E.A.3 模型优化技术
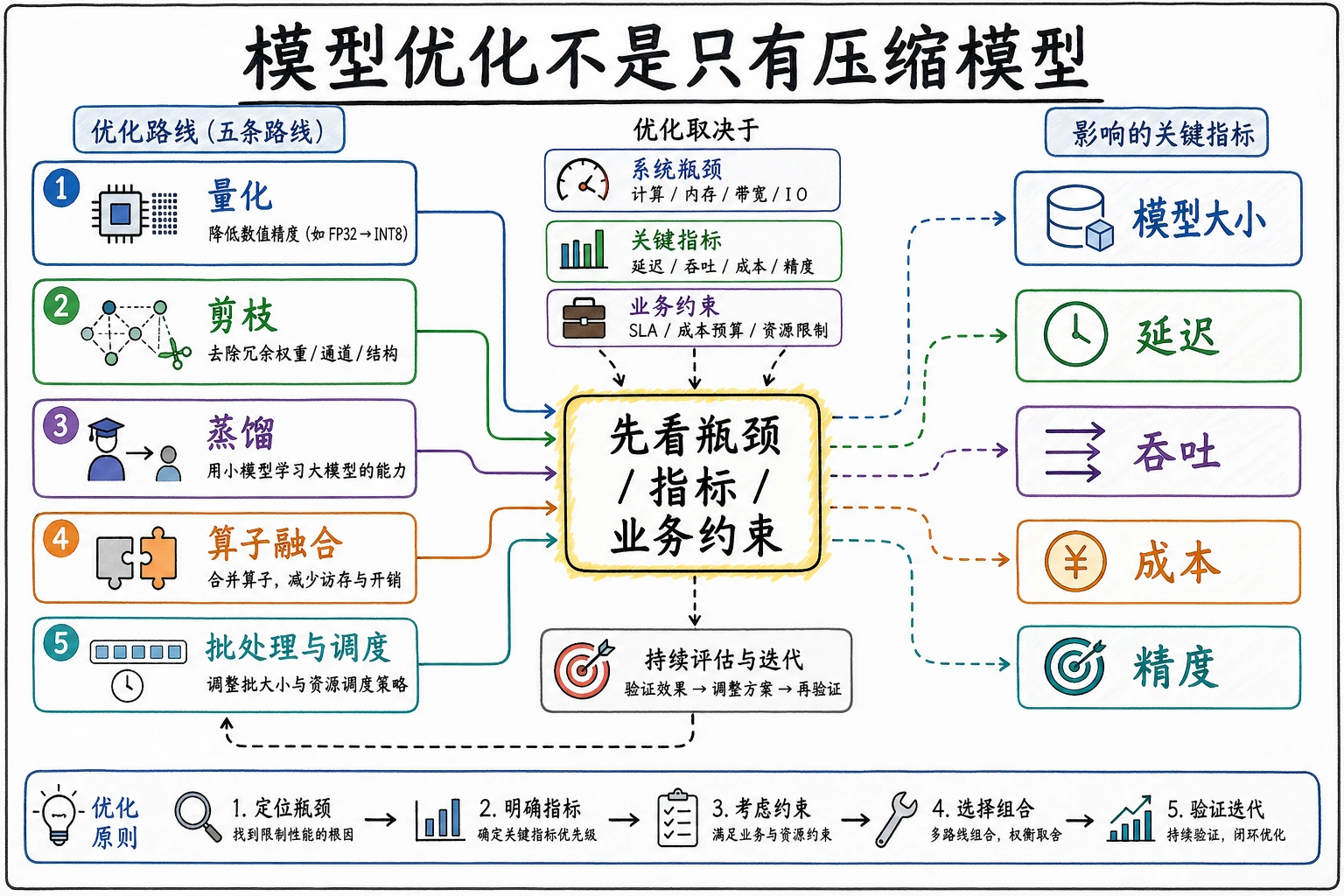

优化不是“把模型压到越小越好”,而是在改善一个约束时,同时检查你失去了什么。
运行一个很小的量化误差检查
Section titled “运行一个很小的量化误差检查”values = [0.1234, 0.5678, 0.9012]quantized = [round(value * 255) / 255 for value in values]errors = [abs(original - compressed) for original, compressed in zip(values, quantized)]
print([round(value, 4) for value in quantized])print(f"max_error={max(errors):.4f}")预期输出:
[0.1216, 0.5686, 0.902]max_error=0.0018这是最小优化习惯:压缩,测误差,再判断误差是否可接受。
选择合适的优化路径
Section titled “选择合适的优化路径”| 技术 | 什么时候适合 | 上线前检查 |
|---|---|---|
| 量化 | 延迟和内存太高 | 真实验证样本上的准确率下降 |
| 剪枝 | 很多权重或通道没用 | runtime 是否真的变快 |
| 蒸馏 | 小模型可以模仿大模型 | 小模型是否在边界样本失败 |
| 算子融合 | runtime overhead 高 | 引擎是否支持融合后的图 |
| Batching / scheduling | 多请求一起到达 | 长尾延迟和队列等待 |
- 先测 baseline 延迟、内存、准确率。
- 一次只尝试一种优化。
- 记录前后指标。
- 保留失败样本。
- 只有取舍清楚时才上线。
把每次优化都当成受控实验。对照组是原始模型和原始 runtime,实验组只能改一件事,例如量化、剪枝、batching 或切换推理引擎。如果一次改太多,结果变好了也很难知道是谁起作用。
复盘时保留一张小表:优化前延迟、优化后延迟、内存、模型大小、质量指标和失败样本。只要质量下降,就要能指出哪些样本变差,以及这个代价是否被产品接受。
交付检查时,先写一句“本次优化解决的约束”。例如:显存不够、冷启动太慢、P95 延迟超标、边缘设备放不下。没有约束就不要优化,因为你很可能只是在让系统更复杂,而不是让产品更可靠。
如果优化失败,也要保留记录。失败的量化方案、过大的精度损失、没有变快的剪枝,都能帮助后续同学少走弯路。好的优化笔记不只记录成功,也记录为什么某条路暂时不选。
最后把决策写成一句话:保留、调整或放弃优化,并说明依据。
如果依据只有“文件变小了”,还不够。还要说明用户是否更快拿到结果,系统是否更省资源,质量是否仍在可接受范围内。
学完这一页,至少保留这张证据卡:
- 部署目标
- 本地推理、边缘设备、模型服务器或优化实验
- 工件
- C++ 代码片段、基准测试、模型工件、服务配置或部署说明
- 指标
- 延迟、内存、吞吐量、模型大小、准确率下降或可靠性
- 失败检查
- ABI/构建问题、硬件不匹配、量化损失或服务瓶颈
- 期望产出
- 可复现的部署或优化证据,而不只是理论笔记
你能说明一种优化的收益、可能代价,以及真实部署前要看哪个指标,就算通过。
检查思路与讲解
一个合格答案会点名一种优化方法、它带来的收益、潜在代价,以及上线前要看的指标。例如量化可以降内存,但要检查验证集精度和失败样本;剪枝可能让模型更小,但还要确认 runtime 真的变快。
不要只说“越小越好”。要说明压缩后保留了什么、丢掉了什么,以及为什么这个取舍在真实部署里可接受。