12.3.4 数字人技术【选修】
- 理解数字人系统最核心的模块组成
- 理解它为什么不只是“视频生成”
- 看懂一个最小数字人工作流
- 建立对数字人项目复杂度来源的正确直觉
先建立一张地图
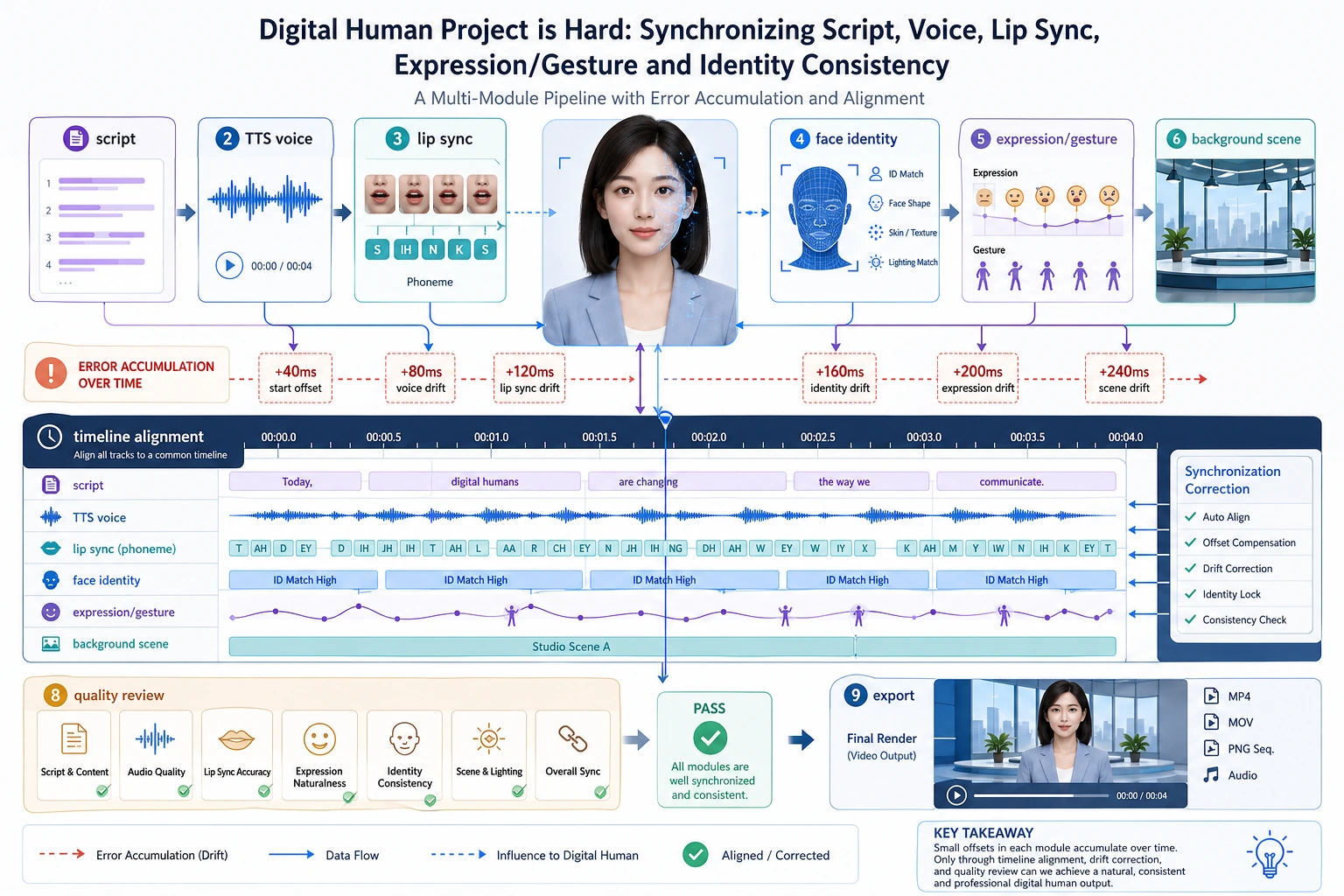
Section titled “先建立一张地图”数字人系统更适合按“文本 / 语音 / 口型 / 渲染”四层来理解:
flowchart LR A["文本或脚本"] --> B["语音生成"] B --> C["口型 / 面部动作驱动"] C --> D["头像 / 人物渲染"] D --> E["输出视频"]所以这节真正想解决的是:
- 为什么数字人不是单一模型问题
- 为什么它天然更像多模块协作系统
一、数字人到底在做什么?
Section titled “一、数字人到底在做什么?”最简单的理解
Section titled “最简单的理解”数字人系统通常想完成的是:
- 给定一段文字或语音
- 让一个虚拟人物“像真人一样”说出来
这听起来像视频生成,但为什么又不完全一样?
Section titled “这听起来像视频生成,但为什么又不完全一样?”因为数字人常常不只是要“生成一段视频”,还要保证:
- 说话内容对得上
- 口型对得上
- 人物身份稳定
- 表情和动作不太违和
也就是说,它比普通视频生成更强调:
人物一致性 + 语音驱动一致性。
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把数字人系统理解成:
- 一个虚拟主播制作流水线
文字像脚本, TTS 像配音, 口型同步像嘴部和表情驱动, 渲染则像最后把角色真正拍出来。
这个类比很适合新人,因为它会帮助你先抓住:
- 数字人不是“突然凭空生成一段视频”
- 而是多个模块一起把内容演成视频
二、数字人系统为什么本质上是“多模块管线”?
Section titled “二、数字人系统为什么本质上是“多模块管线”?”一个很粗的工作流通常会是:
- 文本生成或接收文本
- TTS 生成语音
- 根据语音驱动口型 / 面部动作
- 渲染虚拟形象
pipeline = ["text", "tts", "lip_sync", "avatar_render"]print(pipeline)预期输出:
['text', 'tts', 'lip_sync', 'avatar_render']可以把它当作检查清单。任何一环太弱,最终数字人都会显得不可信,即使其他环节都能跑通。

这个简单列表最重要的作用是让你看到:
数字人不是一个单一黑盒,而是一个链路系统。
一个很适合初学者先记的模块分工表
Section titled “一个很适合初学者先记的模块分工表”| 模块 | 最值得先记住的作用 |
|---|---|
| 文本 / 脚本 | 决定要说什么 |
| 语音生成 | 决定听起来像怎么说 |
| 口型驱动 | 决定嘴型是否跟得上 |
| 角色渲染 | 决定画面里这个人最终长什么样 |
这个表很适合新人,因为它会把数字人从“炫酷词汇”重新拆成几个比较具体的模块。
三、最关键的一步:口型同步(lip sync)
Section titled “三、最关键的一步:口型同步(lip sync)”为什么这是数字人体验的核心?
Section titled “为什么这是数字人体验的核心?”因为用户对“嘴型不对”极其敏感。 哪怕语音很好、人物也好看,只要口型明显对不上,整个系统就会显得很假。
这件事本质上在干什么?
Section titled “这件事本质上在干什么?”就是:
- 输入一段语音
- 预测对应的嘴部运动
它是数字人系统里非常典型的“音频驱动视觉”任务。
四、为什么数字人对“身份一致性”要求更高?
Section titled “四、为什么数字人对“身份一致性”要求更高?”在普通视频生成里,用户可能更在意画面整体。 而数字人通常会聚焦到一个核心主体:
- 同一张脸
- 同一个角色
- 同一个品牌形象
所以数字人任务天然对:
- 身份稳定
- 细节一致
要求更高。
这也是为什么很多数字人系统会非常重视:
- 专属角色建模
- 头像驱动
- 说话头(talking head)控制
五、一个最小“数字人系统状态”示意
Section titled “五、一个最小“数字人系统状态”示意”digital_human_request = { "text": "欢迎来到 AI 全栈课程。", "speaker": "female_01", "avatar": "teacher_avatar_v1", "style": "formal"}
print(digital_human_request)预期输出:
{'text': '欢迎来到 AI 全栈课程。', 'speaker': 'female_01', 'avatar': 'teacher_avatar_v1', 'style': 'formal'}这个请求已经不只是文本:它同时固定了声音、头像和呈现风格,才能把同一段内容稳定演成同一个角色。
这个例子在教你:
- 输入不只是文本
- 系统还需要角色、语音风格和表现方式
这就是数字人项目为什么天然更像“产品系统”,而不是单一模型演示。
六、一个更完整的工作流直觉
Section titled “六、一个更完整的工作流直觉”假设一条数字人视频的生成过程可以粗略写成:
- 文本 -> 语音
- 语音 -> 嘴型 / 面部动作
- 人物模板 + 动作 -> 视频帧
workflow = { "input_text": "欢迎来到 AI 全栈课程。", "audio": "generated_speech.wav", "face_motion": "lip_sync_features", "output_video": "teacher_avatar_video.mp4"}
print(workflow)预期输出:
{'input_text': '欢迎来到 AI 全栈课程。', 'audio': 'generated_speech.wav', 'face_motion': 'lip_sync_features', 'output_video': 'teacher_avatar_video.mp4'}视频只是最后产物,不是整个系统。在视频出现之前,流程已经生成了语音和动作特征,而且这些特征必须保持同步。
这段代码不是在实现数字人,而是在帮你抓住一个重要事实:
数字人是“文本、语音、视觉渲染”的多级转换系统。
一个很适合初学者先记的项目检查表
Section titled “一个很适合初学者先记的项目检查表”| 你最该先检查什么 | 为什么重要 |
|---|---|
| 语音自然不自然 | 声音会直接影响拟人感 |
| 口型是否跟上 | 用户对嘴型错位极敏感 |
| 角色是否稳定 | 身份不稳会很出戏 |
| 风格是否一致 | 语音、人物、文案不能像三套系统 |
这个表很适合新人,因为它会帮助你把“数字人看起来怪怪的”重新拆成几个可定位的问题。
七、为什么数字人项目很容易比想象中更难?
Section titled “七、为什么数字人项目很容易比想象中更难?”模块之间的误差会层层叠加
Section titled “模块之间的误差会层层叠加”例如:
- 文本生成不自然
- TTS 语音生硬
- 口型同步偏一点
- 表情再不协调一点
最后整体观感就会很差。
用户对人脸天然更敏感
Section titled “用户对人脸天然更敏感”人对“人脸”和“说话嘴型”的错位非常敏感, 这使得数字人项目经常比普通生成任务更难过关。
八、数字人为什么很有产品价值?
Section titled “八、数字人为什么很有产品价值?”因为它非常适合:
- 教学讲解
- 客服导览
- 营销主持
- 多语言讲解
它的价值往往不在于“技术炫酷”,而在于:
能把语言内容包装成更有临场感的表达形式。
九、一个很重要的工程判断
Section titled “九、一个很重要的工程判断”很多数字人产品并不是追求“完全逼真”,而是追求:
- 足够稳定
- 足够自然
- 足够低成本
这很重要,因为一味追求超高拟真度,成本和复杂度会迅速上升。
所以现实里你经常会看到:
- 卡通风 avatar
- 半写实形象
- 轻量 talking head
这背后很多时候是工程与产品取舍。
如果把它做成项目或系统设计,最值得展示什么
Section titled “如果把它做成项目或系统设计,最值得展示什么”最值得展示的通常不是:
- “我做了一个数字人视频”
而是:
- 文本如何进入工作流
- 语音、口型、渲染分别由什么模块负责
- 哪些地方最容易失真
- 你是怎样在稳定性、成本和拟真度之间取舍的
这样别人会更容易看出:
- 你理解的是数字人系统工程
- 不只是视频生成演示
学完这一页,至少保留这张证据卡:
- 分镜脚本
- 场景列表、时长、镜头/语音/字幕/时间备注
- 资源列表
- 图像、音频、语音、字幕、片段和来源/许可证字段
- 同步检查
- 语音-文本时序、口型同步、镜头连续性或帧一致性
- 失败检查
- 闪烁、身份漂移、音频不匹配、不安全相似度或导出问题
- 期望产出
- 带复查说明的分镜或时间线产物
这一节最重要的不是记住“数字人”三个字,而是理解:
数字人系统本质上是一个把文本、语音、动作和人物渲染组合起来的多模块系统。
真正难的地方,不只是生成视频,而是让这些模块最后看起来像一个统一、可信的人物表现。
- 用自己的话解释:为什么数字人不能简单看成“普通视频生成”?
- 想一想:在数字人系统里,为什么口型同步会特别关键?
- 如果你要做一个教育类虚拟讲师,哪些模块是必不可少的?
- 用自己的话说明:为什么很多数字人产品更看重“稳定和成本”,而不是极致拟真?
解题思路与讲解
- 数字人结合了生成、身份控制、语音、面部动作、唇形同步、交互状态和安全控制。普通视频生成不一定需要作为一个稳定人格持续回应用户。
- 唇形同步特别关键,因为人类很容易察觉口型和声音不一致。很小的不匹配都会让角色显得虚假,并降低信任感。
- 教育虚拟讲师至少需要脚本或对话生成、TTS、形象渲染、唇形同步、课程状态、检索或课程内容 grounding、安全评审,以及学习进度分析。
- 稳定性和成本重要,是因为数字人常常用于长时间、重复使用的场景。略微不那么逼真但可靠、可负担的系统,比昂贵且不稳定的系统更容易落地。