12.4.3 AI 伦理与安全
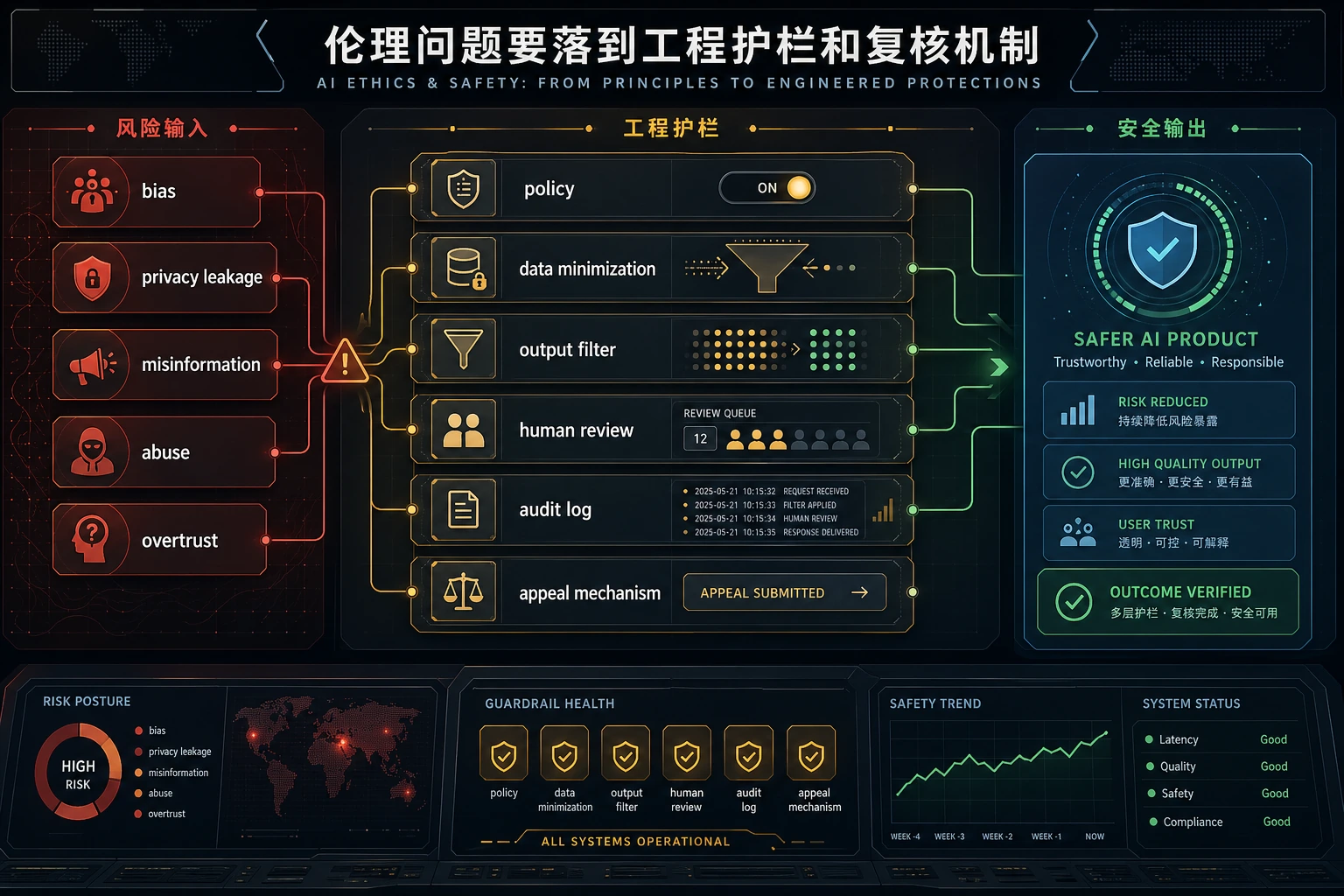
- 理解 AIGC 系统常见的伦理与安全风险类型
- 学会把风险拆成偏见、隐私、虚假内容、滥用等不同类别
- 理解为什么“人类监督”在很多高风险场景仍然重要
- 建立“伦理问题必须落到工程措施”的视角
先建立一张地图
Section titled “先建立一张地图”AI 伦理与安全更适合按“风险类型 -> 现实后果 -> 工程措施”来理解:
flowchart LR A["偏见 / 隐私 / 幻觉 / 滥用 / 过度信任"] --> B["会进入真实世界"] B --> C["需要评估、权限、护栏、人类监督"]所以这节真正想解决的是:
- 为什么伦理问题不是抽象口号
- 为什么它最后一定会落回系统设计
一、为什么 AIGC 的伦理与安全问题特别突出?
Section titled “一、为什么 AIGC 的伦理与安全问题特别突出?”因为它生成的是:
- 文本
- 图像
- 音频
- 视频
这些内容很容易直接进入:
- 用户认知
- 舆论传播
- 决策流程
也就是说,它不是只在内部算分,而是直接影响现实世界。
所以它的风险不只是“答错题”,而可能是:
- 错误建议
- 误导信息
- 深度伪造
- 隐私暴露
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把 AIGC 系统理解成:
- 一个会大规模自动生产内容的机器
普通软件很多时候是在处理内部逻辑; AIGC 更常常是在直接生产:
- 人会看、会信、会转发、会据此做决定的内容
这就是为什么它的伦理和安全风险会被放大。
二、第一类风险:偏见与不公平
Section titled “二、第一类风险:偏见与不公平”为什么会有偏见?
Section titled “为什么会有偏见?”因为模型会从历史数据中学到模式。 而历史数据本身就可能带着:
- 性别偏见
- 地域偏见
- 职业刻板印象
一个最直观的理解
Section titled “一个最直观的理解”如果训练数据里长期把某类群体和某种标签绑在一起,模型就可能学到这些偏差。
这说明:
模型不会自动比人类更公平,它往往会继承甚至放大已有偏差。
一个很适合初学者先记的风险表
Section titled “一个很适合初学者先记的风险表”| 风险类型 | 最值得先问什么 |
|---|---|
| 偏见 | 系统会不会系统性对某些群体更不公平? |
| 隐私 | 有没有把不该看的、记的、输出的内容暴露出来? |
| 幻觉 | 有没有把“不知道”伪装成“很确定”? |
| 滥用 | 会不会被拿去做明显有害的事? |
| 过度信任 | 用户会不会因为它像人而过度相信它? |
这个表很适合新人,因为它会把“伦理与安全”重新压回几类可以具体检查的问题。
这类问题为什么难?
Section titled “这类问题为什么难?”因为它通常不是“明显报错”,而是:
- 微妙但持续
- 大规模输出
这就使它特别需要评估与监控。
三、第二类风险:隐私与敏感信息泄露
Section titled “三、第二类风险:隐私与敏感信息泄露”为什么 AIGC 特别容易碰到这个问题?
Section titled “为什么 AIGC 特别容易碰到这个问题?”因为它经常处理的是:
- 用户上传内容
- 企业内部文档
- 对话历史
这些内容里很可能有:
- 身份信息
- 医疗信息
- 商业机密
一个很重要的工程直觉
Section titled “一个很重要的工程直觉”隐私问题不只是“模型会不会记住训练数据”,也包括:
- 检索有没有越权
- 日志有没有误存
- 输出有没有暴露敏感字段
也就是说,隐私问题往往是:
模型 + 系统 + 流程 的综合问题。
四、第三类风险:虚假内容和幻觉
Section titled “四、第三类风险:虚假内容和幻觉”为什么生成系统天然会有这个风险?
Section titled “为什么生成系统天然会有这个风险?”因为模型的目标通常不是:
- 只输出真话
而是:
- 生成最像合理回答的内容
这就会带来幻觉问题。
为什么在 AIGC 场景更危险?
Section titled “为什么在 AIGC 场景更危险?”因为一旦生成的是:
- 新闻摘要
- 医疗建议
- 法律解释
- 合成视频
错误的后果会被放大。
所以幻觉不是“模型小毛病”,在很多场景里它是高风险问题。
五、第四类风险:滥用与恶意使用
Section titled “五、第四类风险:滥用与恶意使用”这类问题为什么格外现实?
Section titled “这类问题为什么格外现实?”因为 AIGC 不只是帮助正当用户,也可能被用于:
- 批量诈骗文案
- 深度伪造
- 自动化攻击脚本
- 虚假宣传
这意味着什么?
Section titled “这意味着什么?”意味着安全问题不只是“模型本身会不会失控”,也包括:
系统被人拿去做什么。
所以很多时候,防护重点也会落到:
- 权限
- 配额
- 内容审查
- 输出限制
六、第五类风险:过度拟人化与错误信任
Section titled “六、第五类风险:过度拟人化与错误信任”很多用户会天然把:
- 会说话
- 会解释
- 看起来很自信
误解为:
- 真的懂
- 一定可靠
这在数字人、语音助手、多模态系统里尤其明显。
所以一个很重要的问题不是“模型会不会说”,而是:
用户会不会因为它“像人”而对它产生错误信任。
这也是伦理层非常值得重视的一类风险。
七、为什么“人类监督”仍然重要?
Section titled “七、为什么“人类监督”仍然重要?”因为在很多高风险场景里,你不能把最终决策完全交给生成系统。
例如:
- 医疗
- 法律
- 金融
- 高风险企业流程
这时更稳妥的思路通常是:
- 模型先给建议
- 人类做最终确认
所以一个非常实用的判断是:
高风险场景里,AIGC 更适合做辅助而不是完全替代。
一个很适合初学者先记的分层思路
Section titled “一个很适合初学者先记的分层思路”可以先把治理方式理解成三层:
- 先做风险分类
- 再做系统护栏
- 最后在高风险场景保留人类确认
如果一上来只剩“相信模型”或“完全不让模型做事”, 通常都不是最稳的工程方案。
八、一个很实用的风险拆解示意
Section titled “八、一个很实用的风险拆解示意”risk_map = { "bias": "输出带刻板印象或不公平倾向", "privacy": "泄露敏感信息或越权访问", "hallucination": "生成不真实但看起来合理的内容", "misuse": "被用于诈骗、伪造、攻击等恶意场景", "overtrust": "用户对系统能力产生错误信任"}
for k, v in risk_map.items(): print(k, "->", v)预期输出:
bias -> 输出带刻板印象或不公平倾向privacy -> 泄露敏感信息或越权访问hallucination -> 生成不真实但看起来合理的内容misuse -> 被用于诈骗、伪造、攻击等恶意场景overtrust -> 用户对系统能力产生错误信任可以把它当作风险登记表的第一步。风险类别先看得见,后面才能分配负责人、检查项和缓解措施。
这个例子不是在“解决风险”,而是在教你:
风险必须先被分类清楚,后面才能谈工程措施。
九、真正重要的一点:伦理问题必须落到工程问题
Section titled “九、真正重要的一点:伦理问题必须落到工程问题”讲伦理如果只停留在:
- 公平
- 责任
- 透明
这些词,很容易空。
真正有价值的做法是继续追问:
- 这个风险会在哪个模块出现?
- 该靠评估、权限、日志还是人工确认来兜?
也就是说:
伦理问题最终必须能落到可执行的系统设计。
如果把它做成项目或治理文档,最值得展示什么
Section titled “如果把它做成项目或治理文档,最值得展示什么”最值得展示的通常不是:
- “我们重视伦理”
而是:
- 你识别了哪几类风险
- 每类风险对应什么工程措施
- 哪些场景保留了人类确认
- 哪些问题会进入持续评估和监控
这样别人会更容易看出:
- 你理解的是伦理治理闭环
- 不只是停留在价值表态
学完这一页,至少保留这张证据卡:
- 风险范围
- 前沿能力、伦理问题、监管,或产品政策边界
- 工程规则
- 必须记录、阻止、审核、披露或上报什么
- 测试用例
- 一个符合规则的真实输入/输出案例
- 失败检查
- 隐私、版权、肖像、偏见、安全、来源或合规缺口
- 期望产出
- 将复查清单或产品需求翻译成工程动作
这一节最重要的不是背几个风险名词,而是理解:
AIGC 伦理与安全的核心,不只是“模型会不会错”,而是“这些错误会不会通过系统进入真实世界并造成后果”。
只有当你把风险看成“模型 + 数据 + 系统 + 用户”的综合问题,后面的治理才会真正落地。
- 选一个你熟悉的 AIGC 产品,试着从偏见、隐私、幻觉、滥用里挑两类风险做分析。
- 想一想:为什么“模型像人”会提升用户错误信任的风险?
- 用自己的话解释:为什么高风险场景更适合“模型辅助 + 人类确认”?
- 试着把一个伦理风险转写成一个具体工程问题,例如“日志脱敏”“权限控制”或“人工审批”。
解题思路与讲解
- 有用回答应把每类风险转成证据和控制措施。例如人脸编辑应用可能需要按肤色做偏差测试,并为上传、保存和删除设置隐私控制。
- 类人输出会增加信任,因为用户会把社会互动预期套到系统上。他们可能误以为模型真正理解、记住或验证了更多内容。
- 高风险场景需要人类确认,因为模型可以辅助起草或检测,但责任、上下文判断和最终批准应由负责任的人承担。
- 当伦理风险被写成需求时,它就变成工程工作:日志匿名化、按角色限制访问、记录同意、高风险导出前人工审批,或阻止不安全 prompt。