5.3.1 无监督学习路线图:没有标签时寻找结构
无监督学习从“数据没有标签”开始。模型不会告诉你最终真相,它只是帮助你发现可能存在的结构。
先看结构地图
Section titled “先看结构地图”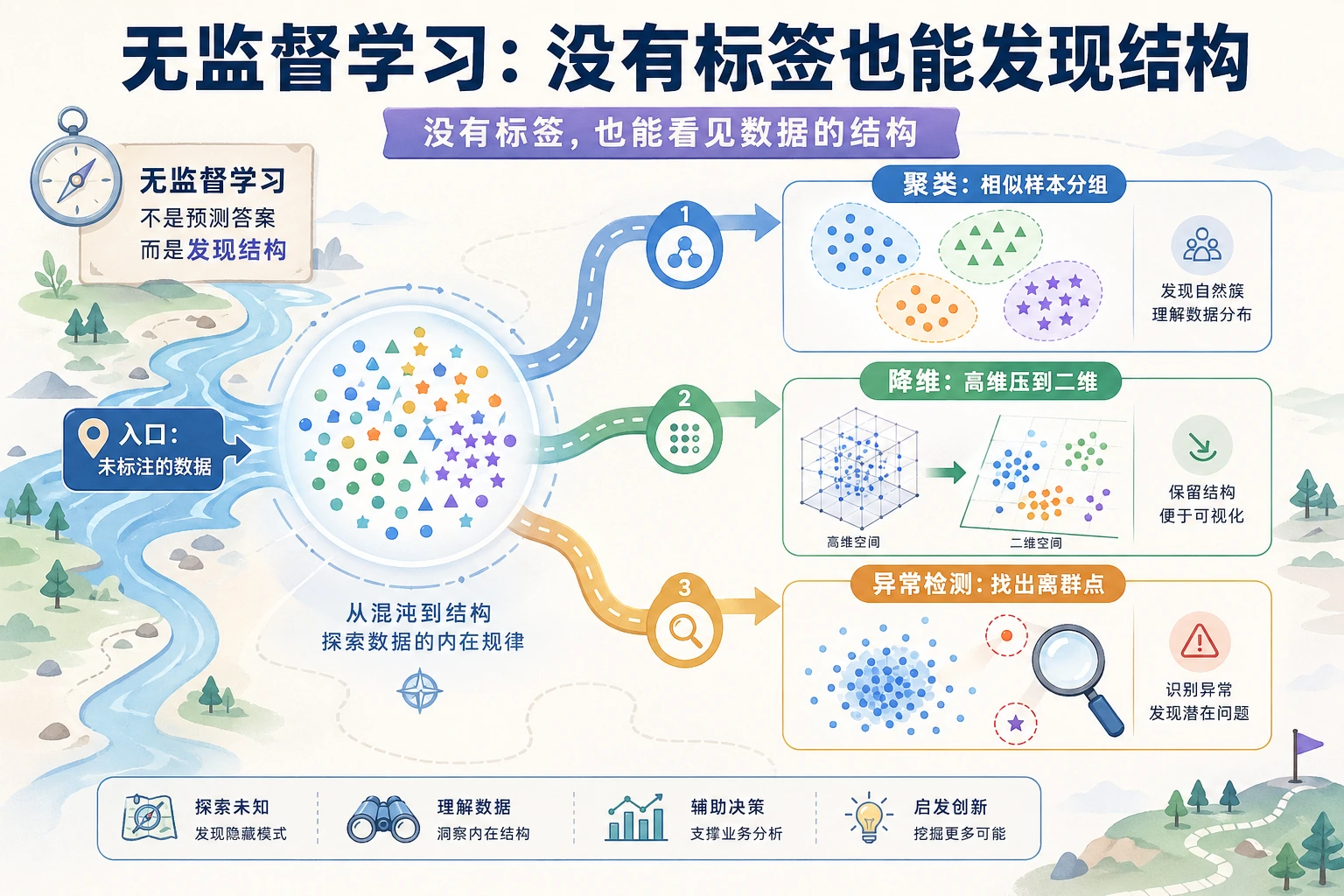
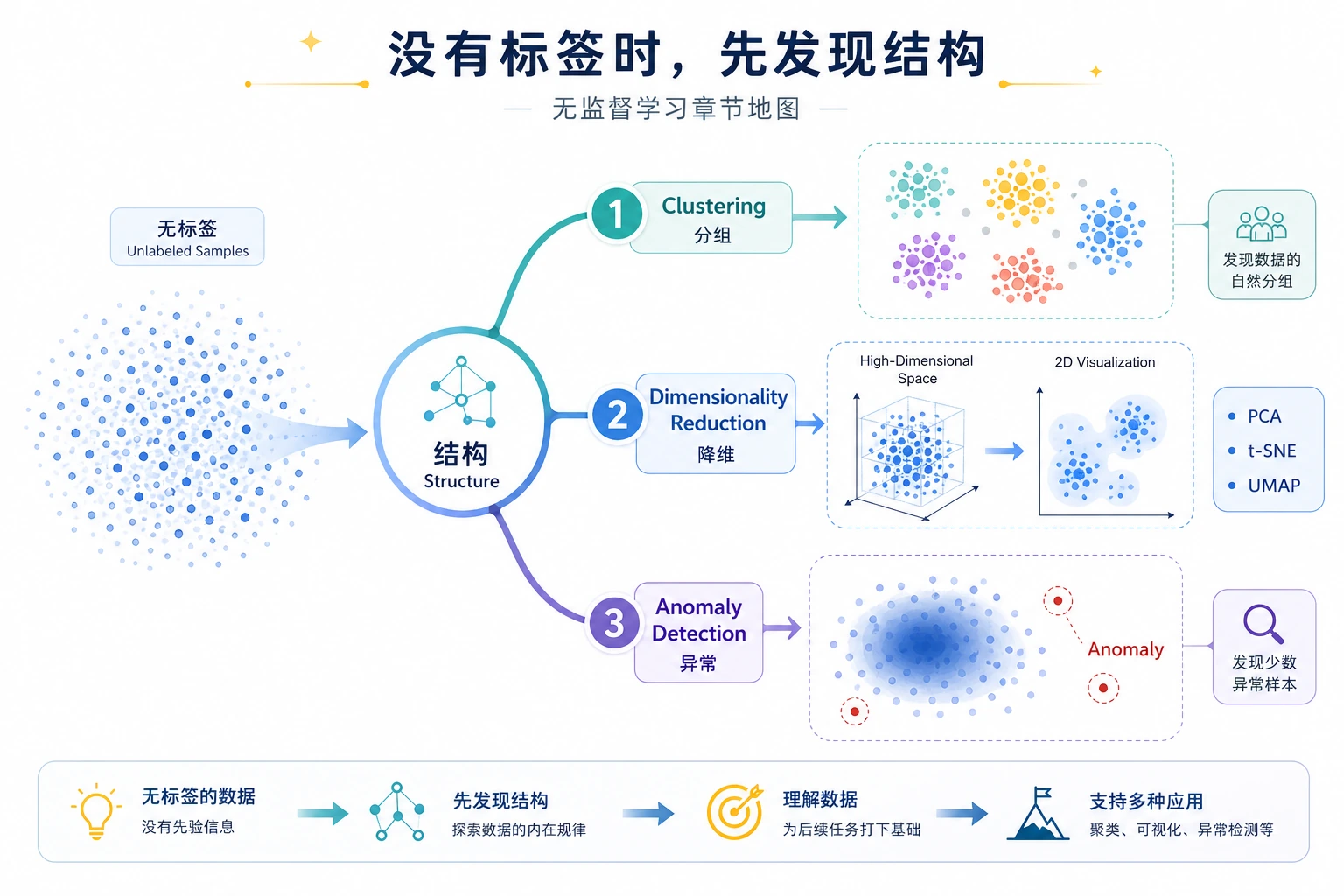
| 如果目标是 | 先使用 |
|---|---|
| 找自然分组 | 聚类 |
| 压缩高维数据 | 降维 |
| 找异常点 | 异常检测 |
关键问题不是“标签对不对”,而是“这个结构有没有证据、有没有意义”。
跑一个聚类 baseline
Section titled “跑一个聚类 baseline”创建 unsupervised_first_loop.py,安装 scikit-learn 后运行。
from sklearn.cluster import KMeansfrom sklearn.datasets import make_blobs
X, _ = make_blobs(n_samples=30, centers=3, random_state=7, cluster_std=0.8)
model = KMeans(n_clusters=3, random_state=7, n_init="auto")labels = model.fit_predict(X)
print("cluster_count:", len(set(labels)))print("first_five_labels:", labels[:5].tolist())print("inertia:", round(model.inertia_, 2))预期输出:
cluster_count: 3first_five_labels: [2, 0, 0, 1, 0]inertia: 43.44聚类给的是组编号,不是人的解释。你还需要图表、特征汇总和业务解释。
按这个顺序学
Section titled “按这个顺序学”| 顺序 | 阅读 | 练什么 |
|---|---|---|
| 1 | 5.3.2 聚类 | K-Means、聚类解释、错误的簇数选择 |
| 2 | 5.3.3 降维 | PCA、可视化、压缩 |
| 3 | 5.3.4 异常检测 | 离群点、阈值、告警证据 |
能解释你想寻找哪种结构,能跑一个无监督模型,并写出一句谨慎解释,而不是把输出当成绝对真相,就算通过。
检查思路与讲解
- 在无监督学习里,模型输出的是“可能存在的结构”,不是已经验证过的答案。
- 好的解释应包含图表或特征汇总、对结构的谨慎命名,以及一句不确定性说明。
- 最先检查的失败点包括缩放问题、簇数随意、噪声维度过多,以及数值上异常但场景里正常的告警。
学完这一页,至少保留这张证据卡:
- 任务
- 聚类、降维或异常检测目标
- 数据视图
- 缩放后的特征、投影、聚类或异常分数
- 解释
- 该场景中各组、坐标轴或告警的含义
- 失败检查
- 任意簇数、缩放问题、噪声维度或误报
- 期望产出
- 带解释和不确定性说明的无监督结果