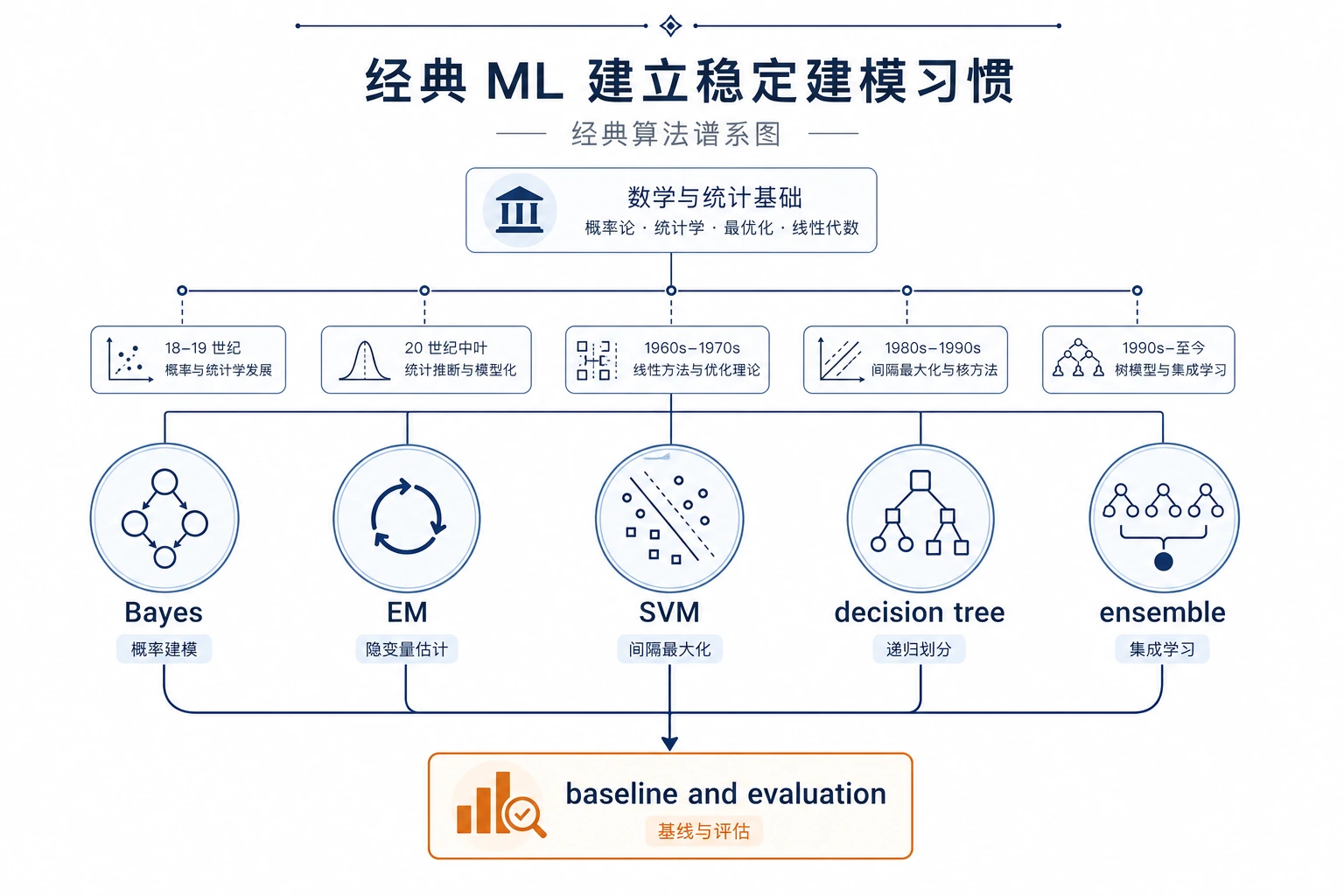
第 5 章遇到 SVM、树、森林、Boosting 或 XGBoost 时,看经典 ML 分支图。对比哪些方法解决边界问题,哪些方法依靠集成,哪些适合作为表格数据强基线。
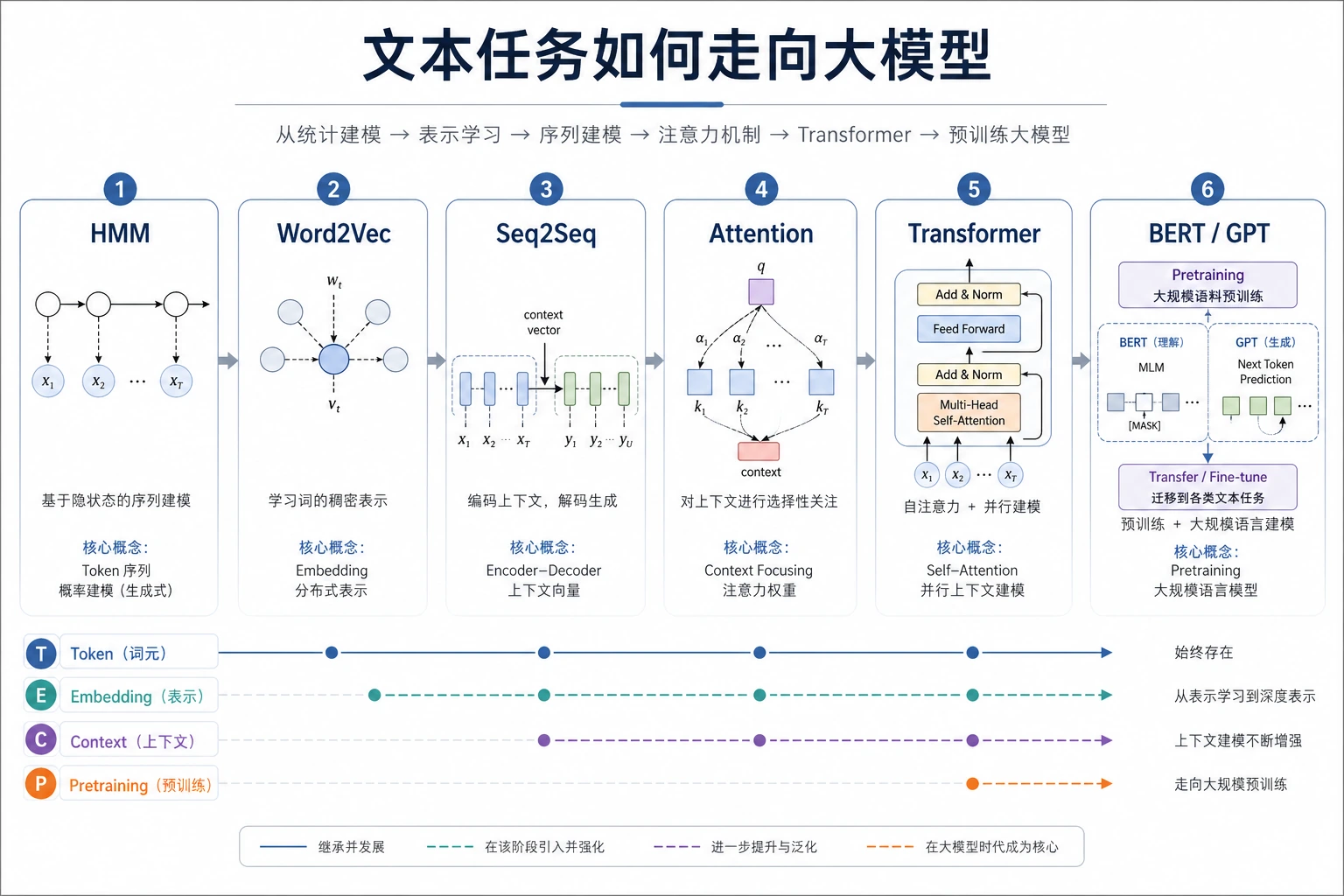
第 11 章学习分词、词向量、Seq2Seq、BERT 或 GPT 时,看 NLP 分支图。把它读成从词义表示走向指令助手的路线。
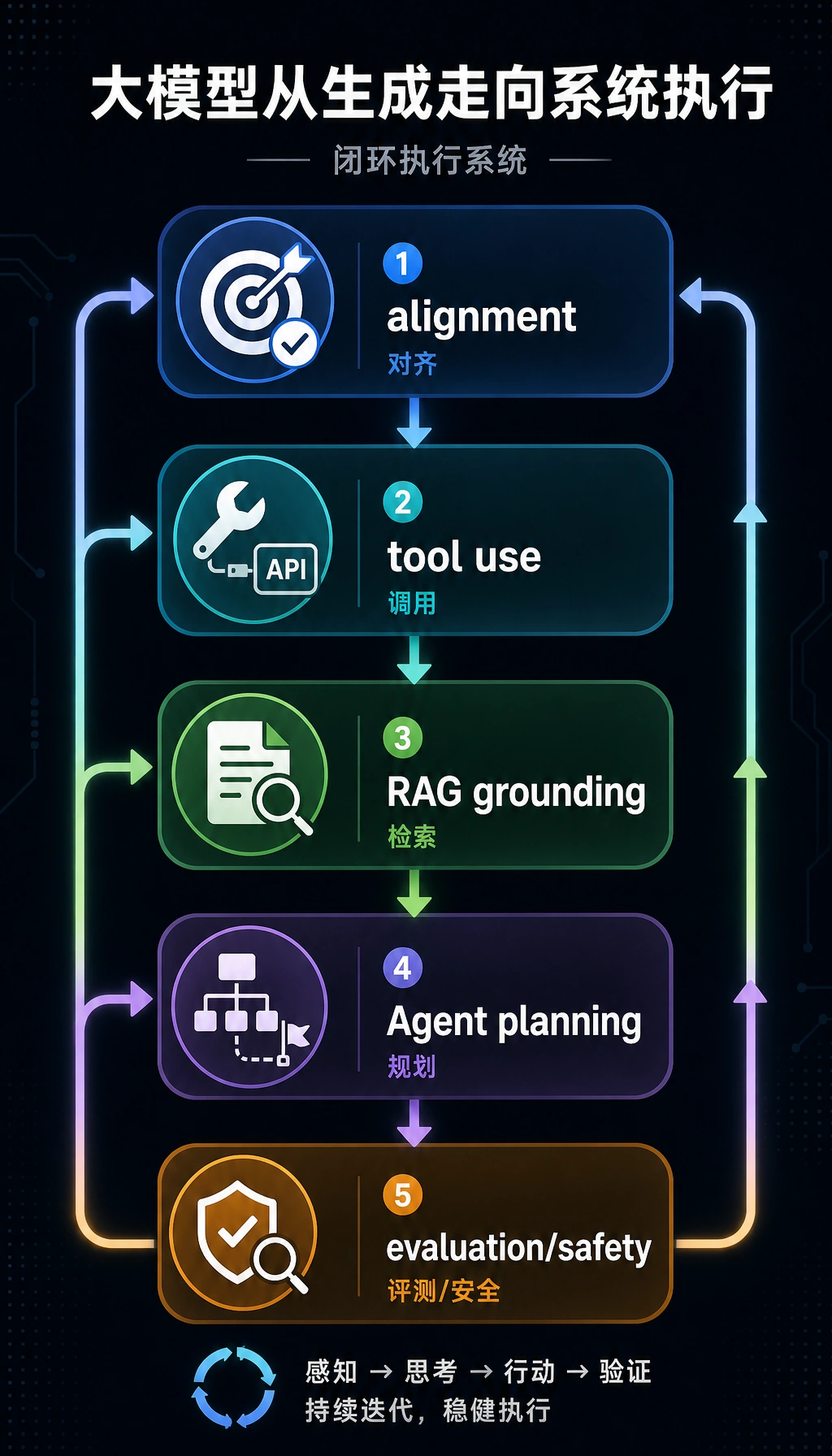
第 7-9 章讨论指令微调、RLHF、工具调用、trace 或部署时,看这张系统主线图。重点是模型质量和系统控制必须一起提升。
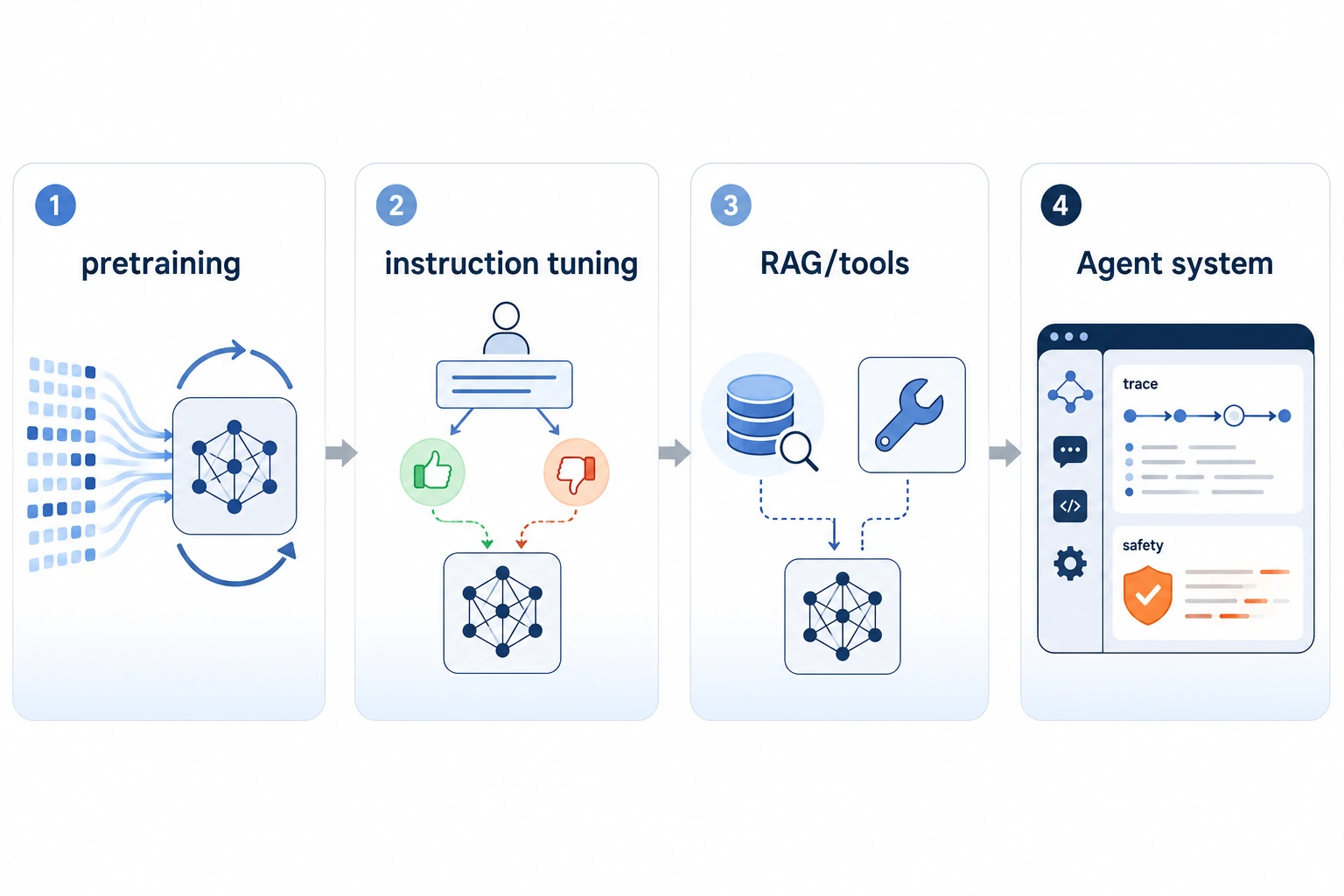
当你判断项目只需要 prompt、检索、工具,还是完整 Agent 循环时,看这张工程时间线。不要跳过 trace 和评估节点。
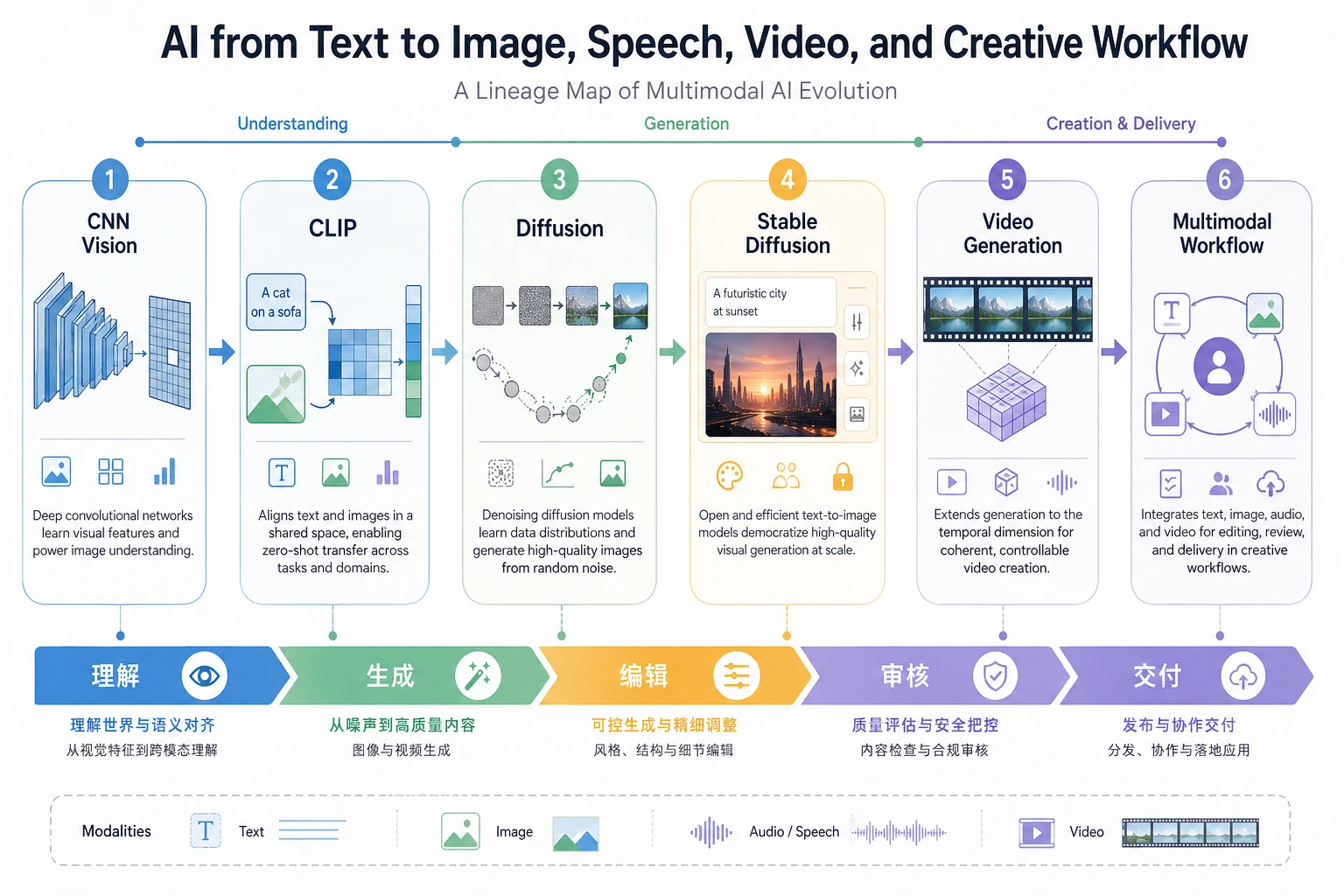
第 12 章学习多模态时,看这张分支图。沿着文本、图像、语音、分割模型如何变成生成流水线的可复用部件来读。
章节快速索引
Section titled “章节快速索引”| 如果你看到这个名字 | 回到哪里学 |
|---|---|
| Bayes、MLE、entropy、EM | 第 4 章数学基础 |
| SVM、Random Forest、XGBoost | 第 5 章机器学习 |
| Perceptron、backpropagation、CNN、LSTM、Transformer | 第 6 章深度学习 |
| GPT、RLHF、LoRA、instruction tuning | 第 7 章大模型原理 |
| RAG、vector retrieval、citations | 第 8 章 RAG |
| Chain-of-Thought、ReAct、Toolformer、tool use | 第 9 章 Agent |
| AlexNet、ResNet、YOLO、SAM | 第 10 章计算机视觉 |
| Word2Vec、Seq2Seq、BERT、GPT | 第 11 章 NLP |
| CLIP、diffusion、Whisper、多模态生成 | 第 12 章多模态 |
任选 3 个节点,用项目语言改写:
示例项目卡:
- 节点:
Attention Is All You Need - 旧瓶颈:RNN 不适合长序列和并行训练。
- 新方法:self-attention 成为序列建模主线。
- 影响项目:LLM、RAG、Agent、多模态模型。
- 应该回看:第 6、7、8、9 章。
目标不是背历史,而是把历史节点和你以后会做的真实能力连接起来。
项目交付参考与讲解
一种合格答案可以选这三个节点:
Backpropagation
- 旧瓶颈:多层神经网络很难有效训练。
- 新方法:梯度可以逐层向前面的层传播。
- 影响项目:图像分类、语言模型,以及几乎所有深度学习系统。
- 应该回看:第 6 章。
RAG
- 旧瓶颈:语言模型可以流畅回答,但不一定有外部证据支撑。
- 新方法:生成前先检索相关文档,把外部知识放进上下文。
- 影响项目:知识助手、政策问答、带引用的研究工具。
- 应该回看:第 8 章。
CLIP
- 旧瓶颈:图像模型和文本模型常常在不同表示空间里训练。
- 新方法:用对比学习把图像和文本对齐。
- 影响项目:图像搜索、多模态检索、图像生成引导。
- 应该回看:第 12 章。
好的答案会说明每个节点解决了什么瓶颈、方法上有什么变化、影响哪类项目、应该回到哪章复习。只罗列名词而不解释“什么变容易了”,就还不够。
学完这一页,至少保留这张证据卡:
- 时间线锚点
- 阶段、关键想法、代表性论文/系统,以及它为何重要
- 章节链接
- 这个里程碑帮助解释课程中的哪一章
- 记忆钩子
- 图示、漫画格,或一句话的历史转折
- 失败检查
- 只记住名称,却不理解每个里程碑解决了什么问题
- 期望产出
- 一份与至少一个项目决策相关的简短时间线说明