8.1.6 RAG 优化
完成本节后,你将能够:
- 识别 RAG 系统里最常见的优化点
- 理解 chunk、top-k、rerank、prompt 对结果的影响
- 学会做一个简单的上下文拼装策略
- 建立“先找瓶颈,再调参数”的优化思路
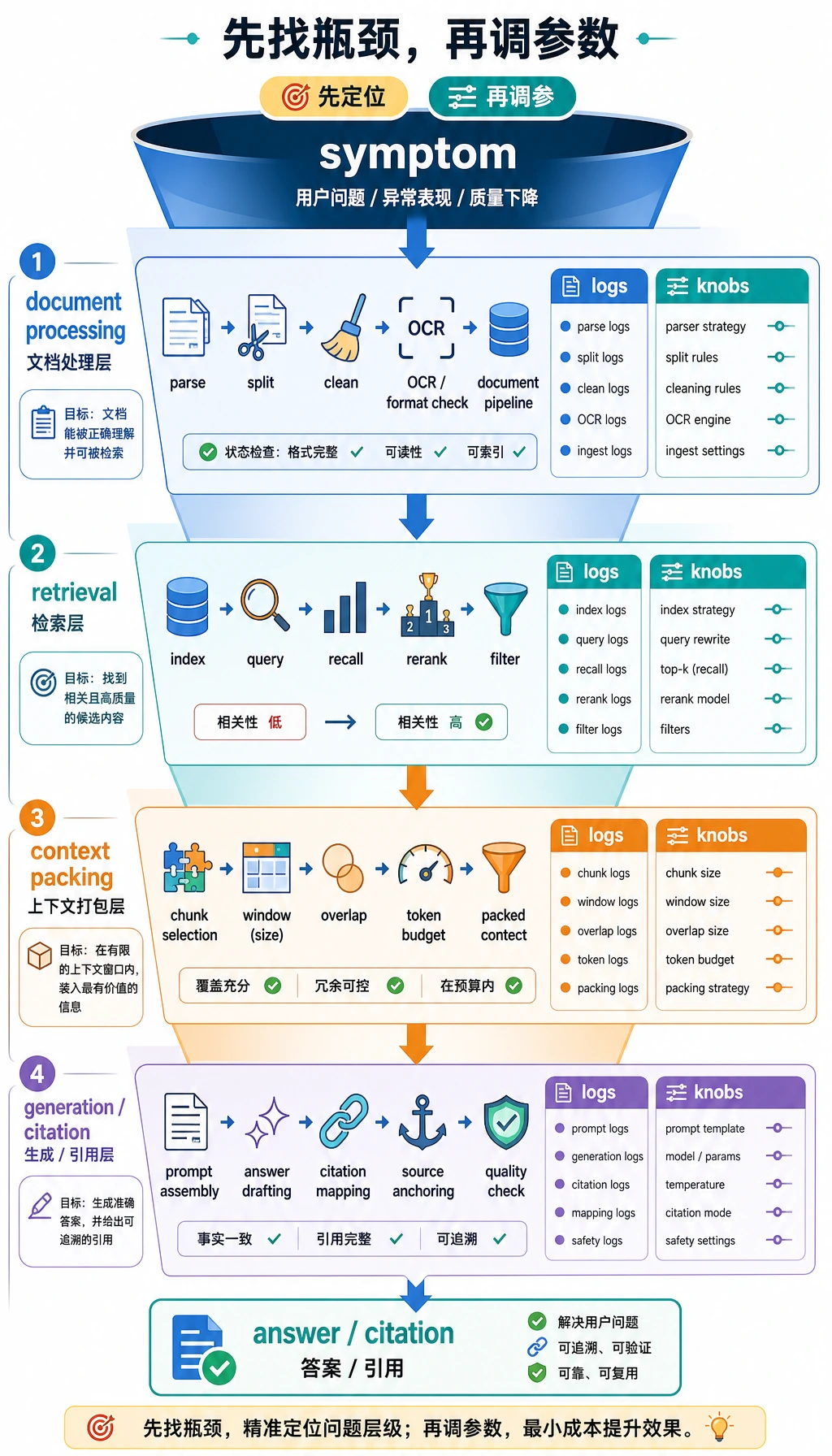
一、优化前先定位问题出在哪一段
Section titled “一、优化前先定位问题出在哪一段”一个 RAG 系统通常有四段
Section titled “一个 RAG 系统通常有四段”可以粗略拆成:
- 文档处理
- 检索召回
- 上下文拼装
- 生成回答
如果回答效果差,你首先要问:
- 是没找到对的资料?
- 还是找到了但没塞进去?
- 还是塞进去了但模型没用好?
不同问题,对应不同优化方向
Section titled “不同问题,对应不同优化方向”| 现象 | 常见问题点 |
|---|---|
| 明明有答案却没检索到 | 切块 / embedding / 检索策略 |
| 检索到了但答案还是偏 | prompt / 上下文组装 / 模型总结 |
| 回答很慢很贵 | top-k 过大 / 上下文太长 / 重排过多 |
二、从文档处理开始优化
Section titled “二、从文档处理开始优化”Chunk 大小不是越大越好
Section titled “Chunk 大小不是越大越好”chunk 太大:
- 召回不精准
- 上下文占用大
chunk 太小:
- 信息容易被切碎
- 证据不完整
所以常见优化不是“越大越保险”,而是找平衡。
保留结构信息经常很重要
Section titled “保留结构信息经常很重要”很多文档的价值不只在句子本身,还在:
- 标题
- 段落层级
- 表格归属
- 页面位置
如果清洗时把这些结构全抹掉,后面检索质量常常会变差。
三、召回阶段最常调的几个杠杆
Section titled “三、召回阶段最常调的几个杠杆”top_k:不是越多越好
Section titled “top_k:不是越多越好”很多人一开始觉得:
多拿一些资料,总不会错吧?
其实不一定。
top_k 太大时,可能会把无关内容也带进来,反而干扰模型。
Rerank:先广撒网,再精筛
Section titled “Rerank:先广撒网,再精筛”当粗召回里混进了很多边缘内容时,rerank 很有帮助。 它不是单纯“多做一步”,而是在提高上下文质量密度。
四、上下文拼装比很多人想的更重要
Section titled “四、上下文拼装比很多人想的更重要”模型不是“看到资料就一定会用”
Section titled “模型不是“看到资料就一定会用””即使召回到了正确内容,也可能出现:
- 关键证据埋在中间
- 多个 chunk 顺序混乱
- 信息重复太多
所以“把哪些块按什么顺序塞进去”本身就是优化点。
一个可运行的上下文打包示例
Section titled “一个可运行的上下文打包示例”chunks = [ {"score": 0.95, "text": "退款政策:购买后 7 天内且学习进度低于 20% 可退款。"}, {"score": 0.80, "text": "证书说明:完成所有项目并通过测试后可获得证书。"}, {"score": 0.76, "text": "学习顺序:建议先学 Python,再学机器学习。"}, {"score": 0.72, "text": "补充条款:退款申请需提交订单信息。"}]
def pack_context(chunks, max_chars=60): packed = [] total = 0 for item in sorted(chunks, key=lambda x: x["score"], reverse=True): text = item["text"] if total + len(text) > max_chars: continue packed.append(text) total += len(text) return packed
selected = pack_context(chunks, max_chars=60)print("最终塞进上下文的 chunk:")for c in selected: print("-", c)预期输出:
最终塞进上下文的 chunk:- 退款政策:购买后 7 天内且学习进度低于 20% 可退款。- 证书说明:完成所有项目并通过测试后可获得证书。这就是最简单的“上下文预算管理”。
五、生成阶段怎么优化?
Section titled “五、生成阶段怎么优化?”Prompt 要明确告诉模型“怎么用资料”
Section titled “Prompt 要明确告诉模型“怎么用资料””很多时候不是资料没找到,而是模型没有被明确要求:
- 只能依据给定资料回答
- 证据不足时要承认不知道
- 要引用来源
一个常见的提示思路是:
“请仅根据以下资料回答;如果资料不足,请明确说资料不足。”
引用来源能显著提升可控性
Section titled “引用来源能显著提升可控性”让答案带上来源,通常有几个好处:
- 用户更信任
- 方便人工核查
- 便于调试哪段资料生效了
六、一个简单的优化实验思路
Section titled “六、一个简单的优化实验思路”不要一口气改五个参数
Section titled “不要一口气改五个参数”建议按这种顺序:
- 固定评估集
- 先设一个 基线
- 一次只改一个变量
例如:
- 先只改 chunk size
- 再只改 top-k
- 再只加 rerank
一个小型配置对比脚本
Section titled “一个小型配置对比脚本”configs = [ {"chunk_size": 200, "top_k": 3}, {"chunk_size": 400, "top_k": 3}, {"chunk_size": 200, "top_k": 5}]
fake_scores = { (200, 3): 0.78, (400, 3): 0.71, (200, 5): 0.74}
for cfg in configs: key = (cfg["chunk_size"], cfg["top_k"]) print(cfg, "-> 评估得分", fake_scores[key])预期输出:
{'chunk_size': 200, 'top_k': 3} -> 评估得分 0.78{'chunk_size': 400, 'top_k': 3} -> 评估得分 0.71{'chunk_size': 200, 'top_k': 5} -> 评估得分 0.74虽然这是玩具数据,但它表达了一个很重要的工程习惯: 优化要靠对比实验,不靠感觉。
七、RAG 优化经常会遇到的权衡
Section titled “七、RAG 优化经常会遇到的权衡”质量 vs 成本
Section titled “质量 vs 成本”- 更大的 top-k:可能更全,但更贵
- 更强的 reranker:可能更准,但更慢
召回率 vs 精准率
Section titled “召回率 vs 精准率”- 召回过少:可能漏答案
- 召回过多:可能引入噪声
实时性 vs 稳定性
Section titled “实时性 vs 稳定性”- 实时查询新资料更灵活
- 预处理得更充分通常更稳
没有万能最优解,只有场景最优解。
八、如果你的目标是“知识库驱动的 SOP 文档助手”,优化顺序最好怎么排?
Section titled “八、如果你的目标是“知识库驱动的 SOP 文档助手”,优化顺序最好怎么排?”这类项目里,最容易犯的错是:
- 一上来就换更大的模型
- 或者一上来就把 top-k 拉得很大
但更稳的默认顺序通常是:
- 先看文档解析对不对
- 再看知识块是不是按政策 / 处理案例 / 复核清单分清了
- 再看检索有没有把对的内容召回
- 再看结构化输出和模板是不是把政策、案例、清单放对位置
- 最后才调模型和 prompt
你可以先把它压成一句话:
这类项目优先优化“找对”和“放对”,最后再优化“写得更漂亮”。
九、一个更像 SOP 文档项目的最小优化检查表
Section titled “九、一个更像 SOP 文档项目的最小优化检查表”| 现象 | 更值得先查哪里 |
|---|---|
| 主题对了但没有处理案例 | 文档解析 / 内容类型标注 |
| 找到了案例但放进了政策栏目 | 结构约束 / 模板映射 |
| 资料很多但生成结果还是空 | 检索过滤条件 / top-k / 上下文组装 |
| 内部文档明明有标准答案却被外部内容带偏 | 来源优先级策略 |
这张表特别适合新人,因为它会把“优化”重新压回到几个可以排查的层级。
十、初学者常见误区
Section titled “十、初学者常见误区”一上来就换更大的模型
Section titled “一上来就换更大的模型”很多 RAG 问题其实不是模型太弱,而是检索链路没调好。
只看单次演示,不做稳定评估
Section titled “只看单次演示,不做稳定评估”一次答对不代表系统稳定。
把 top-k 一路调大
Section titled “把 top-k 一路调大”更多上下文并不总是更好,尤其当上下文里混了太多无关块时。
RAG 优化排查矩阵
Section titled “RAG 优化排查矩阵”真正做优化时,最有用的不是记住很多技巧,而是能把现象定位到具体链路。
- 正确资料完全没出现:先看 query、top-k 原始命中和 chunk 文本。优先尝试调整切块、关键词检索或查询改写,不要一开始就换更大生成模型。
- 正确资料出现但排得靠后:先看每个 chunk 的 score 和排序。优先尝试 rerank 或混合检索权重,不要盲目把 top-k 拉很大。
- 正确资料在上下文里但答案漏条件:先看最终上下文、prompt 和答案引用。优先调整上下文组装,并要求逐条引用,不要只改 embedding 模型。
- 答案引用了错误来源:先看 answer、
source_refs和证据片段。优先做 citation check、限制引用格式,不要只看最终答案是否流畅。 - 延迟和成本突然升高:先看 top-k、rerank 数量和上下文长度。优先限制候选数量、加缓存或分层检索,不要同时增加 top-k 和模型大小。
这张表的用法是:每次只选一个现象,找到对应日志,再决定改哪一个杠杆。不要在不知道问题在哪一层时同时改 chunk、embedding、top-k、rerank 和 prompt。
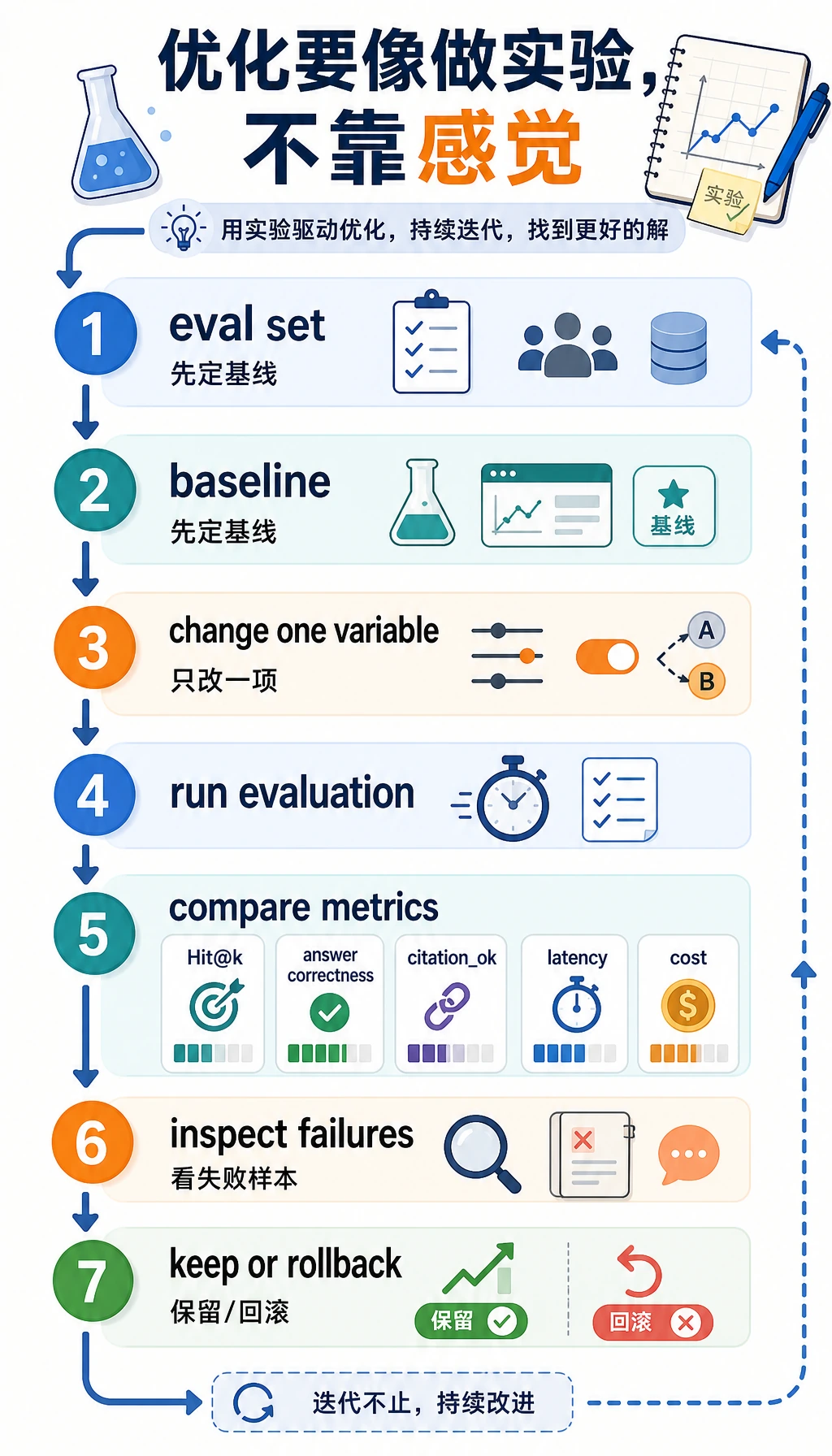
一个固定的优化实验流程
Section titled “一个固定的优化实验流程”RAG 优化最好像做实验,而不是像调玄学参数。一个适合初学者的流程是:先固定 20~50 个评估问题,再跑 baseline,记录检索命中、答案正确、引用是否支持结论,然后一次只改一个变量。
| 步骤 | 要产出的东西 | 判断标准 |
|---|---|---|
| 建 基线 | 当前配置、评估集、失败样本 | 能重复跑出同一批结果 |
| 改一个变量 | 例如只改 chunk size 或只加 rerank | 其他配置保持不变 |
| 对比指标 | Hit@k、答案正确率、引用真实性、平均延迟 | 至少一个关键指标变好,且副作用可接受 |
| 看失败样本 | 新增失败和修复失败各列出来 | 知道为什么变好或变差 |
| 决定是否保留 | 写一句结论 | 不是“感觉更好”,而是“在哪类问题上更好” |
一个优化记录可以写成这样:
baseline:关键词检索,top-k=3。精确术语表现稳定,但同义问法较弱,作为对照组保留。exp-1:加入查询改写。同义问法命中提升,但可能出现少量错误改写;只有记录改写日志时才保留。exp-2:加入 rerank。正确资料排序更靠前,但延迟增加;只有延迟可接受时才作为标准版本。
成本、延迟和质量的取舍检查
Section titled “成本、延迟和质量的取舍检查”RAG 系统不是只追求最高分。真实项目里还要考虑用户是否等得起、成本是否扛得住、结果是否稳定。
| 优化动作 | 可能收益 | 可能代价 | 适合什么时候用 |
|---|---|---|---|
| 增大 top-k | 减少漏召回 | 上下文更长、噪声更多、成本更高 | 正确资料经常没进入候选时 |
| 加 rerank | 排序更准 | 延迟增加、实现复杂度增加 | 候选里有答案但排得靠后时 |
| 查询改写 | 口语问题更容易命中 | 可能把问题改偏 | 用户表达和文档表达差异大时 |
| 更强 embedding | 语义召回更好 | 重建索引、成本上升 | 基线 证明语义召回是瓶颈时 |
| 更严格 prompt | 幻觉更少 | 可能回答更保守 | 资料不足时也容易胡编时 |
优化时可以记住一个原则:如果系统还没有检索日志和评估集,先不要急着上复杂组件。没有观测,就很难判断复杂组件到底是在解决问题,还是在制造新的不确定性。
学完这一页,至少保留这张证据卡:
- 查询
- 一个用户问题或测试用例
- 已检索分块
- 分块 ID、分数和来源标题
- 答案
- 带引用或来源说明的最终回答
- 失败检查
- 缺少证据、切分错误、文档过时或论断无依据
- 下一步动作
- 分块、embedding、重排、Prompt 或评估改动
这一节最重要的认识是:
RAG 优化不是只改一个参数,而是在“召回质量、上下文质量、生成约束、成本速度”之间找平衡。
真正有效的优化,通常从定位瓶颈开始,而不是盲目堆更多组件。
- 修改
pack_context()里的max_chars,观察被选中的 chunk 会如何变化。 - 自己构造一组不同的
chunk_size / top_k配置,练习做小型对比实验。 - 想一想:如果系统总是“检索到了正确资料,但回答还是偏”,下一步你最该优化哪里?
参考实现与讲解
- 较低的
max_chars会迫使系统丢掉更多 chunk 或缩短上下文;较高的max_chars能包含更多证据,但会增加噪声和成本。好的设置是能保留必要证据的最小上下文。 - 好的对比实验应一次只改一个变量,并记录 retrieval hit、answer correctness、citation quality、latency 和 token cost。没有固定测试问题,优化就会变成猜测。
- 如果检索正确但回答仍偏,应先优化 prompt grounding、引用要求、answer schema、reranking、上下文排序或生成后校验,而不是立刻换向量数据库。