3.3.4 数据选择与过滤
- 掌握
loc(标签索引)和iloc(位置索引) - 学会使用布尔索引进行条件过滤
- 掌握
query()方法 - 学会多条件组合筛选
先建立一张地图
Section titled “先建立一张地图”数据选择与过滤更适合按“我要选谁”来理解:
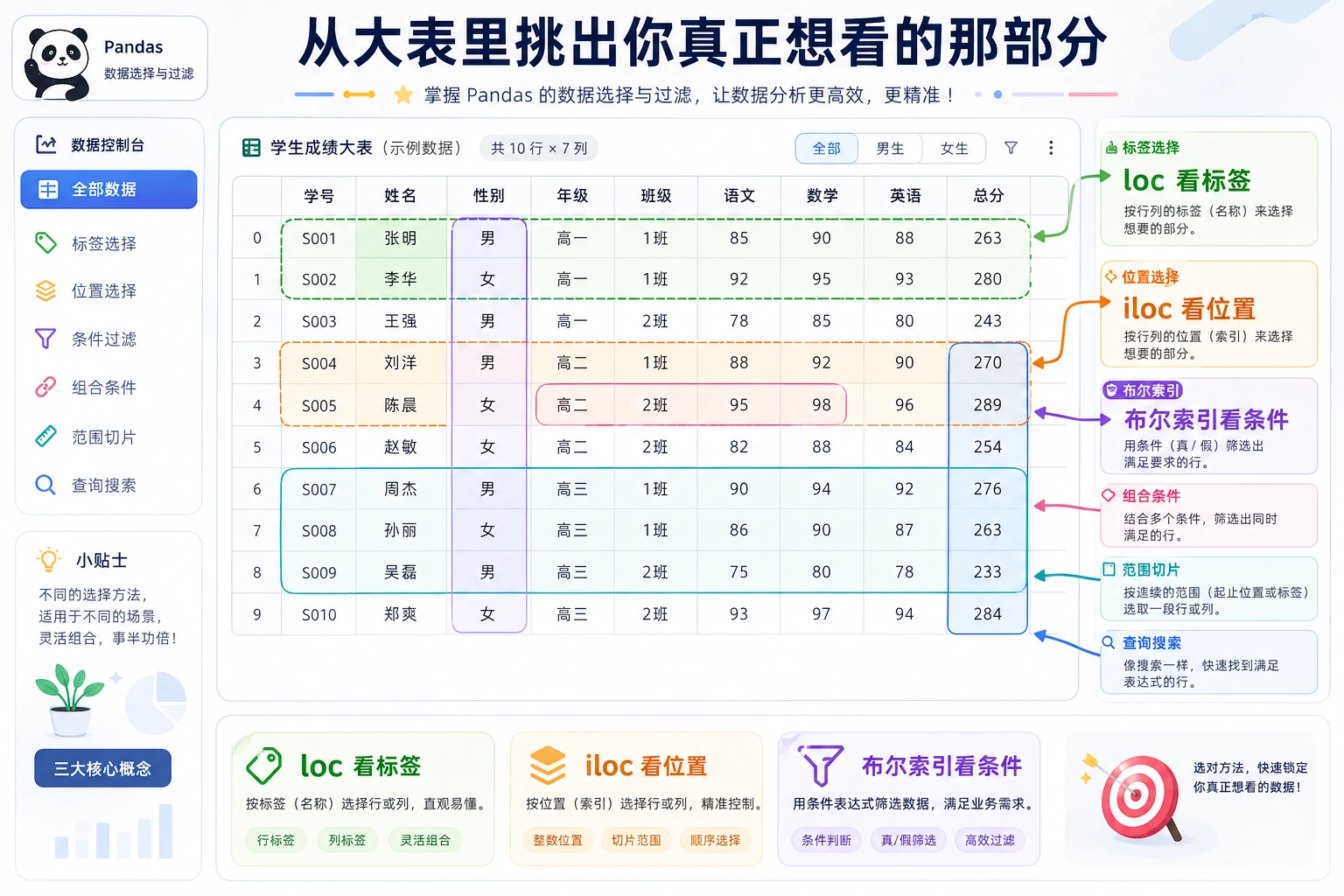
所以这节真正想解决的是:
- 不同场景下到底该先想到
loc、iloc还是布尔索引 - 为什么很多
Pandas题的第一步都是“先把要看的数据选出来”
准备示例数据
Section titled “准备示例数据”import pandas as pdimport numpy as np
df = pd.DataFrame({ "姓名": ["张三", "李四", "王五", "赵六", "钱七", "孙八"], "年龄": [22, 28, 25, 35, 21, 30], "部门": ["技术", "市场", "技术", "管理", "技术", "市场"], "薪资": [15000, 18000, 22000, 35000, 12000, 20000], "入职年份": [2023, 2020, 2021, 2018, 2024, 2019]})print(df)一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把这一节理解成:
- 在一张很大的表里找你真正要看的那几行几列
也就是说,这节最核心的不是“写法多”,而是:
- 先搞清你是按名字找
- 还是按位置找
- 还是按条件筛
loc:标签索引
Section titled “loc:标签索引”loc 用标签(名称) 来定位数据,格式:df.loc[行标签, 列标签]
第一次学 loc,最该先记什么?
Section titled “第一次学 loc,最该先记什么?”最值得先记的是:
loc是按“名字和标签”在选。
也就是说,它更像:
- 我知道我要哪一列、哪一段标签范围
# 取单行print(df.loc[0]) # 第一行(标签为 0 的行)
# 取多行print(df.loc[0:2]) # 标签 0 到 2(包含 2!)
# 取特定行和列print(df.loc[0, "姓名"]) # "张三"print(df.loc[0:2, "姓名"]) # 前 3 行的姓名print(df.loc[0:2, ["姓名", "薪资"]]) # 前 3 行的姓名和薪资
# 取所有行的某些列print(df.loc[:, ["姓名", "年龄"]])
# 条件筛选(最常用!)print(df.loc[df["年龄"] > 25]) # 年龄大于 25 的所有行iloc:位置索引
Section titled “iloc:位置索引”iloc 用位置(整数) 来定位数据,和 Python 列表的切片规则一致:
第一次学 iloc,最该先记什么?
Section titled “第一次学 iloc,最该先记什么?”最值得先记的是:
iloc是按“第几行第几列”在选。
所以它更像:
- 你拿着坐标去表里取值
# 取单行print(df.iloc[0]) # 第一行
# 取多行(不包含末尾!和 Python 一致)print(df.iloc[0:3]) # 第 0、1、2 行
# 取特定位置print(df.iloc[0, 0]) # 第 0 行第 0 列 → "张三"print(df.iloc[0:3, 0:2]) # 前 3 行、前 2 列print(df.iloc[[0, 2, 4]]) # 第 0、2、4 行
# 取最后一行print(df.iloc[-1])loc vs iloc 对比
Section titled “loc vs iloc 对比”| 特性 | loc | iloc |
|---|---|---|
| 索引方式 | 标签(名称) | 位置(整数) |
| 切片末尾 | 包含 | 不包含 |
| 示例 | df.loc[0:2] → 3 行 | df.iloc[0:2] → 2 行 |
| 条件筛选 | ✅ 支持 | ❌ 不支持 |
一个很适合初学者先记的选择表
Section titled “一个很适合初学者先记的选择表”| 你的想法 | 更稳的第一反应 |
|---|---|
| 我知道列名或标签 | loc |
| 我只知道第几行第几列 | iloc |
| 我要按某个条件筛人或筛订单 | 布尔索引 |
| 条件很长、想写得更像一句话 | query() |
这个表很适合新人,因为它会把“到底用哪个”直接变成一个可判断的问题。
布尔索引:条件筛选
Section titled “布尔索引:条件筛选”这是数据分析中使用最频繁的操作:
为什么布尔索引这么重要?
Section titled “为什么布尔索引这么重要?”因为真实分析题里你最常做的事情往往就是:
- 找出金额大于某值的订单
- 找出某部门的人
- 找出满足两三个条件的子集
也就是说,很多分析真正开始的第一步,就是:
- 先筛出你要分析的那部分数据
# 薪资大于 20000 的员工high_salary = df[df["薪资"] > 20000]print(high_salary)
# 部门是"技术"的员工tech = df[df["部门"] == "技术"]print(tech)
# 年龄不等于 22 的员工print(df[df["年龄"] != 22])# 技术部门且薪资大于 15000(用 & 表示 AND)result = df[(df["部门"] == "技术") & (df["薪资"] > 15000)]print(result)
# 技术部门或管理部门(用 | 表示 OR)result = df[(df["部门"] == "技术") | (df["部门"] == "管理")]print(result)
# 取反(用 ~ 表示 NOT)result = df[~(df["部门"] == "技术")] # 非技术部门print(result)isin:匹配多个值
Section titled “isin:匹配多个值”# 部门在 ["技术", "市场"] 中的员工result = df[df["部门"].isin(["技术", "市场"])]print(result)
# 反向:不在这些部门中result = df[~df["部门"].isin(["技术", "市场"])]print(result)between:范围筛选
Section titled “between:范围筛选”# 年龄在 22~30 之间(包含两端)result = df[df["年龄"].between(22, 30)]print(result)# 姓名包含"三"result = df[df["姓名"].str.contains("三")]
# 姓名以"张"开头result = df[df["姓名"].str.startswith("张")]第一次做筛选题时,最稳的默认顺序
Section titled “第一次做筛选题时,最稳的默认顺序”更稳的顺序通常是:
- 先问自己按标签选、按位置选,还是按条件筛
- 条件简单时先用布尔索引
- 条件很长时再考虑
query() - 最后再组合取列和取行
这样会比一上来就把几种写法混着用更不容易乱。
query() 方法
Section titled “query() 方法”query() 让你用更接近自然语言的方式筛选数据:
# 等价于 df[df["薪资"] > 20000]result = df.query("薪资 > 20000")print(result)
# 多条件result = df.query("部门 == '技术' and 薪资 > 15000")print(result)
# 用变量min_salary = 20000result = df.query("薪资 > @min_salary") # @引用外部变量print(result)
# 范围查询result = df.query("22 <= 年龄 <= 30")print(result)选择特定数据的方法总结
Section titled “选择特定数据的方法总结”flowchart TD A["我要选什么?"] --> B{"按行还是按列?"} B -->|"按列"| C["df['列名'] 或 df[['列1','列2']]"] B -->|"按行"| D{"用什么定位?"} D -->|"标签"| E["df.loc[标签]"] D -->|"位置"| F["df.iloc[位置]"] D -->|"条件"| G["df[条件] 或 df.query()"] B -->|"行和列"| H["df.loc[行, 列] 或 df.iloc[行, 列]"]一个新人可直接照抄的数据选择检查表
Section titled “一个新人可直接照抄的数据选择检查表”第一次做 Pandas 筛选题时,最稳的检查表通常是:
- 我是想选列、选行,还是同时选行和列?
- 我是按标签、按位置,还是按条件?
- 条件有没有加括号?
- 结果是不是我以为的那几行几列?
这 4 个问题答清楚后,很多筛选题都会顺很多。
实战:数据筛选
Section titled “实战:数据筛选”import pandas as pdimport numpy as np
# 创建一份电商订单数据rng = np.random.default_rng(seed=42)n = 100orders = pd.DataFrame({ "订单ID": range(1001, 1001 + n), "客户": rng.choice(["Alice", "Bob", "Charlie", "Diana", "Eve"], n), "商品类别": rng.choice(["电子", "服装", "食品", "图书"], n), "金额": rng.integers(10, 500, n), "数量": rng.integers(1, 10, n), "是否退货": rng.choice([True, False], n, p=[0.1, 0.9])})
# 查看数据print(orders.head(10))print(orders.info())
# 筛选练习# 1. 金额大于 300 的订单print(orders[orders["金额"] > 300])
# 2. Alice 购买的电子产品print(orders.query("客户 == 'Alice' and 商品类别 == '电子'"))
# 3. 未退货且金额前 10 的订单not_returned = orders[~orders["是否退货"]]top10 = not_returned.nlargest(10, "金额")print(top10[["订单ID", "客户", "金额"]])练习 1:基本筛选
Section titled “练习 1:基本筛选”# 用上面的 orders 数据# 1. 找出所有退货的订单# 2. 找出金额在 100~200 之间的订单数量# 3. 找出购买"图书"或"食品"类别的订单# 4. 找出 Bob 的非退货订单的平均金额练习 2:综合筛选
Section titled “练习 2:综合筛选”# 1. 每个客户的最大订单金额是多少?(提示:先筛选再统计)# 2. 哪些客户有退货记录?# 3. 金额排名前 5% 的订单有哪些?(提示:用 quantile)参考实现与讲解
- 每个条件先写成布尔 mask,再用
&、|和括号组合。例如金额区间、类别是否属于某集合、是否未退货,都可以先拆成命名 mask。 - 客户分组问题如果写明“未退货订单”,就先筛选再按
Customer分组,计算均值、最大值或次数。 - Top 百分比问题先用
quantile算阈值,再筛出超过阈值的记录,并同时报告阈值和结果行。这样截断标准可以被审计。
学完这一页,至少保留这张证据卡:
- 数据框状态
- 列、数据类型、行数、缺失值和样本行
- 操作
- 读/写、select/filter、清洗、转换、groupby、merge,或时间序列步骤
- 输出
- 结果表、保存的文件、聚合、连接结果,或时间索引视图
- 失败检查
- dtype 不匹配、缺失数据、重复键、链式赋值或时间频率错误
- 期望产出
- 前后对比表格样本,以及转换原因
这节最该带走什么
Section titled “这节最该带走什么”loc按标签,iloc按位置,布尔索引按条件- 很多真实分析题,第一步都不是算,而是先筛
- 先把“我要选谁”想清楚,再写代码,会比死记写法更稳