8.4.3 API 设计与服务化
- 理解一个 LLM 服务 API 最基本应该定义哪些内容
- 学会设计清晰的请求和响应结构
- 理解幂等性、错误返回、追踪_id、版本管理这些服务化关键概念
- 看懂一个最小 API 处理闭环
API 设计会难,很多时候不是代码难,而是这些词没建立直觉:
| 术语 | 新人理解 | 在本节里的作用 |
|---|---|---|
API | Application Programming Interface,应用程序接口,也就是一个程序稳定调用另一个程序的方式 | 其他代码依赖的服务入口 |
endpoint | 具体可调用的地址,比如 /api/v1/chat | 把某个能力暴露成 URL 路径 |
schema | 规定哪些字段允许出现、哪些字段必须出现的规则 | 让请求和响应结构可预测 |
payload | 请求里携带的数据主体 | 在本节里通常是用户问题和相关元数据 |
trace_id | 追踪一条请求的唯一 ID | 把 API 日志、检索日志、模型日志和错误串起来 |
idempotency | 幂等性,同一个请求重复调用不会产生失控副作用 | 超时或网络失败后重试时尤其重要 |
不要只把它们当成术语背下来。真实系统里,这些词对应的是前端、后端、日志、评估和部署能够协作的关键零件。
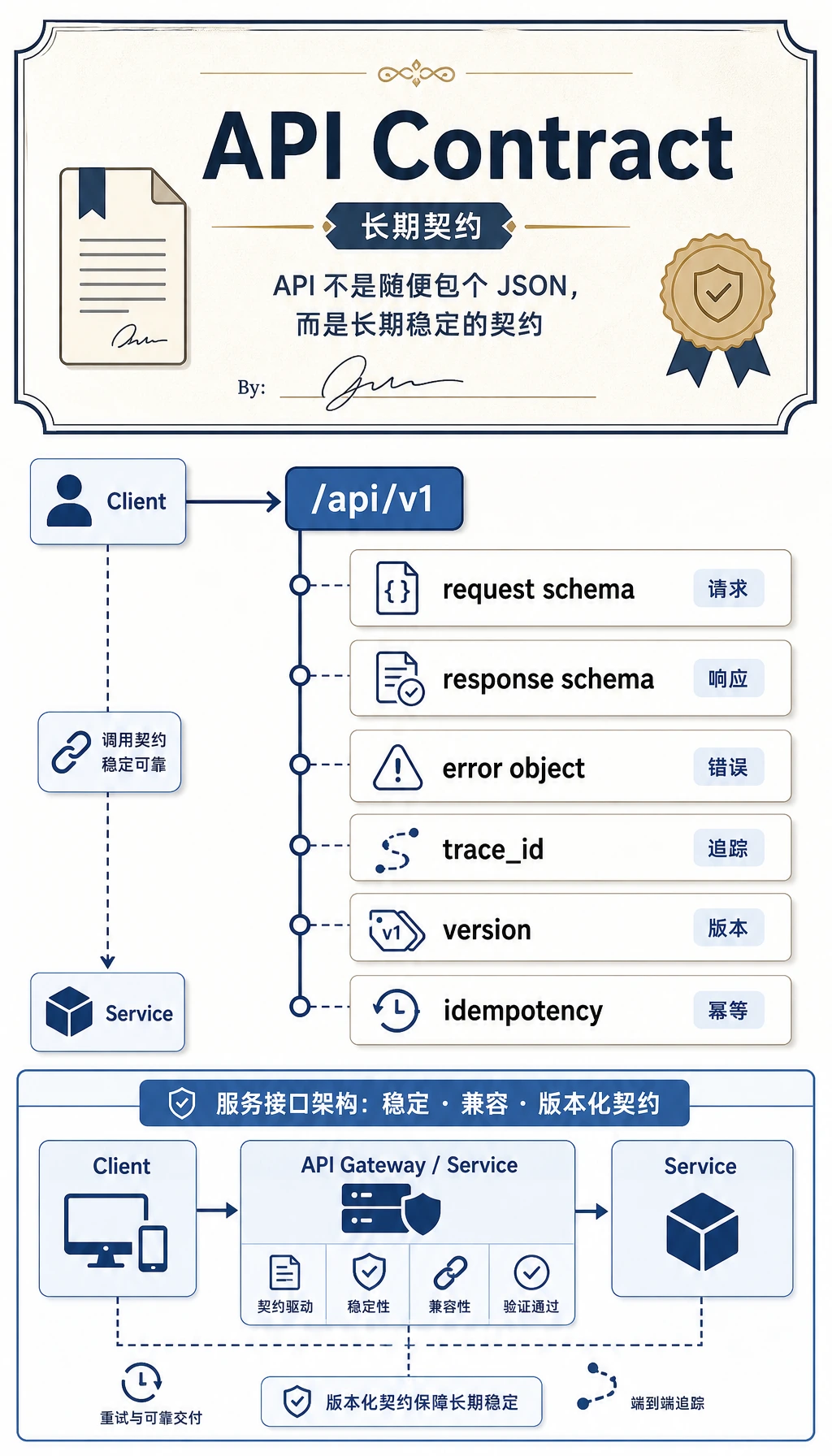
为什么 API 设计不是“随便包个 JSON”?
Section titled “为什么 API 设计不是“随便包个 JSON”?”一个差的接口长什么样?
Section titled “一个差的接口长什么样?”bad_request = { "msg": "退款政策是什么"}
bad_response = { "text": "7 天内可退款"}问题在哪?
msg是什么?用户消息?系统消息?- 没有 追踪_id
- 没有错误结构
- 没有版本信息
- 没有上下文字段
一个好的 API 设计在做什么?
Section titled “一个好的 API 设计在做什么?”本质上它在回答:
- 输入长什么样
- 输出长什么样
- 错了时怎么表示
- 调一次和调十万次还能不能稳定
也就是说,API 设计不是“写个入口”,而是在定义:
系统和外部世界的契约。
先设计请求结构
Section titled “先设计请求结构”最小请求结构通常至少要有这些
Section titled “最小请求结构通常至少要有这些”queryuser_id(可选)session_id(多轮时)metadata(可选)
一个更清楚的请求对象
Section titled “一个更清楚的请求对象”request = { "query": "退款政策是什么?", "user_id": 1, "session_id": "sess_001", "metadata": { "channel": "web" }}
print(request)预期输出:
{'query': '退款政策是什么?', 'user_id': 1, 'session_id': 'sess_001', 'metadata': {'channel': 'web'}}这里你已经能感受到:
- 查询内容是什么
- 谁发来的
- 属于哪个会话
- 额外上下文是什么
这就比“只传一段字符串”强很多。
再设计响应结构
Section titled “再设计响应结构”为什么响应也必须规范?
Section titled “为什么响应也必须规范?”因为真实调用方往往不只是人,还有:
- 前端
- 其他服务
- 日志系统
- 评估系统
它们都需要稳定消费返回结果。
一个更稳的响应结构
Section titled “一个更稳的响应结构”response = { "trace_id": "trace_001", "answer": "课程购买后 7 天内且学习进度低于 20% 可申请退款。", "sources": [ {"id": "doc_001", "section": "退款政策"} ], "usage": { "prompt_tokens": 120, "completion_tokens": 35 }}
print(response)预期输出:
{'trace_id': 'trace_001', 'answer': '课程购买后 7 天内且学习进度低于 20% 可申请退款。', 'sources': [{'id': 'doc_001', 'section': '退款政策'}], 'usage': {'prompt_tokens': 120, 'completion_tokens': 35}}为什么这几个字段有价值?
Section titled “为什么这几个字段有价值?”trace_id:方便追踪链路answer:真正的业务输出sources:便于引用和校验usage:便于成本分析
错误响应也必须设计
Section titled “错误响应也必须设计”很多系统只设计成功返回
Section titled “很多系统只设计成功返回”但工程里更常见的问题其实是:
- 参数不合法
- 上游超时
- 权限不足
- 知识库为空
一个统一错误结构
Section titled “一个统一错误结构”error_response = { "trace_id": "trace_002", "error": { "code": "INVALID_ARGUMENT", "message": "query 不能为空" }}
print(error_response)预期输出:
{'trace_id': 'trace_002', 'error': {'code': 'INVALID_ARGUMENT', 'message': 'query 不能为空'}}这一步非常重要,因为它让调用方明确知道:
- 发生了什么错
- 错误类别是什么
- 是否值得重试
一个最小可运行的服务化处理函数
Section titled “一个最小可运行的服务化处理函数”用纯 Python 先模拟 API handler
Section titled “用纯 Python 先模拟 API handler”def handle_chat(request): trace_id = "trace_demo_001"
if "query" not in request or not request["query"].strip(): return { "trace_id": trace_id, "error": { "code": "INVALID_ARGUMENT", "message": "query 不能为空" } }
answer = f"系统回复:{request['query']}" return { "trace_id": trace_id, "answer": answer, "sources": [], "usage": {"prompt_tokens": 12, "completion_tokens": 8} }
print(handle_chat({"query": "退款政策是什么?"}))print(handle_chat({"query": ""}))预期输出:
{'trace_id': 'trace_demo_001', 'answer': '系统回复:退款政策是什么?', 'sources': [], 'usage': {'prompt_tokens': 12, 'completion_tokens': 8}}{'trace_id': 'trace_demo_001', 'error': {'code': 'INVALID_ARGUMENT', 'message': 'query 不能为空'}}这段代码其实在教什么?
Section titled “这段代码其实在教什么?”它在教你:
- 请求先校验
- 每次请求都有 追踪_id
- 成功和失败都要有统一结构
这已经是服务化设计最核心的一层了。
幂等性为什么重要?
Section titled “幂等性为什么重要?”什么是幂等性?
Section titled “什么是幂等性?”简单理解:
同一个请求重复调用多次,结果应该保持一致或可控。
这在这些场景特别重要:
- 重试
- 超时后重新发起
- 网络抖动
哪些接口更要考虑幂等性?
Section titled “哪些接口更要考虑幂等性?”尤其是:
- 工单创建
- 支付发起
- 订单变更
而纯问答接口通常天然更像“只读操作”,幂等性更容易做。
版本管理为什么不能后补?
Section titled “版本管理为什么不能后补?”API 一旦被别人接入,就很难随便改字段
Section titled “API 一旦被别人接入,就很难随便改字段”如果今天返回:
answer
明天改成:
response_text
调用方就会直接挂。
一个简单版本策略
Section titled “一个简单版本策略”api_info = { "version": "v1", "endpoint": "/api/v1/chat"}
print(api_info)预期输出:
{'version': 'v1', 'endpoint': '/api/v1/chat'}哪怕是最小项目,也建议早点有版本意识。
一个更接近真实服务的 FastAPI 例子
Section titled “一个更接近真实服务的 FastAPI 例子”如果你想看更贴近真实后端的写法,可以看下面这个最小版本。
from fastapi import FastAPIfrom pydantic import BaseModel, Field
class ChatRequest(BaseModel): query: str = Field(min_length=1) session_id: str | None = None
app = FastAPI()
@app.post("/api/v1/chat")def chat(payload: ChatRequest): return { "trace_id": "trace_demo_002", "answer": f"系统回复:{payload.query}", "session_id": payload.session_id, }这段代码虽然简单,但比直接接收 dict 更接近真实服务,因为 ChatRequest 是请求 schema。FastAPI 会在业务逻辑运行前先校验 payload。真实生产环境里,你通常还会继续补认证、统一错误、日志记录和真正的 trace_id 生成器。
如果你的目标是“知识库驱动的 SOP 文档助手”,API 最小接口应该长什么样?
Section titled “如果你的目标是“知识库驱动的 SOP 文档助手”,API 最小接口应该长什么样?”这类系统通常不只需要一个 /chat,
而更像至少有下面几类接口:
| 接口 | 它在负责什么 |
|---|---|
/sop-drafts/generate | 根据政策、案例和检查清单证据生成结构化 SOP 草稿 |
/sop-drafts/preview | 导出前预览结构化 SOP 章节 |
/documents/ingest | 上传并解析 PDF / Word / PPT |
/retrieval/search | 调试检索结果 |
第一次做时,更稳的默认做法通常是:
- 先只做一个
generate - 先返回结构化结果或导出链接
- 再补调试接口和批量接口
一个很小的请求结构可以先定成:
generate_request = { "topic": "退款升级 SOP", "audience": "一线客服", "doc_format": "word", "case_count": 2, "checklist_required": True,}
print(generate_request)预期输出:
{'topic': '退款升级 SOP', 'audience': '一线客服', 'doc_format': 'word', 'case_count': 2, 'checklist_required': True}这个对象的价值在于:
- 它把多轮对话里收集到的槽位,真正落成了服务接口参数
动手做:模拟 SOP 草稿 API 契约
Section titled “动手做:模拟 SOP 草稿 API 契约”在真正写 FastAPI endpoint 之前,先用纯 Python 把请求校验和响应契约写出来。这样服务边界会更清楚。
REQUIRED_FIELDS = ["topic", "audience", "doc_format", "case_count", "checklist_required"]
def validate_generate_request(payload): missing = [field for field in REQUIRED_FIELDS if field not in payload or payload.get(field) is None] if missing: return False, { "code": "INVALID_ARGUMENT", "message": f"缺少字段:{missing}" } if payload["doc_format"] not in {"word", "ppt"}: return False, { "code": "INVALID_ARGUMENT", "message": "doc_format 必须是 word 或 ppt" } return True, None
def handle_generate(payload): trace_id = "trace_sop_001" ok, error = validate_generate_request(payload) if not ok: return {"trace_id": trace_id, "error": error}
return { "trace_id": trace_id, "status": "accepted", "sop_draft": { "title": payload["topic"], "audience": payload["audience"], "format": payload["doc_format"], "sections": ["政策摘要", "已处理案例", "一线客服检查清单"], } }
generate_request = { "topic": "退款升级 SOP", "audience": "一线客服", "doc_format": "word", "case_count": 2, "checklist_required": True,}
print(handle_generate(generate_request))print(handle_generate({"topic": "退款升级 SOP", "doc_format": "pdf"}))预期输出:
{'trace_id': 'trace_sop_001', 'status': 'accepted', 'sop_draft': {'title': '退款升级 SOP', 'audience': '一线客服', 'format': 'word', 'sections': ['政策摘要', '已处理案例', '一线客服检查清单']}}{'trace_id': 'trace_sop_001', 'error': {'code': 'INVALID_ARGUMENT', 'message': "缺少字段:['audience', 'case_count', 'checklist_required']"}}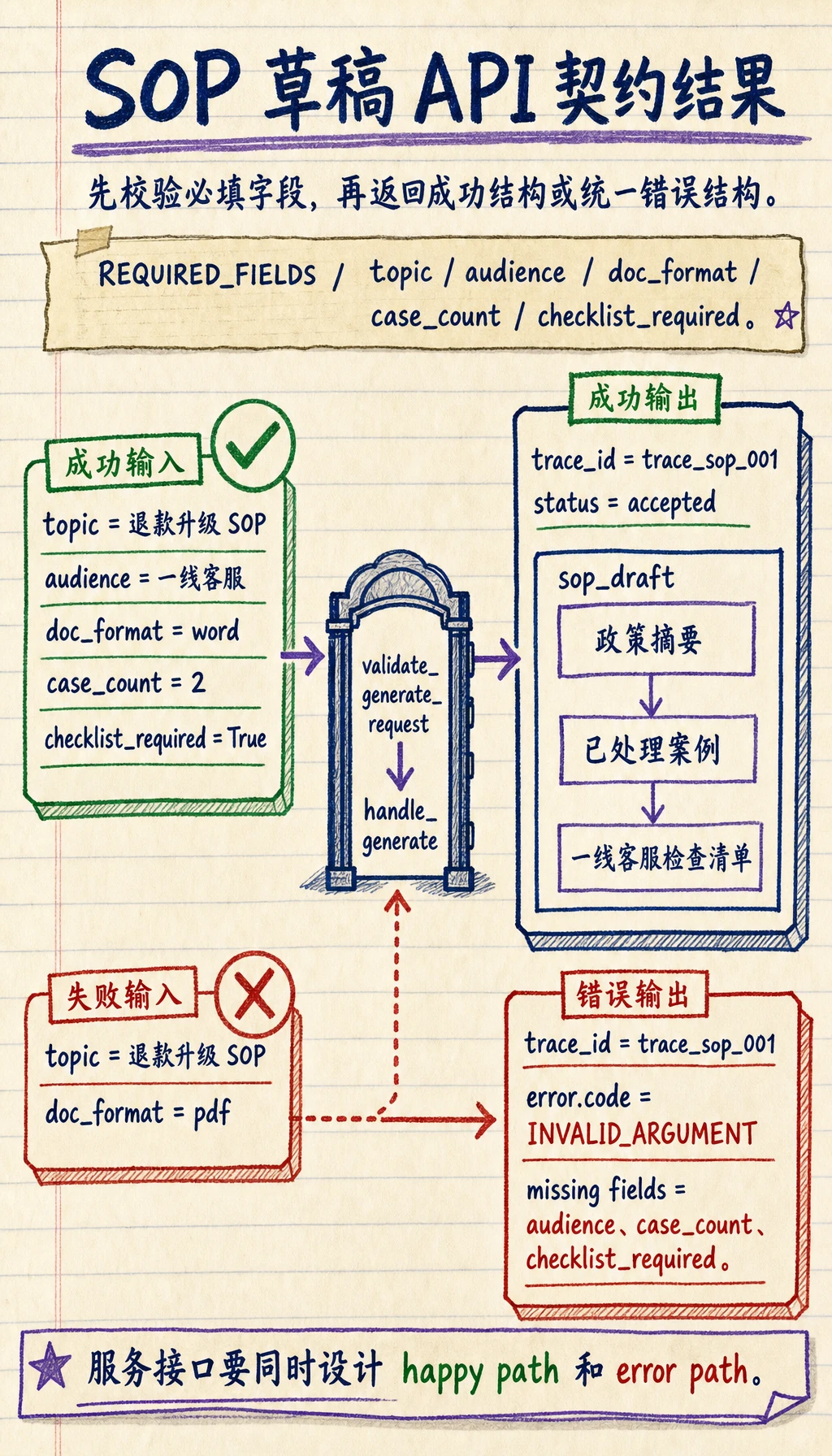
这个练习有用,是因为它逼你同时设计成功和失败。服务不是只会返回成功路径就算准备好了。
初学者最常踩的坑
Section titled “初学者最常踩的坑”请求结构太随意
Section titled “请求结构太随意”一开始省事,后面会非常痛苦。
错误结构不统一
Section titled “错误结构不统一”这会让前端和其他服务越来越难接。
没有 追踪_id
Section titled “没有 追踪_id”出了问题很难追链路。
一开始就把接口绑死在单一业务逻辑上
Section titled “一开始就把接口绑死在单一业务逻辑上”这样后面扩展非常困难。
什么时候先不要急着服务化?
Section titled “什么时候先不要急着服务化?”API 是长期契约,不是演示脚本的外壳。下面这些情况,先不要急着发布接口:
| 情况 | 为什么先缓一缓 |
|---|---|
| 输入输出还在频繁变化 | 过早发布会让调用方反复适配 |
| 错误结构还没统一 | 前端和其他服务无法稳定处理失败 |
| 没有 trace_id 和日志 | 出错后无法追 RAG、模型和工具链路 |
| 没有固定评估样本 | 接口看似稳定,但行为变化不可比较 |
先用脚本和少量样本把能力跑稳,再把稳定契约暴露成 API。服务化的价值是让别人可靠调用,而不是把不稳定逻辑藏到 URL 后面。
学完这一页,至少保留这张证据卡:
- 服务契约
- 端点、输入模式、输出模式、错误模式
- 运行信号
- 延迟、吞吐量、日志、健康检查,或容器状态
- 可观测性
- 请求 ID、trace ID、结构化日志或指标
- 失败检查
- 超时、重试风暴、缺少日志或部署不匹配
- 运维动作
- backoff、queue、alert、rollout 或 rollback
这一节最重要的不是把接口跑起来,而是理解:
API 设计的核心,是让输入、输出、错误和链路追踪都变成稳定的系统契约。
一旦契约清楚,服务才能真正长期稳定地被别人依赖。
- 给
handle_chat()增加一个session_id字段支持。 - 设计一个统一的错误码枚举,比如
INVALID_ARGUMENT、TIMEOUT、NOT_FOUND。 - 想一想:如果这是一个“创建工单”接口,你会怎样考虑幂等性?
- 用自己的话解释:为什么说 API 设计本质上是在定义系统契约?
参考实现与讲解
session_id应贯穿请求解析、状态查询、日志和响应 trace,并校验空值或格式错误。- 错误码枚举让客户端能稳定处理错误,也能区分用户错误和服务错误。
- 幂等键可以避免客户端超时重试时重复创建工单。
- API 契约定义输入、输出、错误、权限、时间预期和兼容性。