5.6.2 项目一:房价预测(回归问题)
| 信息 | 说明 |
|---|---|
| 任务类型 | 回归 |
| 数据集 | California Housing(sklearn 内置) |
| 评估指标 | RMSE、R² |
| 涉及技能 | EDA、特征工程、多模型对比、调参 |
读代码前先认识几个关键术语
Section titled “读代码前先认识几个关键术语”- EDA(Exploratory Data Analysis,探索性数据分析):建模前先看分布、缺失值、异常值和相关性。本项目里,EDA 帮你先知道自己到底在预测什么样的房价分布。
- RMSE(Root Mean Squared Error,均方根误差):衡量平均预测误差,单位和目标值一致。越小越好,并且会更重地惩罚大错误。
- R²(决定系数):衡量模型解释了多少目标值波动。越接近 1 越好,但要和 RMSE 一起看,不能只看一个数字。
- GBDT(Gradient Boosting Decision Tree,梯度提升决策树):一种树模型集成方法,会一棵接一棵训练小树,让后面的树去修正前面模型的错误。
先建立一张地图
Section titled “先建立一张地图”这个项目最适合拿来练“一个回归项目到底应该怎么长出来”。
flowchart LR A["看数据和目标分布"] --> B["先做线性回归 baseline"] B --> C["做少量特征工程"] C --> D["对比树模型 / GBDT"] D --> E["调参"] E --> F["残差分析和解释"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style F fill:#e8f5e9,stroke:#2e7d32,color:#333一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把房价预测项目理解成:
- 给一批房子先做估价,再回头看自己哪里估偏了
这和很多真实业务很像:
- 不是只要给出一个数字
- 还要知道这个数字为什么大概合理
- 以及自己最容易在哪些房子上判断失准
如果你第一次做回归项目,就按这条线走,通常最稳。
这题你真正要练什么
Section titled “这题你真正要练什么”这个项目不只是“把回归模型跑通”,更重要的是练这 4 件事:
- 从数据探索里找到有用线索
- 先立一个简单 baseline
- 通过特征工程和模型对比提升效果
- 用误差分析解释模型哪里做得好、哪里做得差
这题为什么特别适合当第一个完整项目?
Section titled “这题为什么特别适合当第一个完整项目?”因为它同时有几个优点:
- 任务类型简单清楚,就是回归
- 指标直观,RMSE 和 R² 容易解释
- baseline 很容易立起来
- 后面也有很清楚的改进空间
推荐推进顺序
Section titled “推荐推进顺序”更适合新人的顺序通常是:
- 先做一个最简单的线性回归 baseline
- 再做基本特征工程
- 再上树模型或 GBDT
- 最后才做调参
如果一开始就直接上复杂模型,你通常会失去对问题本身的感觉。
第一版最重要的目标,不是高分
Section titled “第一版最重要的目标,不是高分”这一题第一版最重要的目标其实只有两个:
- 确认这个问题用回归建模是通的
- 建一个后面所有改进都能对照的 baseline
也就是说,第一版做得“简单但完整”,比一开始就做得“复杂但说不清楚”更有价值。
步骤 1:数据加载与探索
Section titled “步骤 1:数据加载与探索”import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.datasets import fetch_california_housing
# 加载数据data = fetch_california_housing()df = pd.DataFrame(data.data, columns=data.feature_names)df['MedHouseVal'] = data.target # 房价中位数(10 万美元)
print(f"数据形状: {df.shape}")print(df.describe())
# 目标分布fig, axes = plt.subplots(1, 2, figsize=(12, 4))df['MedHouseVal'].hist(bins=50, ax=axes[0], color='steelblue', edgecolor='white')axes[0].set_title('房价分布')axes[0].set_xlabel('房价中位数(10 万美元)')
# 相关性corr = df.corr()['MedHouseVal'].drop('MedHouseVal').sort_values()corr.plot.barh(ax=axes[1], color='coral')axes[1].set_title('各特征与房价的相关性')plt.tight_layout()plt.show()步骤 1.1 这一步最该问什么
Section titled “步骤 1.1 这一步最该问什么”第一次看数据时,不要只急着画图。先问这几个问题:
- 目标值分布是否偏斜
- 有没有特别明显的异常值区间
- 哪些特征可能和价格强相关
- 哪些特征很可能只是弱信号
这几问会直接决定你后面:
- 先上什么 baseline
- 特征工程优先做哪几项
- 误差分析该切哪些维度看
步骤 1.2 一个新人很值得先记的判断
Section titled “步骤 1.2 一个新人很值得先记的判断”第一次做回归题时,最容易犯的错是:
- 一上来就急着换模型
但更稳的顺序通常是:
- 先看数据
- 先理解目标值
- 先知道自己到底在预测什么分布
步骤 2:特征工程
Section titled “步骤 2:特征工程”# 构造新特征df['rooms_per_household'] = df['AveRooms'] / df['AveOccup']df['bedrooms_ratio'] = df['AveBedrms'] / df['AveRooms']df['population_per_household'] = df['Population'] / df['HouseAge']
# 准备数据from sklearn.model_selection import train_test_split
feature_cols = [c for c in df.columns if c != 'MedHouseVal']X = df[feature_cols]y = df['MedHouseVal']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)print(f"训练集: {X_train.shape}, 测试集: {X_test.shape}")步骤 2.1 第一次做特征工程时,为什么要克制一点
Section titled “步骤 2.1 第一次做特征工程时,为什么要克制一点”回归项目里最常见的错误之一,就是一口气构造太多特征,最后自己也说不清到底哪个有效。 更稳的做法是:
- 先只加 2~3 个最有解释力的新特征
- 每次加完都和 baseline 对比
- 如果没有明显收益,就不要因为“看起来高级”而硬留
步骤 2.2 一个更像真实业务的特征思路
Section titled “步骤 2.2 一个更像真实业务的特征思路”房价问题里很值得优先想到的特征,通常都和“单位成本”和“相对位置”有关,例如:
- 每房间面积
- 每户人口
- 房龄和位置的组合
这些都比“机械堆更多列”更像真实建模思路。
步骤 3:多模型对比
Section titled “步骤 3:多模型对比”from sklearn.linear_model import LinearRegression, Ridgefrom sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressorfrom sklearn.preprocessing import StandardScalerfrom sklearn.pipeline import make_pipelinefrom sklearn.metrics import mean_squared_error, r2_score
models = { '线性回归': make_pipeline(StandardScaler(), LinearRegression()), 'Ridge': make_pipeline(StandardScaler(), Ridge(alpha=1.0)), '随机森林': RandomForestRegressor(n_estimators=100, random_state=42), 'GBDT': GradientBoostingRegressor(n_estimators=100, random_state=42),}
results = {}for name, model in models.items(): model.fit(X_train, y_train) y_pred = model.predict(X_test) rmse = np.sqrt(mean_squared_error(y_test, y_pred)) r2 = r2_score(y_test, y_pred) results[name] = {'RMSE': rmse, 'R²': r2} print(f"{name:10s} | RMSE: {rmse:.4f} | R²: {r2:.4f}")
# 可视化fig, ax = plt.subplots(figsize=(8, 5))names = list(results.keys())r2s = [v['R²'] for v in results.values()]bars = ax.bar(names, r2s, color=['steelblue', 'coral', 'seagreen', 'gold'], alpha=0.8)for bar, score in zip(bars, r2s): ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.005, f'{score:.4f}', ha='center')ax.set_ylabel('R²')ax.set_title('模型 R² 对比')ax.grid(axis='y', alpha=0.3)plt.show()步骤 3.1 模型对比时最该看什么
Section titled “步骤 3.1 模型对比时最该看什么”不要只看哪个 R² 最高。更稳的对比方式是同时看:
RMSE有没有明显下降- 模型复杂度是不是高了很多
- 可解释性有没有明显变差
第一次做回归项目时,最值得珍惜的不是“最高分模型”,而是:
- 你知道为什么它比 baseline 好
- 你知道好在什么地方
步骤 3.2 一个新人可直接照抄的模型对比表
Section titled “步骤 3.2 一个新人可直接照抄的模型对比表”| 模型 | 优点 | 首次重点 |
|---|---|---|
| 线性回归 | 最好解释 | baseline 到底稳不稳 |
| Ridge | 更稳一点 | 正则化是否有帮助 |
| 随机森林 | 非线性更强 | 特征重要性和过拟合风险 |
| GBDT | 往往效果更强 | RMSE 是否明显下降 |
这个表很适合新人,因为它会把“模型名”重新拉回成“为什么要试它”。
步骤 4:模型调优
Section titled “步骤 4:模型调优”from sklearn.model_selection import RandomizedSearchCVfrom scipy.stats import randint, uniform
param_dist = { 'n_estimators': randint(100, 500), 'max_depth': randint(5, 20), 'learning_rate': uniform(0.01, 0.2), 'subsample': uniform(0.7, 0.3),}
rs = RandomizedSearchCV( GradientBoostingRegressor(random_state=42), param_dist, n_iter=30, cv=5, scoring='neg_root_mean_squared_error', random_state=42, n_jobs=-1)rs.fit(X_train, y_train)
y_pred_best = rs.predict(X_test)print(f"调优后 RMSE: {np.sqrt(mean_squared_error(y_test, y_pred_best)):.4f}")print(f"调优后 R²: {r2_score(y_test, y_pred_best):.4f}")print(f"最佳参数: {rs.best_params_}")步骤 5:结果分析
Section titled “步骤 5:结果分析”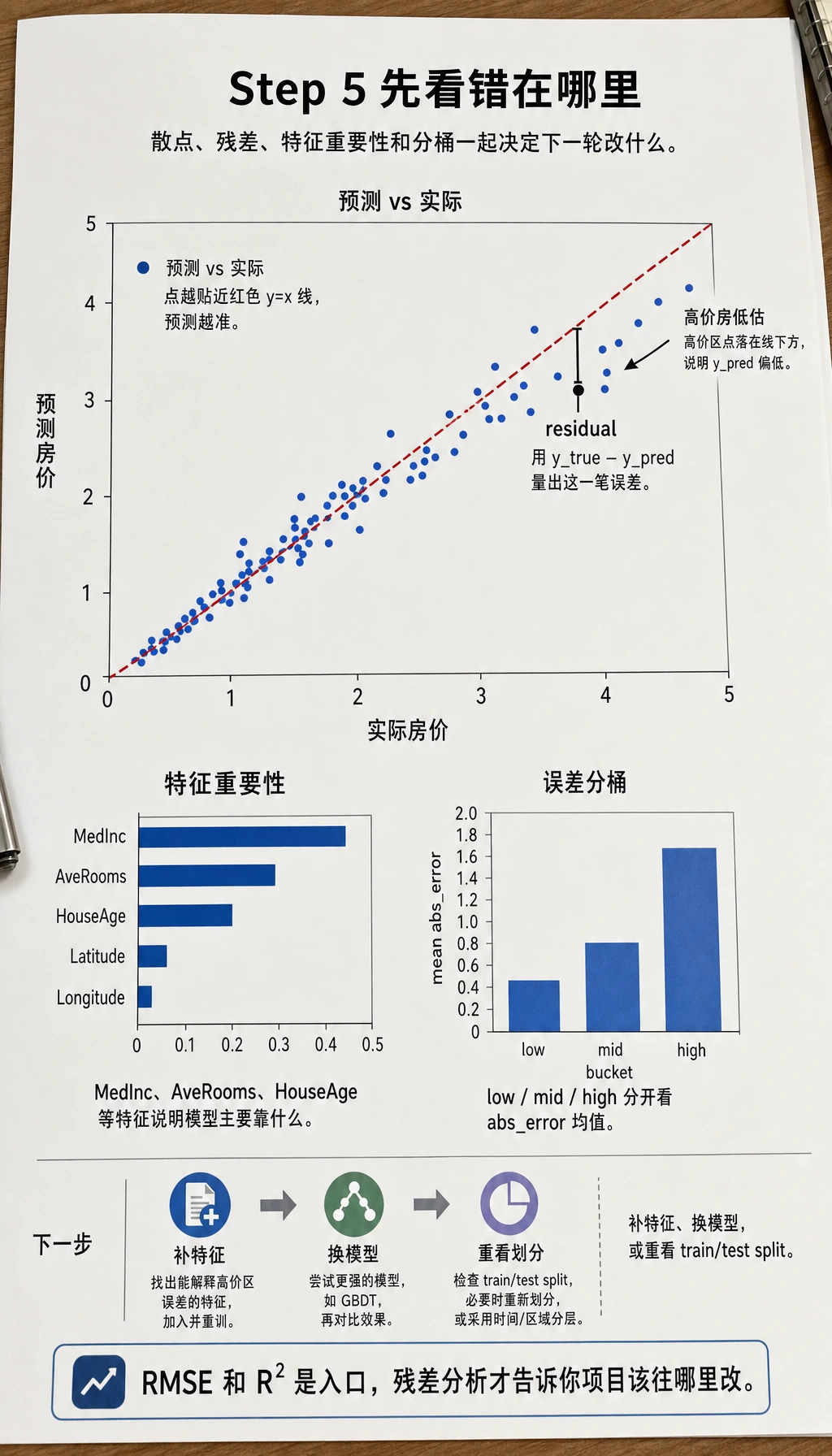
读这张图时先对照预测值和真实值,再检查残差模式,最后再决定是否换模型或加特征。
# 预测 vs 实际fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].scatter(y_test, y_pred_best, s=5, alpha=0.3)axes[0].plot([0, 5], [0, 5], 'r--')axes[0].set_xlabel('实际房价')axes[0].set_ylabel('预测房价')axes[0].set_title('预测 vs 实际')
# 特征重要性importance = rs.best_estimator_.feature_importances_sorted_idx = np.argsort(importance)axes[1].barh(range(len(sorted_idx)), importance[sorted_idx], color='coral')axes[1].set_yticks(range(len(sorted_idx)))axes[1].set_yticklabels(np.array(feature_cols)[sorted_idx])axes[1].set_title('特征重要性')
plt.tight_layout()plt.show()步骤 5.1 残差分析比最终分数更能体现你会不会做项目
Section titled “步骤 5.1 残差分析比最终分数更能体现你会不会做项目”很多人做到这里就停在 RMSE 和 R²。但真正能拉开项目质量的,往往是残差分析:
- 哪些价格区间误差特别大
- 模型是不是系统性低估高价房
- 哪些区域特征组合最容易预测错
这一步会直接决定你下一轮到底该:
- 补特征
- 换模型
- 还是重新看数据切分方式
步骤 5.2 再看一个最小“误差分桶”示例
Section titled “步骤 5.2 再看一个最小“误差分桶”示例”errors = pd.DataFrame({ "y_true": [1.0, 2.5, 4.2, 3.8], "y_pred": [1.2, 2.0, 3.1, 4.5],})errors["abs_error"] = (errors["y_true"] - errors["y_pred"]).abs()errors["bucket"] = pd.cut(errors["y_true"], bins=[0, 2, 4, 6], labels=["low", "mid", "high"])
print(errors.groupby("bucket", observed=False)["abs_error"].mean())预期输出:
bucketlow 0.2mid 0.6high 1.1Name: abs_error, dtype: float64这个例子很适合初学者,因为它会帮助你先建立一个关键习惯:
- 误差不是只看总体均值
- 还要看哪一类样本更容易错
在这个最小例子里,high 价格桶的平均误差最大。它不是在断言所有房价模型都会错在高价房,而是在示范 Step 5 的真正用法:把散点图里的现象变成下一轮要调查的问题。
一个很适合新人的最小复盘表
Section titled “一个很适合新人的最小复盘表”你可以直接做这样一张表:
| 版本 | 做了什么改动 | 我的判断 |
|---|---|---|
| baseline | 线性回归 | 先建立下界 |
| v2 | 加 2-3 个特征 | 看特征工程是否真有帮助 |
| v3 | 换树模型 / GBDT | 看非线性模型是否更合适 |
RMSE 和 R² 可以先放在 notebook 或实验日志里。写项目报告时,等你真的有可比较的数值后,再把指标列加进去。
这张表会让你的项目从“跑过代码”变成“有清楚迭代过程”。
一个新人很值得照抄的项目检查表
Section titled “一个新人很值得照抄的项目检查表”第一次做房价预测项目时,最稳的检查表通常是:
- baseline 是否已经立住
- 特征工程是否有明确业务含义
- 模型对比是否不仅看一个分数
- 残差分析是否已经告诉你下一步该改哪里
如果这 4 件事都做到位, 这个项目就已经不是“跑过一个回归脚本”,而是真正做过一次完整建模了。
如果继续把这个项目往上做,最值得补什么
Section titled “如果继续把这个项目往上做,最值得补什么”更值得优先补的通常是:
- 残差分布分析
- 不同区域 / 房价区间上的误差对比
- baseline 到最优模型的完整版本演化说明
这样项目会更像一个真正做过建模和复盘的回归作品。
项目交付时最好补上的内容
Section titled “项目交付时最好补上的内容”- 一张“真实值 vs 预测值”的图
- 一段对误差来源的说明
- 一份 baseline 和改进版的对比表
- 一段“如果继续做,我会优先改什么”的总结
做成作品集时,最值得展示什么
Section titled “做成作品集时,最值得展示什么”如果你想把这题做成作品集页,最值得展示的不是一长串模型名字,而是:
- 你的 baseline 是什么
- 你做了哪一轮最有效的改进
- 改进前后
RMSE / R²怎么变了 - 你通过残差分析发现了什么
- 你下一步准备怎么继续提升
项目检查清单
Section titled “项目检查清单”- 完成 EDA:分布、相关性、缺失值
- 特征工程:构造至少 2 个新特征
- 至少对比 3 种模型
- 对最佳模型做超参数调优
- 残差分析和特征重要性分析
项目交付参考与讲解
- EDA 完成的标准不是“画过图”,而是记录分布、缺失值、相关性和可疑异常值,并写出它们对建模的影响。
- 新特征应该有清楚的房产业务含义,例如面积比例或质量汇总。如果特征来自未来信息或目标派生信息,要当作泄漏排除。
- 多模型比较必须使用同一个划分或交叉验证方案。保留一个简单 baseline,才能诚实判断改进是否有效。
- 超参数调优应该放在 baseline 跑通之后,用验证集或交叉验证完成,测试集只做最后检查。
- 残差分析要说清模型最容易错在哪里,例如高价房或某个区域桶。下一轮实验应该从这个发现出发。
版本路线建议
Section titled “版本路线建议”| 版本 | 目标 | 交付重点 |
|---|---|---|
| 基础版 | 跑通最小闭环 | 能输入、能处理、能输出,并保留一组示例 |
| 标准版 | 形成可展示项目 | 增加配置、日志、错误处理、README 和截图 |
| 挑战版 | 接近作品集质量 | 增加评估、对比实验、失败样本分析和下一步路线 |
建议先完成基础版,不要一开始就追求大而全。每提升一个版本,都要把“新增了什么能力、怎么验证、还有什么问题”写进 README。
学完这一页,至少保留这张证据卡:
- 项目目标
- 预测、分割、Kaggle,或端到端 ML 作品集目标
- 流水线
- 数据划分、预处理、模型、评估和报告工件
- 结果
- 指标表、图表、预测、失败样本和 README 说明
- 失败检查
- 运行不可复现、泄漏、过拟合、基线薄弱或缺少部署边界
- 期望产出
- 包含流水线、指标和失败复盘的 ML 项目文件夹