10.2.1 图像分类路线图:图像输入、标签输出
图像分类回答一个问题:给定一整张图,它最像哪个类别?
先看分类闭环
Section titled “先看分类闭环”
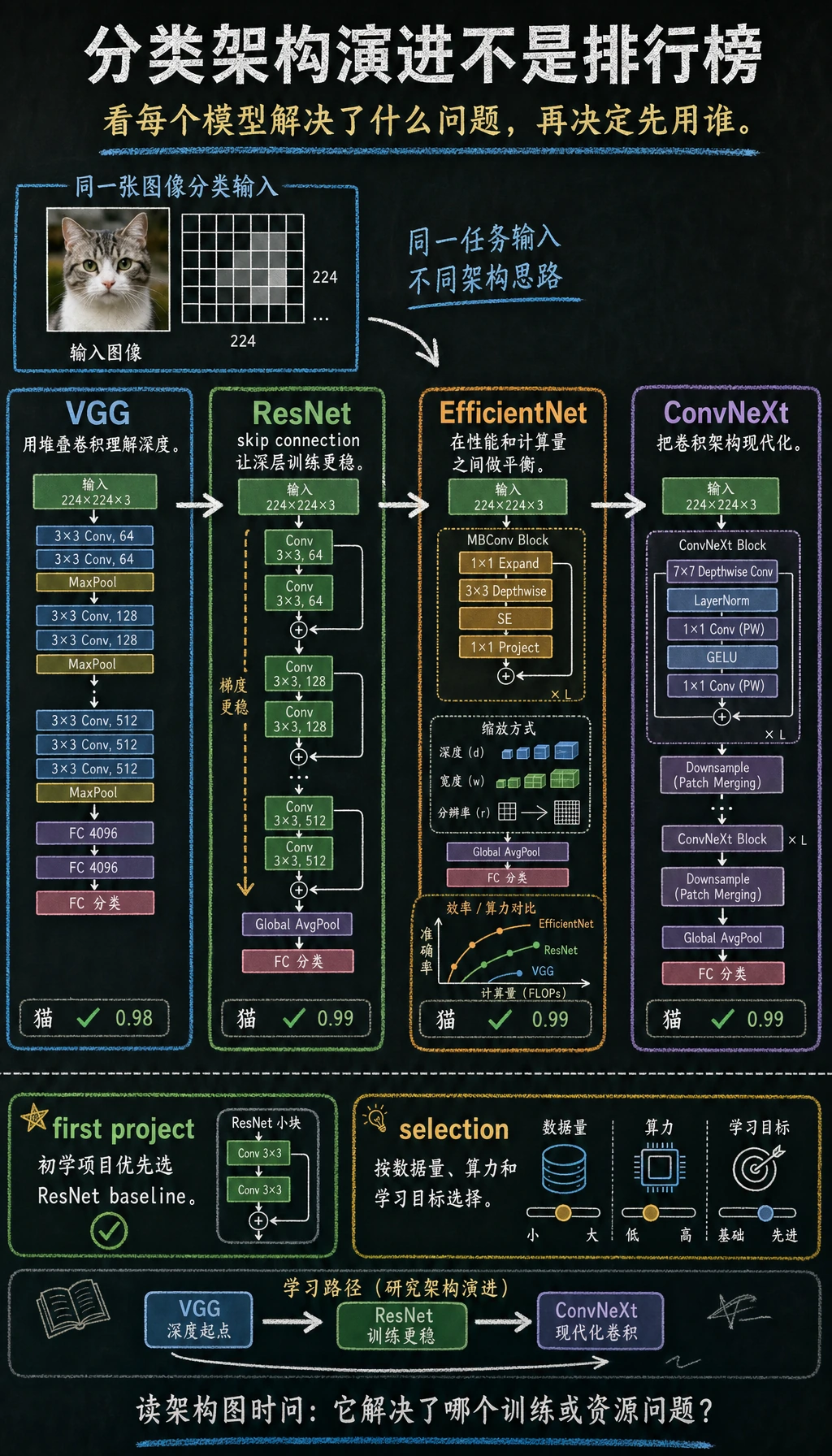

分类是最简单的视觉输出,但它仍然依赖数据划分、增强、架构、loss、指标和错误样例。
跑一个预测检查
Section titled “跑一个预测检查”这个脚本模拟分类器最后一步:选择分数最高的标签。
labels = ["cat", "dog", "panda"]scores = [0.12, 0.74, 0.14]
best_index = max(range(len(scores)), key=lambda index: scores[index])
print("prediction:", labels[best_index])print("confidence:", scores[best_index])预期输出:
prediction: dogconfidence: 0.74真实项目里不要只展示 top class。保留 confidence、错误样例和混淆模式。
按这个顺序学
Section titled “按这个顺序学”| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | 数据增强 | 解释哪些变化保持类别,哪些变化会带来风险 |
| 2 | 现代架构 | 比较特征提取器、分类头和预训练 backbone |
| 3 | 训练技巧 | 追踪划分、loss、accuracy、过拟合和错误样例 |
如果你能运行一个最小分类器,展示训练/验证指标,并解释至少一张失败图片,就通过了本章。
检查思路与讲解
- 合格答案要把任务映射到正确的视觉输出:类别标签、检测框、mask、OCR 文本、embedding 或视频事件。
- 证据应包含渲染后的视觉产物,以及一个指标或定性错误说明。
- 自检时要能指出一个视觉失败模式,例如类别混淆、漏检、mask 边界差、光照变化、领域偏移或标注质量弱。
学完这一页,至少保留这张证据卡:
- 数据集划分
- 训练/测试图像、类别名和类别平衡
- 预测
- 标签、置信度和至少一张分类错误的图像
- 指标
- 准确率、F1、混淆矩阵和类别级错误
- 失败检查
- 增强改变标签含义、类别不平衡、数据泄漏或过拟合
- 期望产出
- 模型结果表和保存的错误示例