4.3.5 链式法则与反向传播预览
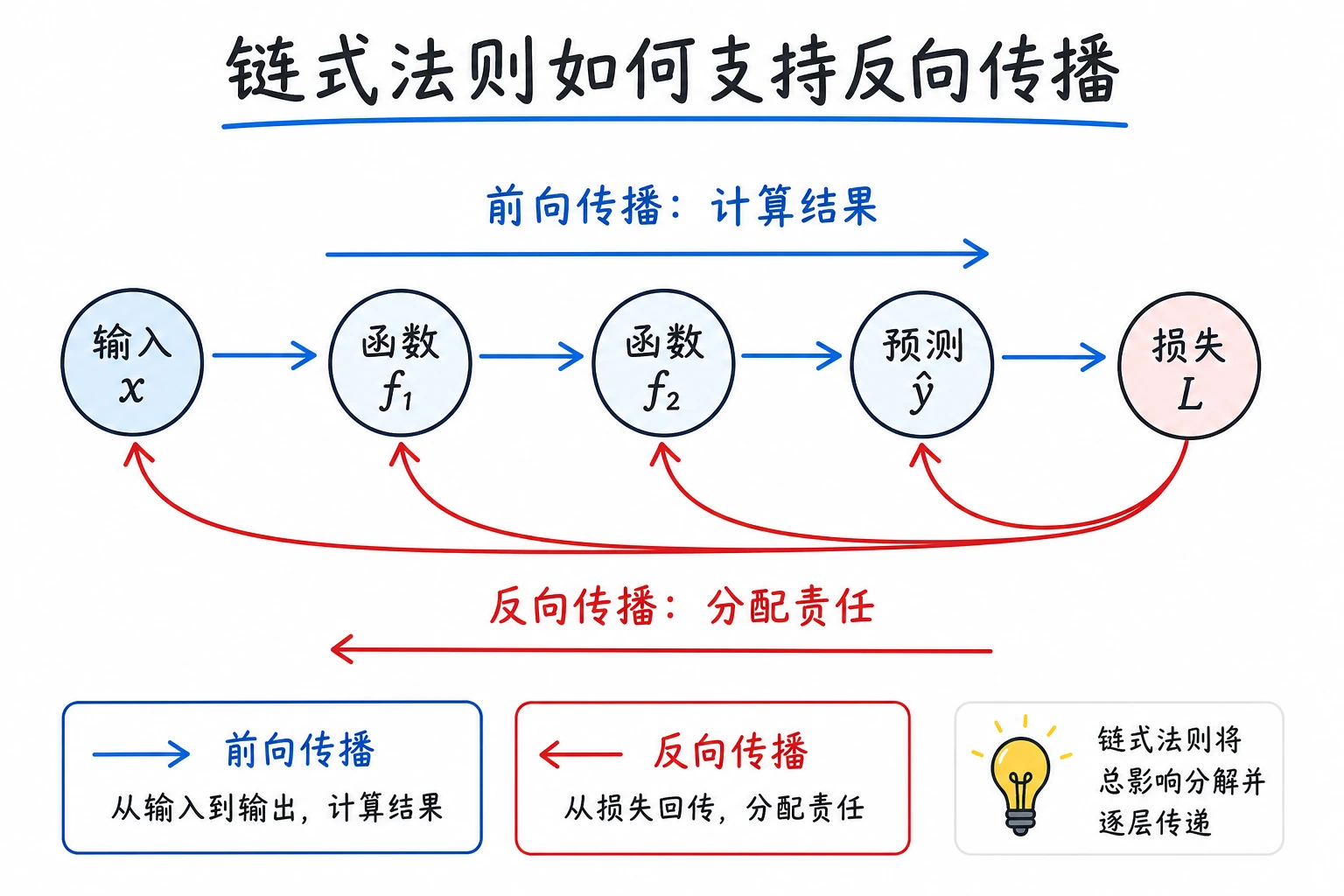
- 理解链式法则——复合函数怎么求导
- 用简单的两层网络手动推导反向传播
- 理解计算图——为什么 PyTorch 需要它
- 为第 6 站的深度学习做好准备
先说一个很重要的学习预期
Section titled “先说一个很重要的学习预期”这一节是第 4 站里最容易一下子让新人发虚的地方。 所以你这一节最先要抓住的,不是每条公式,而是:
- 复杂网络也只是很多简单步骤串起来
- 反向传播不是神秘算法,而是在一层层应用链式法则
- PyTorch 的
backward()本质上只是在帮你自动做这件事
先建立一张地图
Section titled “先建立一张地图”这节课是第 4 站通向第 6 站深度学习的桥。
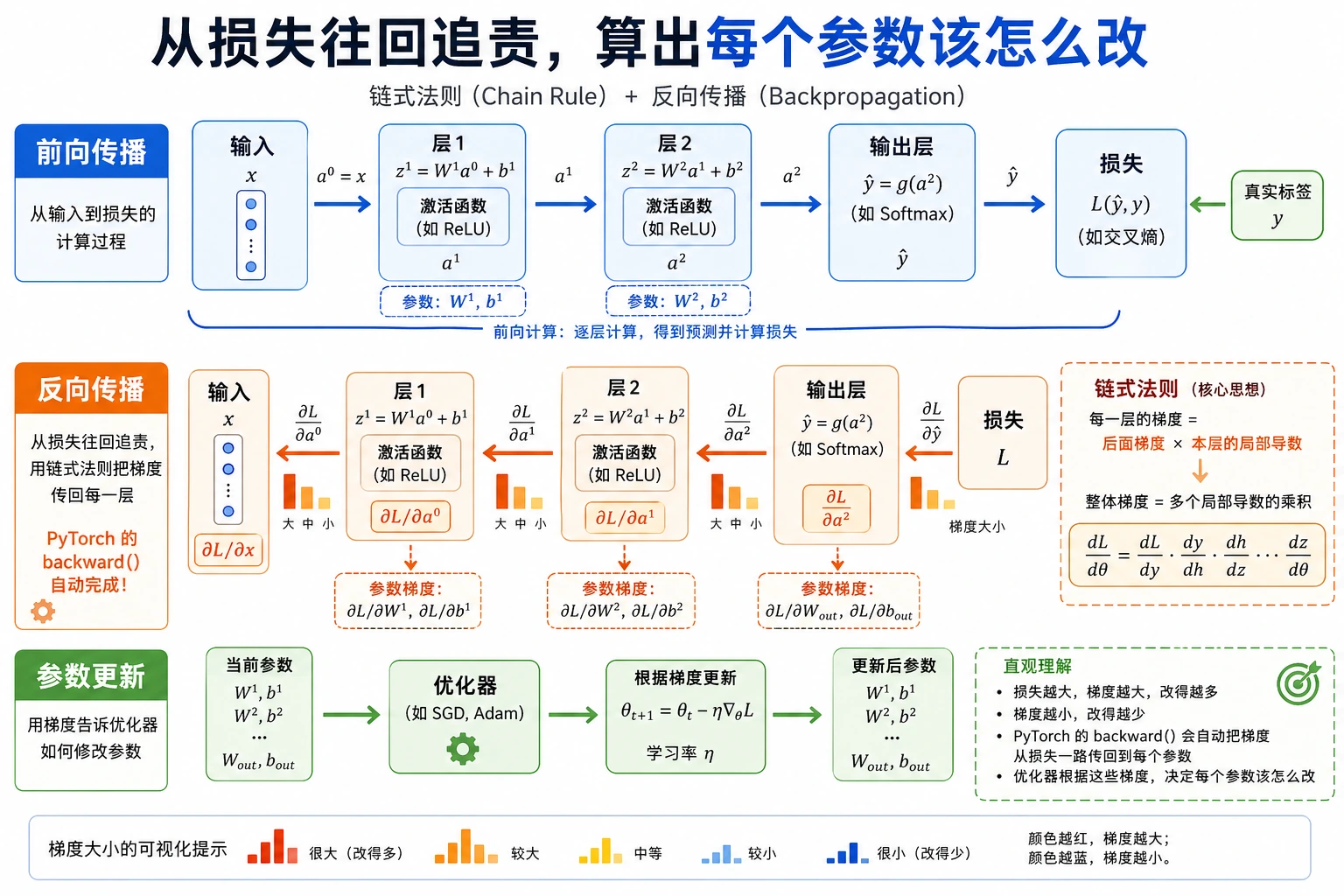
如果前面你学的是:
- 导数:一个量怎么变
- 梯度:很多量一起怎么变
- 梯度下降:怎样更新参数
那这节课要补上的就是:
- 在一个很多层的网络里,梯度到底怎么一层层算回来
一、链式法则——“洋葱剥皮法”
Section titled “一、链式法则——“洋葱剥皮法””如果一个函数是”套娃”结构——外面套外面,那它的导数就是一层一层剥开,每层的导数乘起来。
flowchart LR X["x"] -->|"g(x)"| U["u = g(x)"] U -->|"f(u)"| Y["y = f(g(x))"]
style X fill:#e3f2fd,stroke:#1565c0,color:#333 style U fill:#fff3e0,stroke:#e65100,color:#333 style Y fill:#e8f5e9,stroke:#2e7d32,color:#333链式法则:dy/dx = (dy/du) × (du/dx)
“y 对 x 的变化率 = y 对 u 的变化率 × u 对 x 的变化率”
一个更适合新人的类比
Section titled “一个更适合新人的类比”你可以把链式法则先想成一排齿轮:
- 第一个齿轮动一点
- 会带着第二个齿轮动
- 第二个又带着第三个动
所以最后一个量怎么变, 取决于中间每一层“传递变化”的倍率。
这就是为什么链式法则的核心动作是:
- 一层一层往里拆
- 一层一层把变化率乘起来
你的工资涨了 10%,物价涨了 5%,你的实际购买力变了多少?
- 工资变化 → 影响钱包 → 影响购买力
- 总变化 = 工资变化率 × 转换率
每一环节的变化率相乘 = 总的变化率。
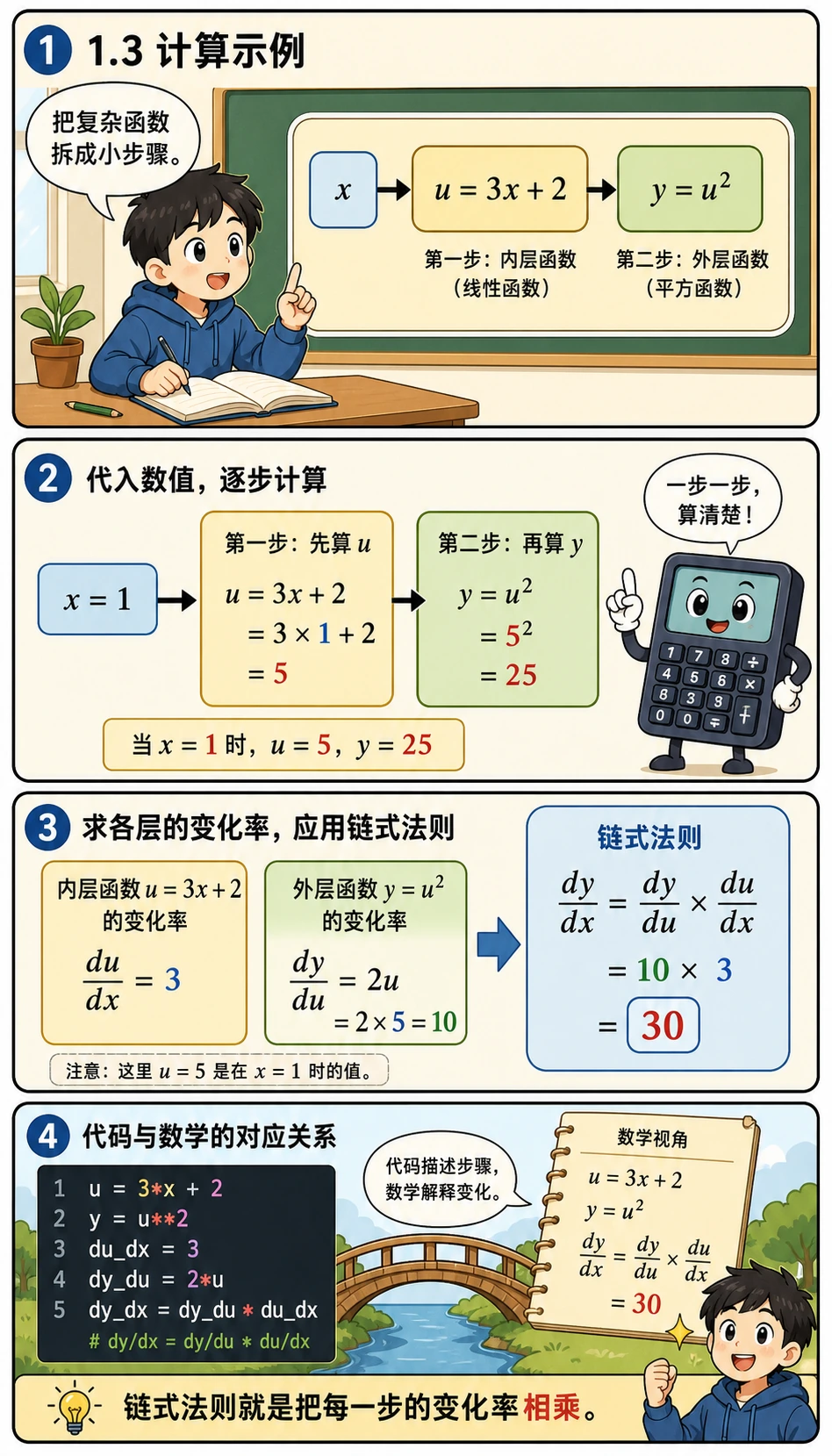
先别急着看代码,把这个例子想成一条小流水线:
u = 3x + 2是内层步骤,它告诉我们x变一点时,u怎么变y = u²是外层步骤,它告诉我们u变一点时,y怎么变dy_dx表示“原始输入x变一点,最终输出y会变多少”numerical_derivative是安全检查:让x向左、向右各挪一小点,用差值估算斜率
所以下面的代码不是只在算答案,而是在用三种方式讲同一件事:拆函数、套公式、做数值验证。
import numpy as np
# 例子:y = (3x + 2)²# 分解:u = 3x + 2, y = u²# dy/dx = dy/du × du/dx = 2u × 3 = 6(3x + 2)
# 方法 1:链式法则def chain_rule_example(x): u = 3 * x + 2 # 内函数 y = u ** 2 # 外函数
du_dx = 3 # 内函数的导数 dy_du = 2 * u # 外函数的导数 dy_dx = dy_du * du_dx # 链式法则
return y, dy_dx
# 方法 2:数值验证def numerical_derivative(f, x, h=1e-7): return (f(x + h) - f(x - h)) / (2 * h)
f = lambda x: (3*x + 2)**2
x0 = 1y, dy_dx_chain = chain_rule_example(x0)dy_dx_numerical = numerical_derivative(f, x0)
print(f"x = {x0}")print(f" 链式法则: dy/dx = {dy_dx_chain}")print(f" 数值验证: dy/dx = {dy_dx_numerical:.4f}")多层链式法则
Section titled “多层链式法则”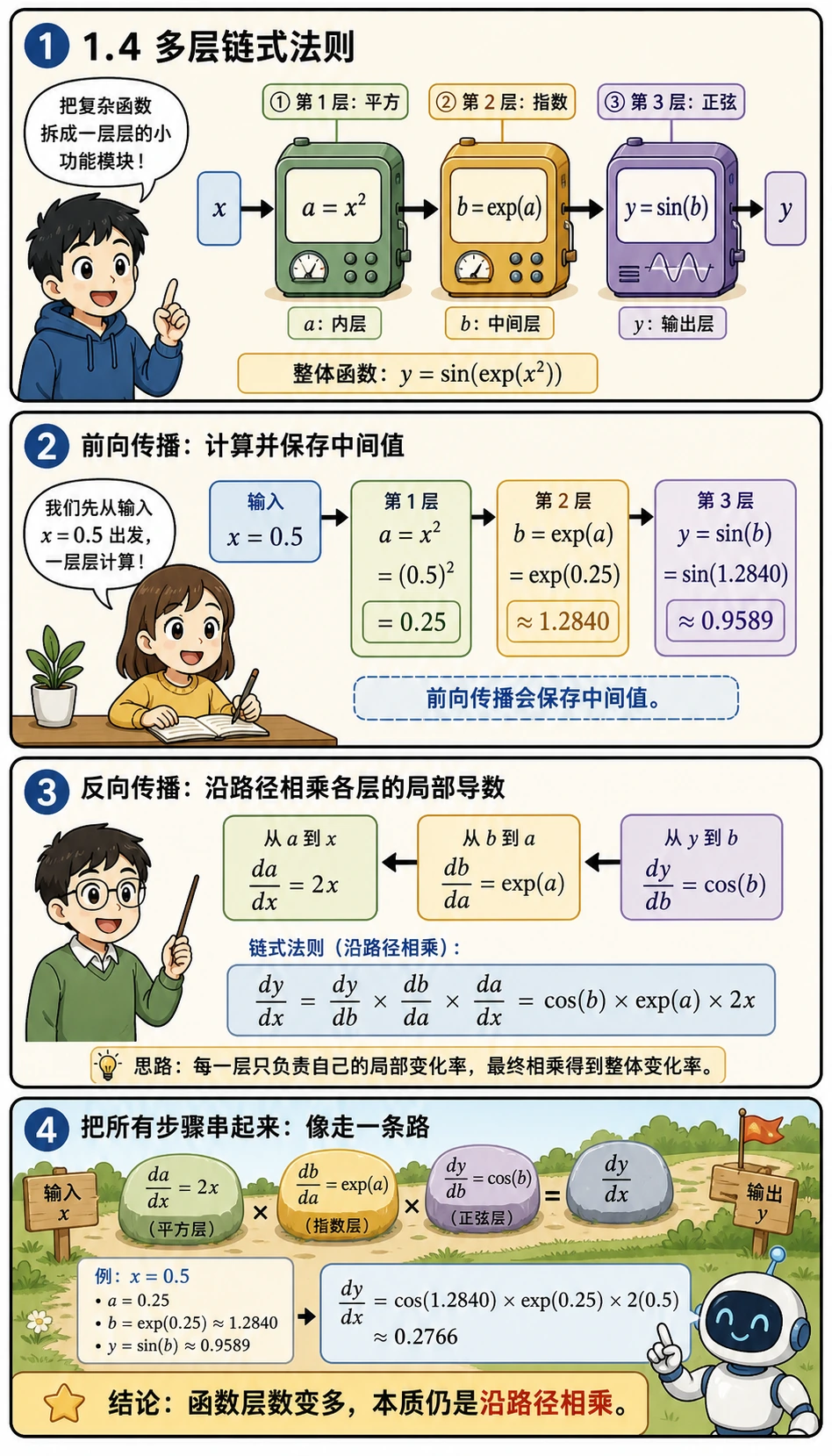
如果有更多层嵌套呢?照样一层层剥:
- 先做前向计算:得到
a,再得到b,最后得到y - 再计算每一步的局部导数:
da_dx、db_da、dy_db - 最后沿着从输出回到输入的路径,把这些导数乘起来
这就是以后看神经网络时最重要的心智模型:深层模型只是路径更长,并不是换了一种完全陌生的数学。
# y = sin(exp(x²))# 分解:a = x², b = exp(a), y = sin(b)# dy/dx = dy/db × db/da × da/dx# = cos(b) × exp(a) × 2x
x0 = 0.5a = x0 ** 2b = np.exp(a)y = np.sin(b)
da_dx = 2 * x0db_da = np.exp(a)dy_db = np.cos(b)
dy_dx = dy_db * db_da * da_dx
# 数值验证f = lambda x: np.sin(np.exp(x**2))dy_dx_num = numerical_derivative(f, x0)
print(f"链式法则: {dy_dx:.6f}")print(f"数值验证: {dy_dx_num:.6f}")二、反向传播——链式法则的系统化
Section titled “二、反向传播——链式法则的系统化”一个两层神经网络
Section titled “一个两层神经网络”flowchart LR X["输入 x"] --> H["隐藏层<br/>h = relu(w1·x + b1)"] H --> O["输出层<br/>y = w2·h + b2"] O --> L["损失<br/>L = (y - target)²"]
style X fill:#e3f2fd,stroke:#1565c0,color:#333 style H fill:#fff3e0,stroke:#e65100,color:#333 style O fill:#fff3e0,stroke:#e65100,color:#333 style L fill:#ffebee,stroke:#c62828,color:#333前向传播(Forward Pass)
Section titled “前向传播(Forward Pass)”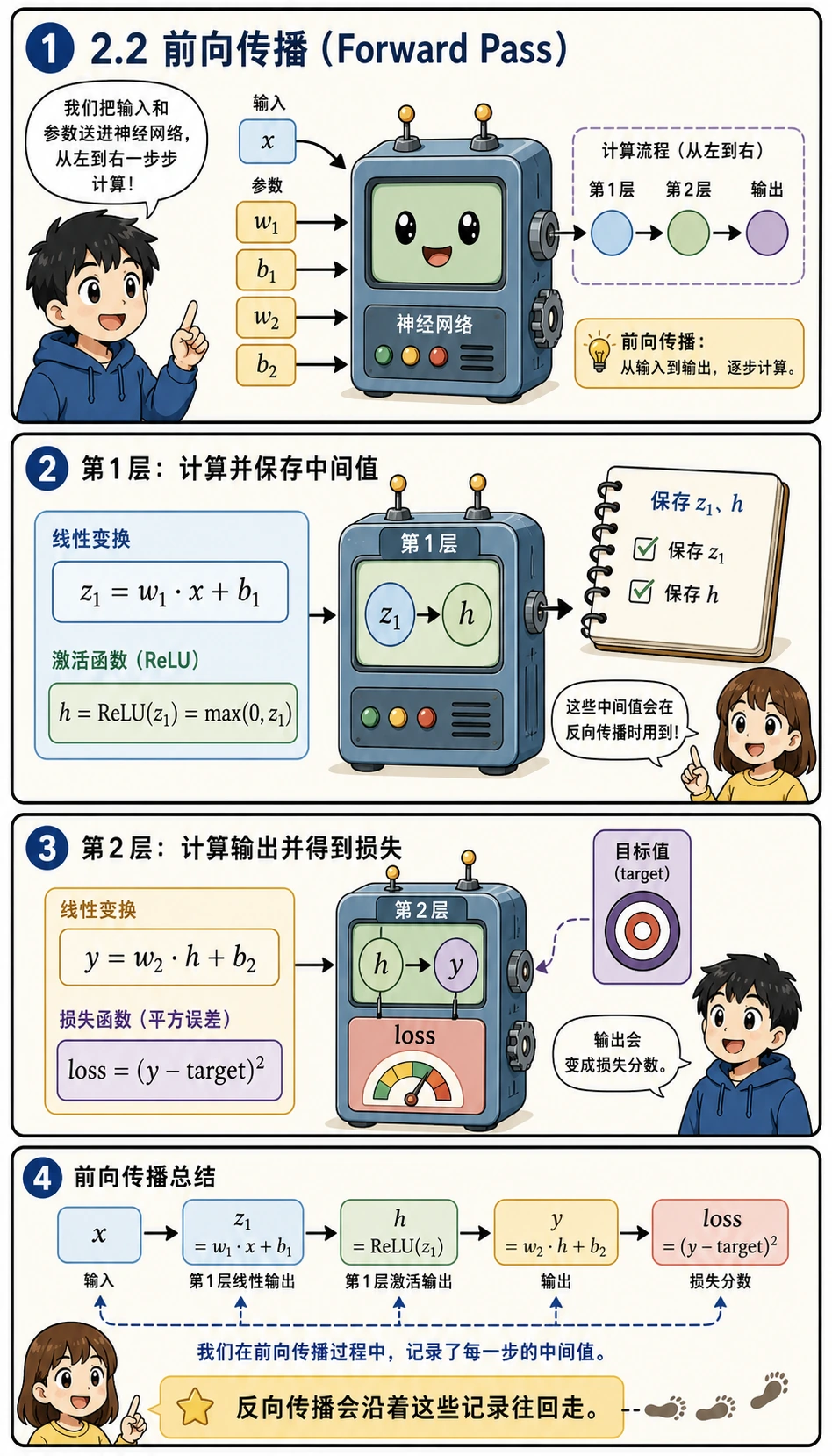
前向传播就是“从输入开始,算到预测,再算到损失”。在这个小网络里,模型大小不是重点,重点是养成保存中间值的习惯:
z1是进入激活函数之前的结果h是经过ReLU之后的隐藏表示y是模型预测loss衡量预测错了多少
这些值就是反向传播要沿路返回时用到的“面包屑”。
# 输入和目标x = 2.0target = 1.0
# 参数w1 = 0.5b1 = 0.1w2 = -0.3b2 = 0.2
# --- 前向传播 ---# 第 1 层:线性 + ReLUz1 = w1 * x + b1h = max(0, z1) # ReLU
# 第 2 层:线性y = w2 * h + b2
# 损失loss = (y - target) ** 2
print("=== 前向传播 ===")print(f"z1 = w1*x + b1 = {w1}*{x} + {b1} = {z1}")print(f"h = ReLU(z1) = {h}")print(f"y = w2*h + b2 = {w2}*{h} + {b2} = {y}")print(f"loss = (y - target)² = ({y} - {target})² = {loss:.4f}")为什么一定要先算前向,再谈反向?
Section titled “为什么一定要先算前向,再谈反向?”因为反向传播不是凭空发生的。 它必须建立在前向传播已经把这些中间量算出来的基础上:
z1hyloss
所以一个很稳的理解方式是:
- 前向是在把路径铺出来
- 反向是在沿着这条路径把梯度一层层传回来
反向传播(Backward Pass)
Section titled “反向传播(Backward Pass)”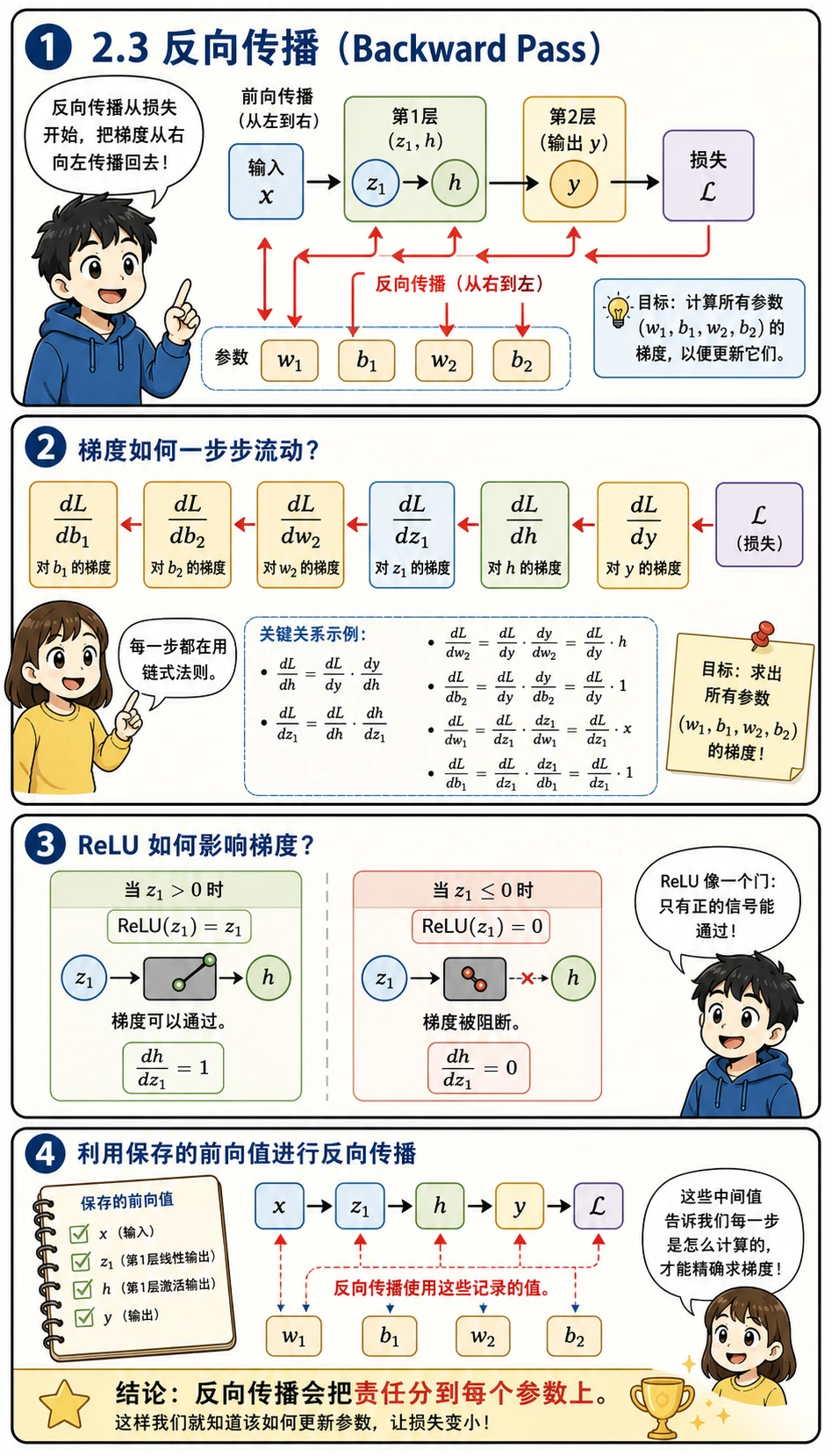
从损失开始,逐层往回算每个参数的梯度:
像 dL_dw1 这样的符号,可以读成“损失 L 对参数 w1 有多敏感”。绝对值越大,说明这个参数一变,损失就会明显变化;接近 0,则说明这个参数当前影响不大。
所以反向传播可以理解成一个“分配责任”的过程:
- 从损失开始
- 先问损失如何依赖输出
- 再问输出如何依赖更早的值
- 不断乘上每一步的局部导数,直到每个参数都拿到自己的梯度
其中 ReLU 这一关尤其重要:如果 z1 <= 0,这条路径上的梯度就会变成 0。
# --- 反向传播 ---# 从最后一层开始,用链式法则一层层往回算
# dL/dydL_dy = 2 * (y - target)print(f"\n=== 反向传播 ===")print(f"dL/dy = 2*(y-target) = {dL_dy:.4f}")
# dL/dw2 = dL/dy × dy/dw2 = dL/dy × hdL_dw2 = dL_dy * hprint(f"dL/dw2 = dL/dy × h = {dL_dy:.4f} × {h} = {dL_dw2:.4f}")
# dL/db2 = dL/dy × dy/db2 = dL/dy × 1dL_db2 = dL_dy * 1print(f"dL/db2 = dL/dy × 1 = {dL_db2:.4f}")
# dL/dh = dL/dy × dy/dh = dL/dy × w2dL_dh = dL_dy * w2print(f"dL/dh = dL/dy × w2 = {dL_dy:.4f} × {w2} = {dL_dh:.4f}")
# dL/dz1 = dL/dh × dh/dz1(ReLU 的导数:z1>0 时为 1,否则为 0)relu_grad = 1.0 if z1 > 0 else 0.0dL_dz1 = dL_dh * relu_gradprint(f"dL/dz1 = dL/dh × relu'(z1) = {dL_dh:.4f} × {relu_grad} = {dL_dz1:.4f}")
# dL/dw1 = dL/dz1 × dz1/dw1 = dL/dz1 × xdL_dw1 = dL_dz1 * xprint(f"dL/dw1 = dL/dz1 × x = {dL_dz1:.4f} × {x} = {dL_dw1:.4f}")
# dL/db1 = dL/dz1 × dz1/db1 = dL/dz1 × 1dL_db1 = dL_dz1 * 1print(f"dL/db1 = dL/dz1 × 1 = {dL_db1:.4f}")用梯度更新参数
Section titled “用梯度更新参数”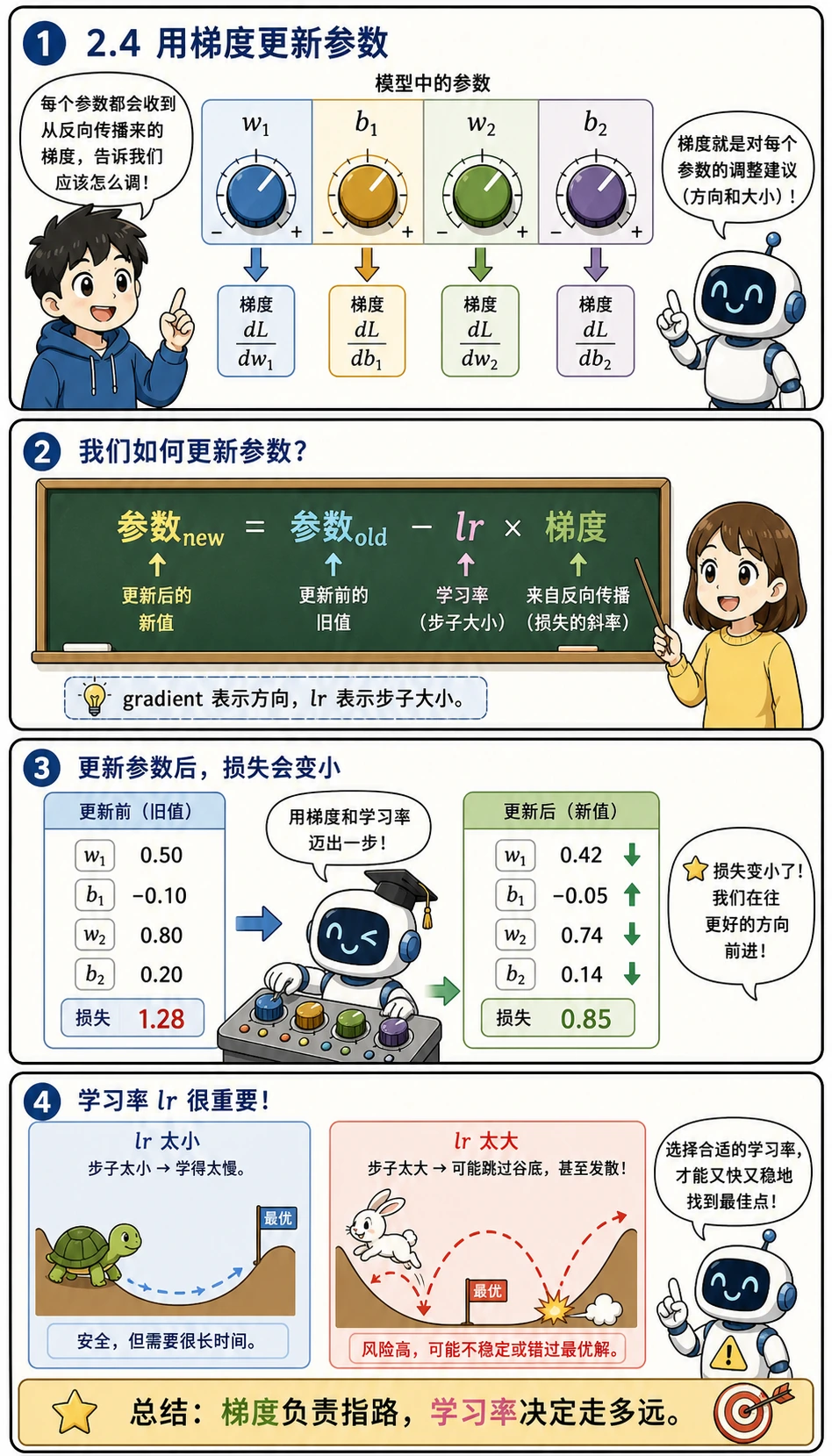
反向传播算出的梯度不是终点。它们是“参数应该怎么改”的指令。
更新规则是:
新参数 = 旧参数 - 学习率 × 梯度lr 是 learning rate(学习率),控制每次更新走多大一步。lr 太小,学习会很慢;lr 太大,可能直接越过好位置,让损失反而变大。
lr = 0.1
print(f"\n=== 参数更新 (lr={lr}) ===")print(f"w1: {w1:.4f} → {w1 - lr * dL_dw1:.4f}")print(f"b1: {b1:.4f} → {b1 - lr * dL_db1:.4f}")print(f"w2: {w2:.4f} → {w2 - lr * dL_dw2:.4f}")print(f"b2: {b2:.4f} → {b2 - lr * dL_db2:.4f}")
# 更新w1 -= lr * dL_dw1b1 -= lr * dL_db1w2 -= lr * dL_dw2b2 -= lr * dL_db2
# 验证损失减小了z1_new = w1 * x + b1h_new = max(0, z1_new)y_new = w2 * h_new + b2loss_new = (y_new - target) ** 2
print(f"\n损失变化: {loss:.4f} → {loss_new:.4f} ({'↓ 减小了!' if loss_new < loss else '↑ 增大了'})")三、计算图——反向传播的数据结构
Section titled “三、计算图——反向传播的数据结构”什么是计算图?
Section titled “什么是计算图?”计算图 = 把每一步运算画成一个节点的有向图。
flowchart LR x["x = 2"] --> mul1["× w1"] w1["w1 = 0.5"] --> mul1 mul1 --> add1["+ b1"] b1["b1 = 0.1"] --> add1 add1 --> relu["ReLU"] relu --> mul2["× w2"] w2["w2 = -0.3"] --> mul2 mul2 --> add2["+ b2"] b2["b2 = 0.2"] --> add2 add2 --> sub["- target"] sub --> sq["²"] sq --> L["Loss"]
style x fill:#e3f2fd,stroke:#1565c0,color:#333 style L fill:#ffebee,stroke:#c62828,color:#333前向传播:沿箭头方向计算,从输入算到损失。
反向传播:逆着箭头方向,从损失算回每个参数的梯度。
为什么计算图会让这件事突然变清楚?
Section titled “为什么计算图会让这件事突然变清楚?”因为它把“复杂网络”还原成了很多个小节点:
- 乘法
- 加法
- 激活
- 损失
一旦你把网络看成这些节点串起来的图, 反向传播就不再像魔法,而更像:
- 沿着图把梯度一层层传回去
为什么 PyTorch 需要计算图?
Section titled “为什么 PyTorch 需要计算图?”# 在 PyTorch 中(第 6 站会详细学)# import torch## x = torch.tensor(2.0)# w1 = torch.tensor(0.5, requires_grad=True)# b1 = torch.tensor(0.1, requires_grad=True)# w2 = torch.tensor(-0.3, requires_grad=True)# b2 = torch.tensor(0.2, requires_grad=True)## # 前向传播(PyTorch 自动构建计算图)# h = torch.relu(w1 * x + b1)# y = w2 * h + b2# loss = (y - 1.0) ** 2## # 反向传播(一行代码,自动算所有梯度!)# loss.backward()## print(w1.grad) # dL/dw1# print(b1.grad) # dL/db1# print(w2.grad) # dL/dw2# print(b2.grad) # dL/db2PyTorch 在前向传播时自动记录每一步操作(构建计算图),然后 loss.backward() 沿着图反向传播,用链式法则自动计算每个参数的梯度。
四、完整示例:训练一个小网络
Section titled “四、完整示例:训练一个小网络”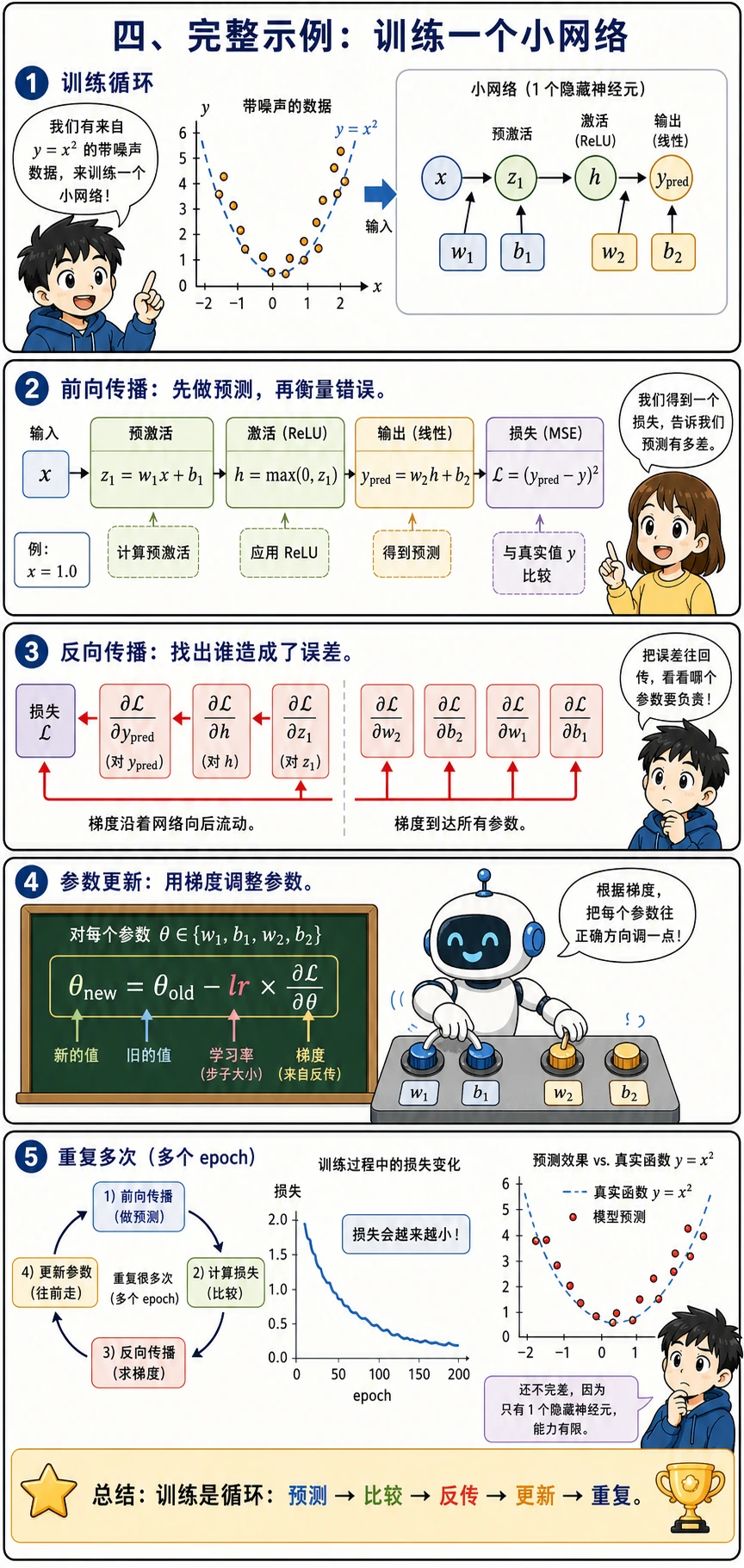
把前向传播 + 反向传播 + 参数更新放在一起,训练一个两层网络:
这个完整示例就是 AI 训练循环的最小版本:
- 读取一个数据点
- 做前向传播,得到预测
- 计算损失
- 做反向传播,得到梯度
- 更新参数,重复很多个
epoch
epoch 表示完整看完一遍训练数据。losses 这个列表用来记录训练是不是大体朝着正确方向前进。
import numpy as npimport matplotlib.pyplot as plt
# 数据rng = np.random.default_rng(seed=42)X_data = rng.uniform(-2, 2, 50)y_data = X_data ** 2 + rng.normal(size=50) * 0.3 # y = x² + 噪声
# 两层网络参数w1 = rng.normal()b1 = 0.0w2 = rng.normal()b2 = 0.0
lr = 0.01losses = []
for epoch in range(500): total_loss = 0
for x, target in zip(X_data, y_data): # === 前向传播 === z1 = w1 * x + b1 h = max(0, z1) y_pred = w2 * h + b2 loss = (y_pred - target) ** 2 total_loss += loss
# === 反向传播 === dL_dy = 2 * (y_pred - target) dL_dw2 = dL_dy * h dL_db2 = dL_dy dL_dh = dL_dy * w2 dL_dz1 = dL_dh * (1.0 if z1 > 0 else 0.0) dL_dw1 = dL_dz1 * x dL_db1 = dL_dz1
# === 更新参数 === w1 -= lr * dL_dw1 b1 -= lr * dL_db1 w2 -= lr * dL_dw2 b2 -= lr * dL_db2
losses.append(total_loss / len(X_data)) if epoch % 100 == 0: print(f"Epoch {epoch}: loss = {losses[-1]:.4f}")
# 可视化fig, axes = plt.subplots(1, 2, figsize=(14, 5))
axes[0].plot(losses, color='coral', linewidth=2)axes[0].set_xlabel('Epoch')axes[0].set_ylabel('Loss')axes[0].set_title('训练损失')axes[0].grid(True, alpha=0.3)
x_test = np.linspace(-2, 2, 200)y_pred_test = []for x in x_test: z1 = w1 * x + b1 h = max(0, z1) y_pred_test.append(w2 * h + b2)
axes[1].scatter(X_data, y_data, alpha=0.4, s=20, color='gray', label='数据')axes[1].plot(x_test, x_test**2, 'g--', linewidth=2, label='y = x²(真实)')axes[1].plot(x_test, y_pred_test, 'r-', linewidth=2, label='网络预测')axes[1].set_title('拟合结果(两层网络,1 个隐藏神经元)')axes[1].legend()axes[1].grid(True, alpha=0.3)
plt.tight_layout()plt.show()学完这一页,至少保留这张证据卡:
- 函数
- 目标函数、损失、导数、梯度或链式法则表达式
- 计算
- 数值导数、梯度步长或反向传播轨迹
- 输出
- 斜率、梯度向量、更新后的参数,或损失变化
- 失败检查
- 符号错误、学习率过大、局部斜率理解错误或链式法则出错
- 期望产出
- 展示参数如何变化的计算轨迹
| 概念 | 直觉 |
|---|---|
| 链式法则 | 复合函数的导数 = 每层导数相乘 |
| 前向传播 | 从输入到损失,逐步计算 |
| 反向传播 | 从损失到参数,逐步算梯度 |
| 计算图 | 记录运算步骤,支持自动求导 |
| 自动微分 | PyTorch 帮你自动算所有梯度 |
这节最该带走什么
Section titled “这节最该带走什么”- 链式法则最重要的直觉是“变化会沿着多层结构一层层传下去”
- 反向传播最重要的直觉是“从损失开始,把梯度一层层传回来”
- 计算图最重要的价值是把这件事变成可记录、可自动化的过程
flowchart LR FW["前向传播<br/>输入 → 损失"] --> BW["反向传播<br/>损失 → 梯度"] BW --> UP["参数更新<br/>梯度下降"] UP --> FW
style FW fill:#e3f2fd,stroke:#1565c0,color:#333 style BW fill:#ffebee,stroke:#c62828,color:#333 style UP fill:#e8f5e9,stroke:#2e7d32,color:#333练习 1:链式法则手算
Section titled “练习 1:链式法则手算”对 y = (2x + 1)³,用链式法则求 dy/dx,在 x=1 处验证。
练习 2:扩展网络
Section titled “练习 2:扩展网络”把第四节的两层网络改为有 3 个隐藏神经元(w1 变成 3 个权重),手动写出前向传播和反向传播代码。
练习 3:对比手动 vs 自动
Section titled “练习 3:对比手动 vs 自动”如果你已经安装了 PyTorch,用 torch.autograd 计算第二节中所有参数的梯度,和手算结果对比。
如果 import torch 失败,请先安装 PyTorch。对于简单 CPU 或 macOS 环境,通常可以运行:
python -m pip install --upgrade torchimport torch
x = torch.tensor(2.0)w1 = torch.tensor(0.5, requires_grad=True)b1 = torch.tensor(0.1, requires_grad=True)w2 = torch.tensor(-0.3, requires_grad=True)b2 = torch.tensor(0.2, requires_grad=True)
h = torch.relu(w1 * x + b1)y = w2 * h + b2loss = (y - 1.0) ** 2loss.backward()
print("loss =", loss.item())print("w1.grad =", w1.grad.item())print("b1.grad =", b1.grad.item())print("w2.grad =", w2.grad.item())print("b2.grad =", b2.grad.item())操作参考与检查点
- 对
y=(2x+1)^3,导数是6(2x+1)^2;在x=1时值为54。 - 把网络扩展成 3 个隐藏神经元时,把隐藏层写成向量,并分别保留每个权重的梯度。主要检查点是:每个 forward 值都应有对应的 backward 梯度。
- autograd 和手算梯度应在四舍五入范围内一致。如果不同,检查 ReLU 的激活/未激活分支、漏掉的链式因子,以及 loss 定义是否相同。