6.2.4 Autograd 自动求导
- 解释
requires_grad=True改变了什么。 - 运行
loss.backward()并检查.grad。 - 理解
backward()只计算梯度,不更新参数。 - 用
zero_grad()避免梯度累积 bug。 - 在正确位置使用
torch.no_grad()和detach()。
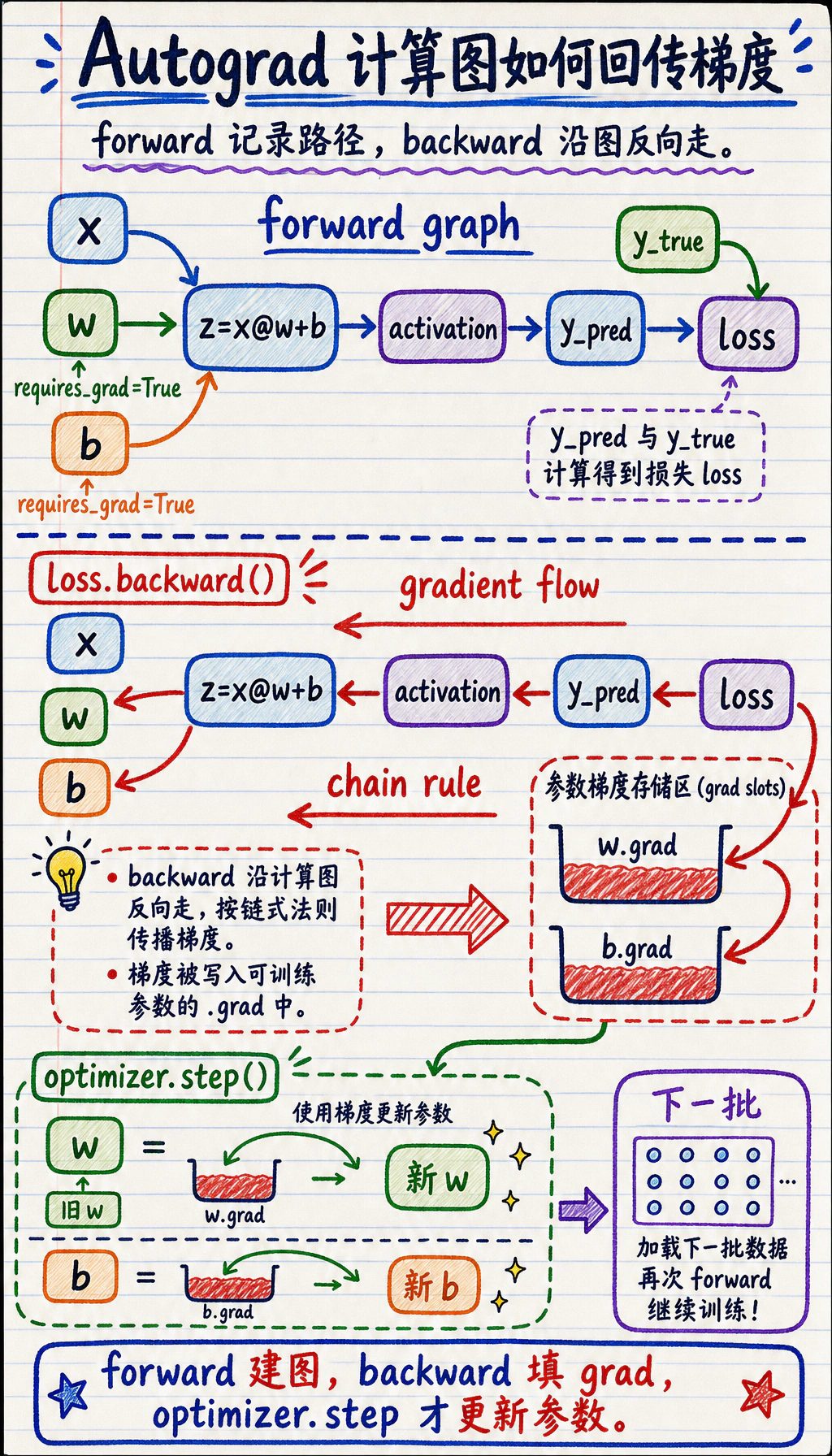
按这个顺序读图:
参数前向运算lossbackward()parameter.gradoptimizer step
Autograd 会记录产生 loss 的运算。当你调用 backward() 时,PyTorch 会沿着记录下来的图反向走,并应用链式法则。
实验 1:一个参数,一个梯度
Section titled “实验 1:一个参数,一个梯度”先从一个数字开始,机制最清楚。
import torch
w = torch.tensor(2.0, requires_grad=True)loss = (w * 3 - 10) ** 2
print("loss:", loss.item())loss.backward()print("w.grad:", w.grad.item())预期输出:
loss: 16.0w.grad: -24.0发生了什么:
w因为requires_grad=True,所以是可学习值。loss由w计算得到,PyTorch 会记录从w到loss的路径。loss.backward()会计算w改变时 loss 怎么变。- 结果存进
w.grad。
计算链是:
ww * 3w * 3 - 10squareloss
实验 2:梯度不是更新
Section titled “实验 2:梯度不是更新”backward() 只计算梯度。你仍然需要更新步骤。
import torch
w = torch.tensor(2.0, requires_grad=True)lr = 0.1
print("single_parameter_training")for step in range(1, 6): loss = (w * 3 - 10) ** 2 loss.backward()
with torch.no_grad(): w -= lr * w.grad
print( f"step={step} " f"w={w.item():.4f} " f"loss={loss.item():.4f} " f"grad={w.grad.item():.4f}" )
w.grad.zero_()预期输出:
single_parameter_trainingstep=1 w=4.4000 loss=16.0000 grad=-24.0000step=2 w=2.4800 loss=10.2400 grad=19.2000step=3 w=4.0160 loss=6.5536 grad=-15.3600step=4 w=2.7872 loss=4.1943 grad=12.2880step=5 w=3.7702 loss=2.6844 grad=-9.8304数值来回跳,是因为这个小函数里 lr=0.1 稍微激进。这个现象很有用:梯度告诉你方向和尺度,但学习率决定每次走多远。
为什么需要 torch.no_grad():
- 更新
w不是下一次前向计算图的一部分; - 不希望 autograd 继续记录更新动作本身;
- 可以省内存,也能避免图相关错误。
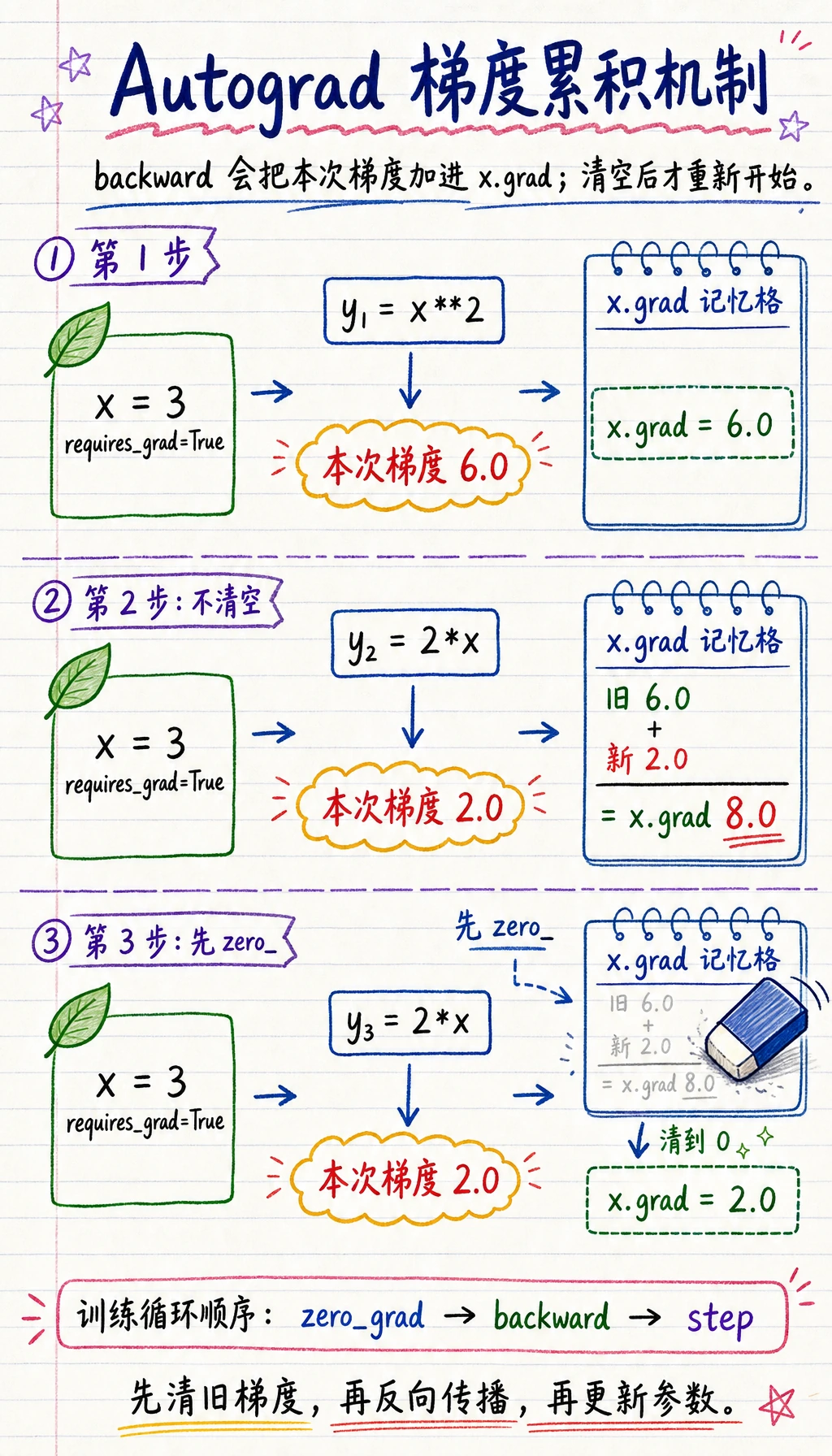
实验 3:看见梯度累积
Section titled “实验 3:看见梯度累积”PyTorch 默认会累积梯度,不会自动覆盖 .grad。
import torch
x = torch.tensor(3.0, requires_grad=True)
y1 = x ** 2y1.backward()print("after first backward:", x.grad.item())
y2 = 2 * xy2.backward()print("after second backward:", x.grad.item())
x.grad.zero_()y3 = 2 * xy3.backward()print("after zero and third backward:", x.grad.item())预期输出:
after first backward: 6.0after second backward: 8.0after zero and third backward: 2.0原因:
x=3时,x ** 2的梯度是6;2 * x的梯度是2;- 第二次 backward 后,
.grad变成6 + 2 = 8; - 调用
zero_()后,下一个梯度会从干净状态开始。
正常训练代码因此会使用:
optimizer.zero_grad()loss.backward()optimizer.step()实验 4:手写拟合两个参数
Section titled “实验 4:手写拟合两个参数”现在不用 nn.Linear,也不用 optimizer,手写训练一个小线性模型。这样训练闭环会完全可见。
import torch
# 目标规则:y = 2x + 1x = torch.tensor([1.0, 2.0, 3.0, 4.0])y_true = torch.tensor([3.0, 5.0, 7.0, 9.0])
w = torch.tensor(0.0, requires_grad=True)b = torch.tensor(0.0, requires_grad=True)lr = 0.05
print("two_parameter_fit")for epoch in range(201): y_pred = w * x + b loss = ((y_pred - y_true) ** 2).mean()
loss.backward()
with torch.no_grad(): w -= lr * w.grad b -= lr * b.grad
if epoch % 50 == 0: print( f"epoch={epoch:3d} " f"loss={loss.item():.4f} " f"w={w.item():.4f} " f"b={b.item():.4f}" )
w.grad.zero_() b.grad.zero_()预期输出:
two_parameter_fitepoch= 0 loss=41.0000 w=1.7500 b=0.6000epoch= 50 loss=0.0030 w=2.0452 b=0.8672epoch=100 loss=0.0007 w=2.0212 b=0.9375epoch=150 loss=0.0001 w=2.0100 b=0.9706epoch=200 loss=0.0000 w=2.0047 b=0.9862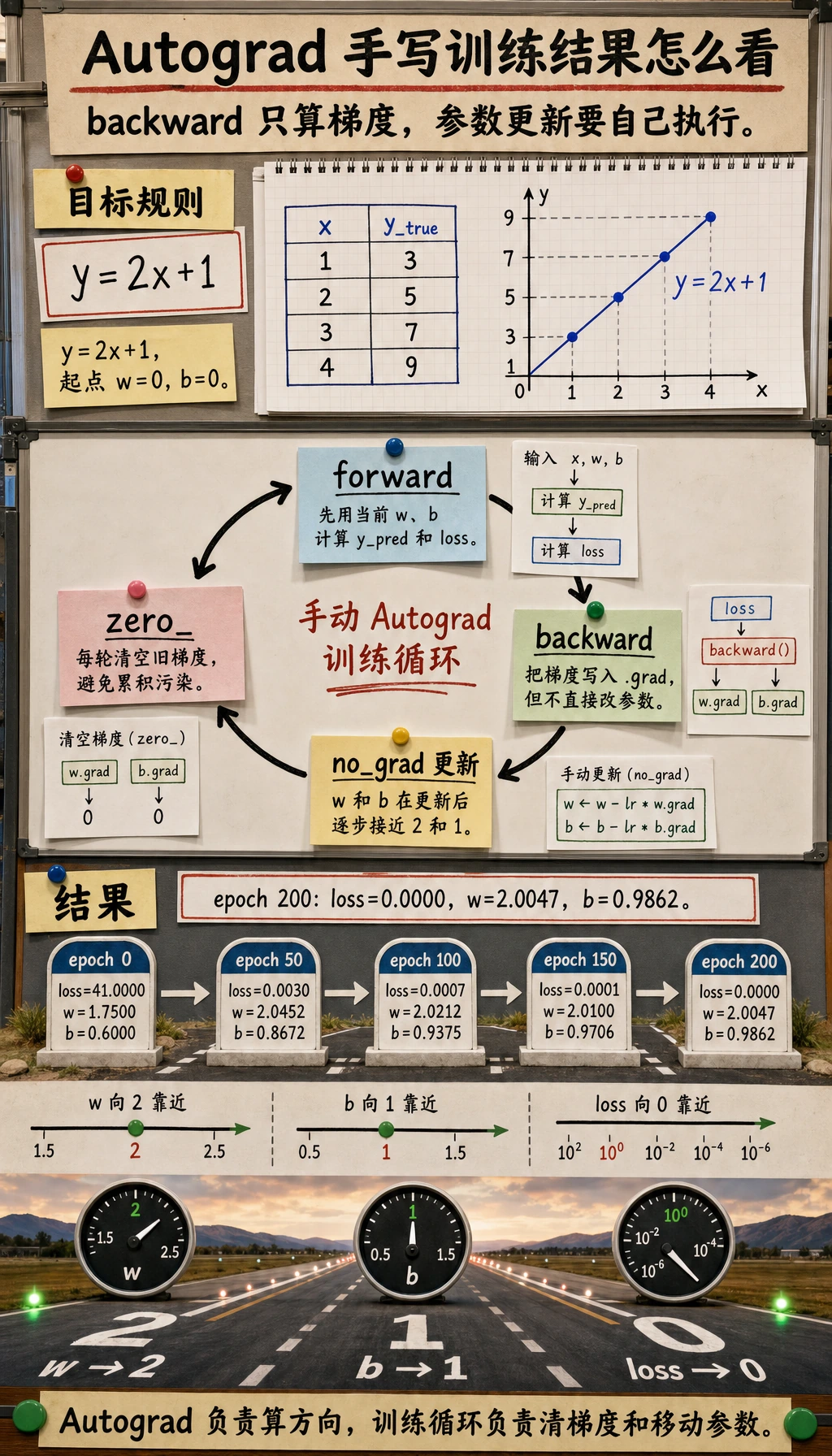
参数会靠近 w=2 和 b=1。神经网络使用的也是同一个循环,只是参数从两个变成了几百万甚至更多。
requires_grad、no_grad 和 detach
Section titled “requires_grad、no_grad 和 detach”这三个概念相关,但不能互换。
| 工具 | 什么时候用 | 效果 |
|---|---|---|
requires_grad=True | 这个张量是参数,或你需要它的梯度 | 未来运算会被追踪 |
torch.no_grad() | 推理或手写参数更新 | 临时停止记录计算图 |
tensor.detach() | 想拿到不带历史图的张量值 | 返回一个和 autograd 断开的张量 |
运行检查:
import torch
w = torch.tensor(5.0, requires_grad=True)
tracked = w * 2detached = tracked.detach()
with torch.no_grad(): untracked = w * 3
print("tracked.requires_grad:", tracked.requires_grad)print("detached.requires_grad:", detached.requires_grad)print("untracked.requires_grad:", untracked.requires_grad)预期输出:
tracked.requires_grad: Truedetached.requires_grad: Falseuntracked.requires_grad: False实用场景:
- 验证和预测时用
no_grad()。 - 记录日志、转 NumPy、保存不该保留整张图的值时,用
detach()。 - 如果某个张量还需要通过 loss 传回梯度,不要 detach 它。
常见错误模式
Section titled “常见错误模式”| 现象 | 可能原因 | 修复 |
|---|---|---|
.grad 是 None | 张量不需要梯度,或它不是叶子张量 | 检查 requires_grad,查看模型参数 |
| 训练变得不稳定 | 梯度没有清空 | 在 backward() 前调用 optimizer.zero_grad() |
RuntimeError: Trying to backward through the graph a second time | backward 后重复使用同一张图 | 重新前向计算;只有明确原因时才用 retain_graph=True |
| 内存一直涨 | 把连着计算图的 tensor 存进列表 | 存 loss.item() 或 tensor.detach() |
| 验证很慢、占内存 | 评估时还在追踪梯度 | 用 with torch.no_grad(): 包住验证 |
快速排错清单
Section titled “快速排错清单”backward() 前:
print("loss requires_grad:", loss.requires_grad)print("w requires_grad:", w.requires_grad)backward() 后:
print("w.grad:", w.grad)print("b.grad:", b.grad)普通训练循环的顺序是:
forwardlosszero_gradbackwardstep
有些代码会把 zero_grad 放在 forward 之前,但核心规则一样:下一次更新前清掉旧梯度。
保留一条 autograd trace:
- 损失是否需要梯度
- True
- 参数_requires_grad
- True
- 反向传播后梯度
- 不为 None
- 更新规则
- 反向传播计算梯度,优化器或手动代码更新数值
- 安全日志
- 记录 loss.item() 或 tensor.detach()
这可以避免最常见的误解:backward() 不是更新参数。它只负责填充梯度。
- 把实验 4 改成学习
y = 3x - 2。w和b应该接近什么? - 删除实验 4 里的
w.grad.zero_()和b.grad.zero_(),观察会发生什么。 - 把
lr改成0.5和0.005。哪个不稳定,哪个太慢? - 连续 200 个 epoch 把
loss本身存进列表,再改成存loss.item()。为什么第二种更安全?
参考实现与讲解
w应该接近3,b应该接近-2。如果数据有噪声或训练提前停止,有小偏差是正常的。- PyTorch 默认会累积梯度。不清零时,每次更新都会混入前面几轮的梯度,相当于步子越来越不受控,训练可能变得不稳定。
lr=0.5更容易越过最优点或发散;lr=0.005通常更慢,因为每一步更新太小。- 保存
losstensor 可能保留计算图引用,造成额外内存占用。loss.item()只保存 Python 数字,更适合作日志。
- Autograd 会记录从参数到 loss 的计算图。
backward()计算梯度,但不更新参数。- 梯度默认会累积,下一次更新前要清空。
- 推理和手写更新用
no_grad();只要数值、不保留图时用detach()。