9.0 学习检查表:AI Agent 与智能体系统
这页当成可打印检查表使用。需要完整讲解时,回到 第 9 章入口页。
两小时快速通读
Section titled “两小时快速通读”| 时间 | 做什么 | 能说出这句话就停 |
|---|---|---|
| 20 分钟 | 看入口页的执行闭环 | “Agent 是 goal-state-tool-observation 循环。” |
| 25 分钟 | 运行 追踪 脚本 | “我能回放每个动作和观察。” |
| 25 分钟 | 浏览 9.1 和 9.2 | “我能区分 Agent、工作流、RAG、ReAct、Plan-and-Execute。” |
| 25 分钟 | 浏览 9.3 工具安全 | “工具 结构约束 和权限比花哨 Prompt 更重要。” |
| 25 分钟 | 阅读边界选择图 | “我知道什么时候不该用 Agent。” |
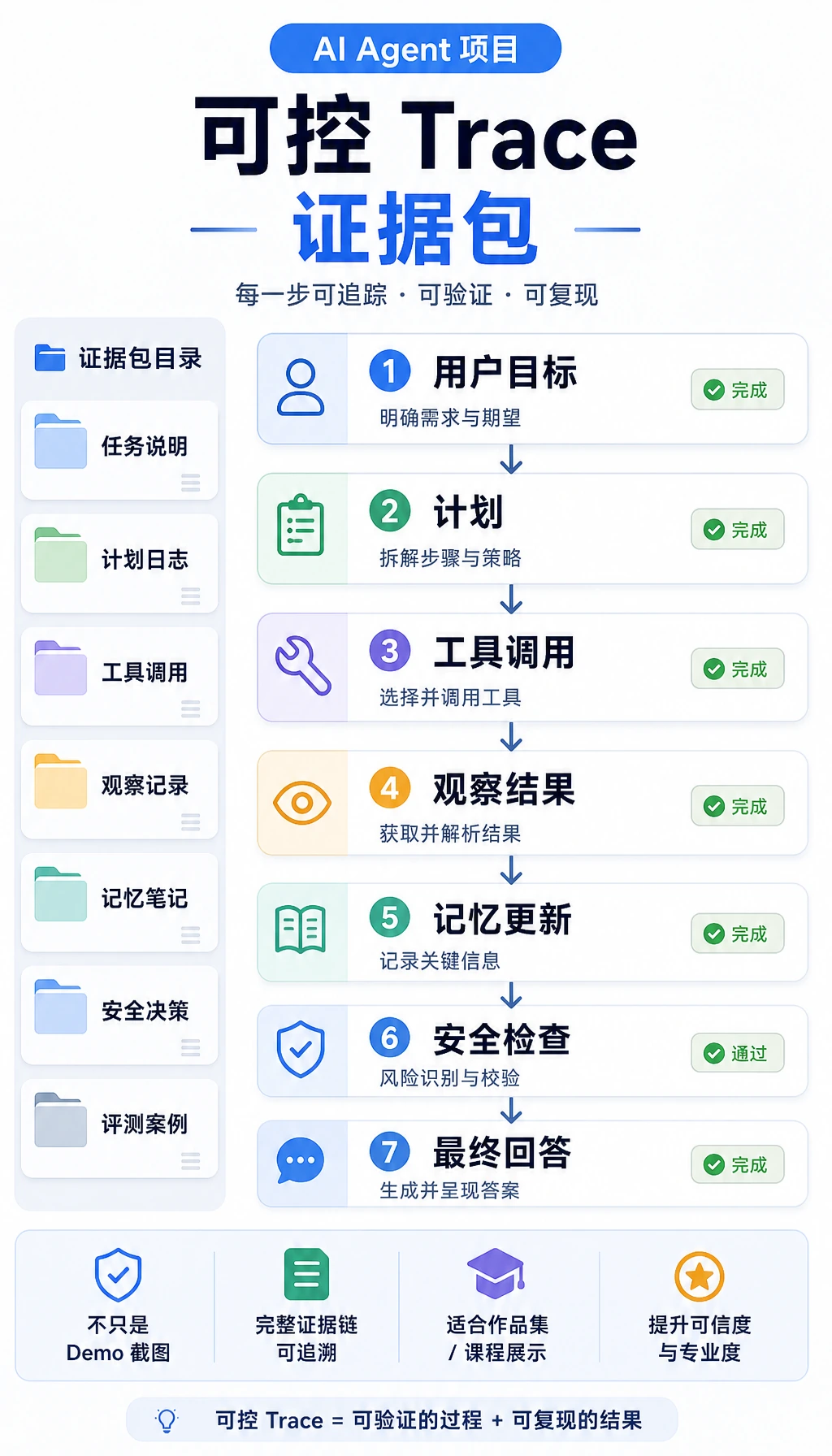
必须留下的证据
Section titled “必须留下的证据”| 证据 | 最小版本 |
|---|---|
tools_schema.md | 1~2 个工具,写清名称、用途、参数、返回值、错误和风险等级 |
agent_traces.jsonl | 至少三次运行,记录 goal、步骤、action、input、observation、result |
safety_boundary.md | 最大步数、工具白名单、被拦截动作、人工确认规则 |
protocol_card.md | MCP/server 能力、peer-agent 交接字段、授权规则、trace 字段 |
agent_sandbox_trace.json | allow/confirm/deny 决策,并至少包含一个被阻止的 injection 或 tool-poisoning 样本 |
failure_cases.md | 至少三个失败:选错工具、参数错误、循环、权限拦截、不支持的回答 |
eval_tasks.csv | 3~5 个固定任务,包含期望结果和成功标准 |
README.md | 运行命令、追踪 示例、安全样例、评估结果、限制 |
| 闸门 | 通过条件 |
|---|---|
| 工具 结构约束 | 每个工具都有用途、参数、返回值、错误和风险等级。 |
| 轨迹回放(追踪回放) | 评审者可以回放每次工具调用为什么发生。 |
| 安全边界 | 白名单外或高风险动作会被拦截,或转入人工确认。 |
| 停止控制 | 最大步数和停止条件能防止循环与成本失控。 |
预期结果:你的第 9 章项目文件夹里有工具 schema、可回放 trace、安全边界、固定评测任务、失败笔记,以及说明为什么在闭环可靠前保持单 Agent 的 README。
- 你能说明 Agent 和普通 LLM 应用的区别吗?
- 你能展示一条 追踪,并解释每次工具调用为什么发生吗?
- 你能拦截高风险或不在白名单里的工具吗?
- 你能把工具发现、授权和 Agent 交接分开吗?
- 你能定义停止条件和最大步数吗?
- 你能解释为什么多 Agent 应该在单 Agent 可靠之后再做吗?
检查思路与讲解
- Agent 会维持 goal-plan-tool-observation 的闭环,所以系统不只是生成一句回答,而是能执行、观察结果并决定下一步。
- 有用的 trace 应该包含 goal、plan step、tool call、input、observation,以及为什么下一步会由这个 observation 触发。
- 可以通过 tool allowlist、schema 检查、risk label、最大步数和必要时的人类审批,来拦截高风险或不在白名单里的工具。
- 好的停止条件包括成功、没有进展、达到最大步数,或者风险升级。
- 先把单 Agent 做稳定,是因为多 Agent 更难追踪、更难调试,也更难安全控制。
如果答案都是可以,就继续下一方向:部署、多模态 Agent,或课程最终项目。
学完这一页,至少保留这张证据卡:
- 单代理 trace
- 一个完整的目标-计划-行动-观察循环
- 工具契约
- schema、权限、错误行为和观察
- 记忆笔记
- 写入、检索、遗忘或更新了什么
- 评估备注
- 成功分数、安全检查和失败原因
- 项目说明
- 运行命令、trace、限制,以及下一步动作