6.3.4 经典 CNN 架构
- 解释 LeNet、AlexNet、VGG、ResNet 各自贡献了什么。
- 用“这个设计解决了什么问题”来阅读经典架构。
- 比较大 kernel 和堆叠小 kernel。
- 实现一个最小残差块。
- 判断哪些思想在现代 CNN 实践中仍然重要。
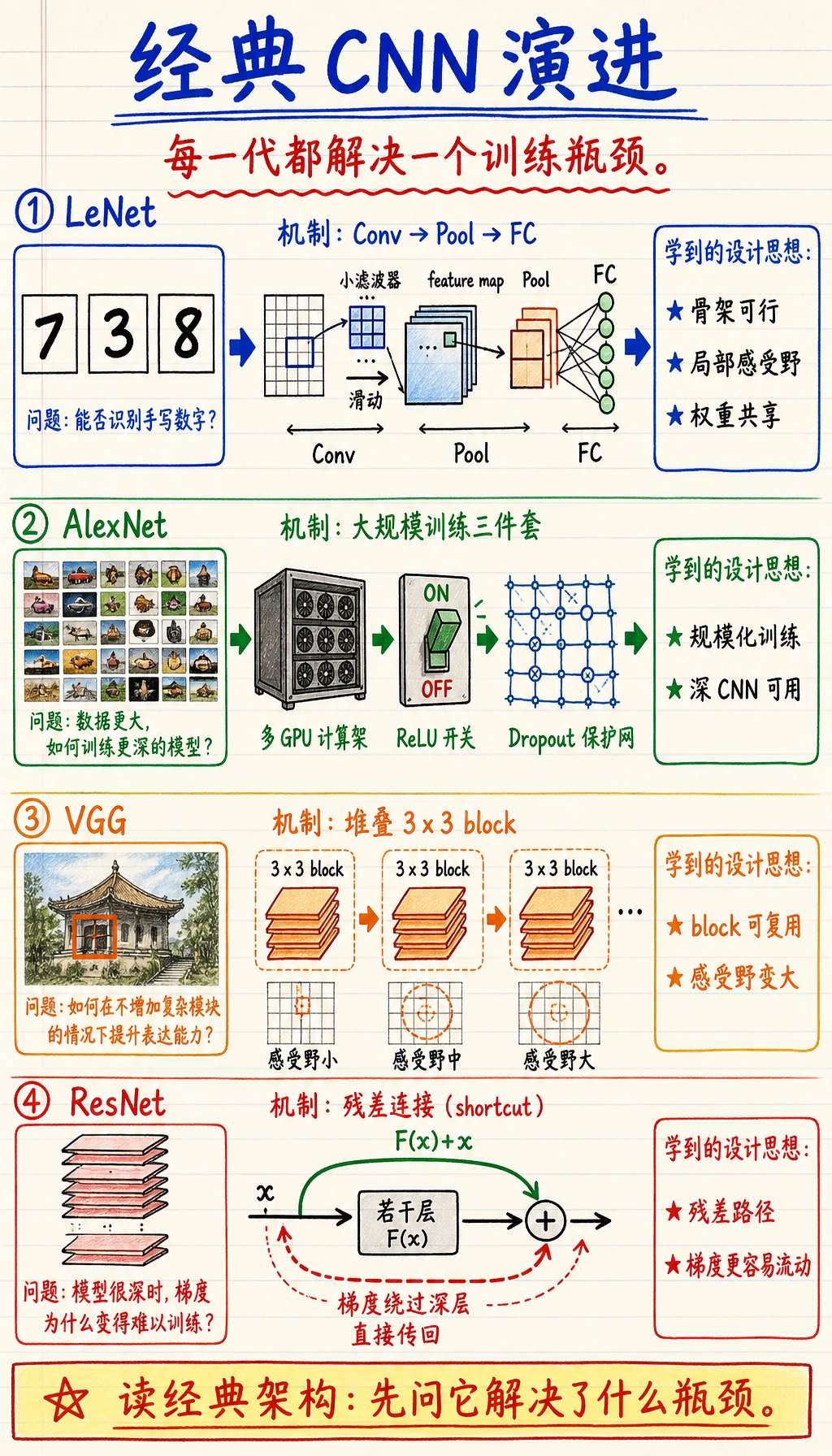
按下面这条线读图:
| 架构 | 记住什么 | 核心启发 |
|---|---|---|
| LeNet | 早期 CNN 骨架 | 卷积和池化可以做图像识别 |
| AlexNet | 规模化和 GPU 训练 | 数据、算力、训练技巧配合后,深 CNN 很有效 |
| VGG | 重复 3 x 3 block | 小 kernel 也能干净地构造大感受野 |
| ResNet | 残差路径 | 很深的网络需要更容易的梯度和信息流 |
重点不是今天照搬这些模型,而是继承它们回答过的设计问题。
LeNet:CNN 骨架
Section titled “LeNet:CNN 骨架”LeNet 很早,但它的骨架今天仍然熟悉:
它留下了三个耐用的想法:
- 不要在提取局部模式之前就 flatten 图像;
- 用 pooling 压缩局部响应;
- 让后面的层基于更高层特征做分类。
理解 LeNet,就理解了很多图像分类器背后的最小结构。
AlexNet:规模让 CNN 变得有说服力
Section titled “AlexNet:规模让 CNN 变得有说服力”AlexNet 重要,是因为它同时结合了几件事:
- 更大的数据集;
- 更深的 CNN;
- GPU 训练;
- ReLU 加快优化;
- Dropout 做正则化。
它的实践启发是:单靠架构通常不够。数据、算力、训练稳定性和正则化必须一起配合。
对有经验的读者来说,这是 CNN 历史里的第一个系统性经验:模型质量是一整套栈,不是某一层突然聪明。
VGG:小 kernel,重复 block
Section titled “VGG:小 kernel,重复 block”VGG 让一个简单配方流行起来:
为什么堆叠小 kernel,而不是直接用一个大 kernel?
- 堆叠层可以扩大感受野;
- 每层都能加入一次非线性;
- 参数量更可控;
- 重复 block 更容易阅读和复现。
实验 1:比较 kernel 参数量
Section titled “实验 1:比较 kernel 参数量”这个比较不是完整结论,但能提供有用直觉。
from torch import nn
def count_params(module): return sum(p.numel() for p in module.parameters() if p.requires_grad)
one_large_kernel = nn.Conv2d(16, 16, kernel_size=7, padding=3)three_small_kernels = nn.Sequential( nn.Conv2d(16, 16, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(16, 16, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(16, 16, kernel_size=3, padding=1),)
print("kernel_param_lab")print("one 7x7 conv :", count_params(one_large_kernel))print("three 3x3 conv:", count_params(three_small_kernels))预期输出:
kernel_param_labone 7x7 conv : 12560three 3x3 conv: 6960在这个设置里,堆叠 3 x 3 的参数更少,而且每次卷积之间还能加入非线性。这也是 VGG 风格思路能成为干净 baseline 的原因。
实验 2:运行 VGG 风格 block
Section titled “实验 2:运行 VGG 风格 block”import torchfrom torch import nn
vgg_block = nn.Sequential( nn.Conv2d(3, 16, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(16, 16, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(2),)
x = torch.randn(2, 3, 32, 32)y = vgg_block(x)
print("vgg_block_lab")print("input:", tuple(x.shape))print("output:", tuple(y.shape))预期输出:
vgg_block_labinput: (2, 3, 32, 32)output: (2, 16, 16, 16)读法:
- 两个
3 x 3卷积连续细化 feature; - pooling 把高宽减半;
- 输出通道变成
16。
ResNet:让深度变得可训练
Section titled “ResNet:让深度变得可训练”更深的网络理论上表达力更强,但实际可能更难优化。ResNet 的关键想法是残差连接:
output = learned_change(x) + x它不是要求每个 block 都重新学习一个全新表示,而是让 block 在输入基础上学习一个变化。如果这个 block 暂时没学到有用东西,shortcut 仍然能把信息传下去。
实验 3:实现残差块
Section titled “实验 3:实现残差块”import torchfrom torch import nn
class ResidualBlock(nn.Module): def __init__(self, channels): super().__init__() self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.relu = nn.ReLU() self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x): identity = x out = self.relu(self.conv1(x)) out = self.conv2(out) out = out + identity return self.relu(out)
block = ResidualBlock(8)x = torch.randn(2, 8, 16, 16)y = block(x)
print("residual_block_lab")print("input:", tuple(x.shape))print("output:", tuple(y.shape))预期输出:
residual_block_labinput: (2, 8, 16, 16)output: (2, 8, 16, 16)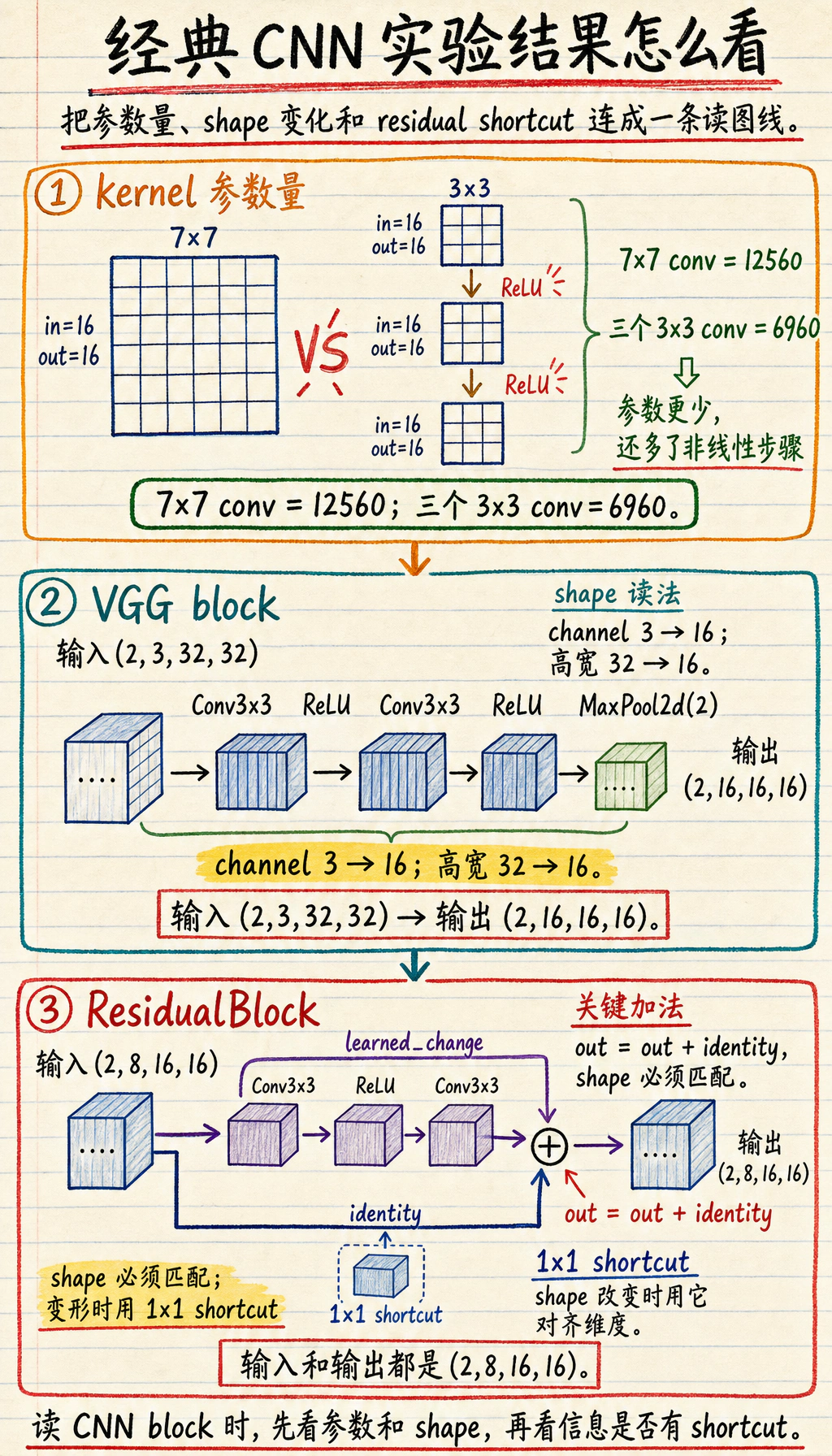
最重要的一行是:
out = out + identity这个加法是逐元素相加,所以 shape 必须一致。真实 ResNet 变体在通道数或空间尺寸变化时,会在 shortcut 中使用 1 x 1 卷积对齐维度。
如何阅读架构图
Section titled “如何阅读架构图”看到一个新的 CNN 架构时,先问这些问题:
| 问题 | 为什么重要 |
|---|---|
| 第一阶段如何降低空间尺寸? | 太早压缩会损失细节 |
| 通道在哪里增加? | 通道保存 feature 多样性 |
| block 是否重复? | 重复 block 让架构更容易扩展 |
| 是否有 shortcut path? | shortcut 改善优化和信息流 |
| classifier head 怎么做? | Flatten 和 GAP 的参数成本不同 |
这比背精确层数更有用。
今天还重要吗?
Section titled “今天还重要吗?”现代项目里,你不一定会从 LeNet 或 AlexNet 开始,但它们的思想还在:
- LeNet:feature extractor / classifier 的分工;
- AlexNet:数据、算力、激活、正则化要作为系统一起看;
- VGG:重复的简单 block;
- ResNet:残差路径作为默认设计工具。
许多现代 CNN backbone 和混合视觉模型仍然继承这些思想,即使名字和 block 看起来更新。
做一张架构记忆卡:
- LeNet 要点
- 卷积特征提取器 + 分类头
- AlexNet 要点
- 规模、GPU、ReLU、正则化
- VGG 要点
- 重复的小型 3x3 模块
- ResNet 要点
- 快捷路径让深层网络可训练
- 代码线索
- 残差块使用 out + identity
这是工程上真正值得记住的历史层级。你不需要先背下每个模型的层数,才开始读现代 backbone。
| 错误 | 更好的看法 |
|---|---|
| 背模型名字 | 记住每个模型解决的瓶颈 |
| 以为 VGG 只是“很多层” | 真正启发是重复小 kernel block |
| 以为 ResNet 只是“很深” | 真正启发是让深度可训练 |
| 直接照搬经典模型 | 通常从预训练现代 backbone 开始 |
| 忽略计算成本 | 架构选择必须适配数据规模和部署限制 |
- 用一句话分别总结 LeNet、AlexNet、VGG、ResNet。
- 把
ResidualBlock(8)改成ResidualBlock(16),并同步更新输入 tensor。 - 从 VGG 风格 block 中删掉一个
3 x 3卷积。什么变了,什么没变? - 解释为什么通道数不同时,
out + identity会失败。 - 选择一个现代 CNN backbone,指出它仍然使用了哪些经典思想。
参考实现与讲解
- LeNet 证明卷积可用于视觉识别;AlexNet 推动深度 CNN 规模化;VGG 展示小卷积堆叠;ResNet 用残差连接训练更深网络。
- 改成
ResidualBlock(16)后,输入 tensor 的通道维也要是 16,否则卷积和残差相加都会 shape 不匹配。 - 删除一个
3 x 3卷积会降低参数量和非线性层数;如果 padding/stride 不变,空间尺寸通常不变。 out + identity是逐元素相加,两个 tensor 必须形状一致。通道数不同需要 projection 或1 x 1卷积对齐。- 现代 CNN 仍常使用局部卷积、通道扩张、归一化、残差连接、GAP head 等经典思想。
- 经典 CNN 是设计演进,不是模型名字列表。
- LeNet 给出骨架;AlexNet 证明规模;VGG 让重复小 block 变得清晰;ResNet 让深度更容易训练。
- 堆叠小 kernel 可以兼顾参数效率和表达力。
- 残差连接保留信息并改善优化。
- 真正实用的能力,是读懂架构背后的设计动机。