8.5.3 项目:RAG+微调综合系统
- 理解为什么“只做 RAG”或“只做微调”有时都不够
- 学会把领域问答系统拆成 RAG 层和微调层
- 设计一个可解释的 RAG+微调项目方案
- 跑通一个最小的组合式项目骨架
在把 RAG 和微调混合前,先把训练相关术语分清:
| 术语 | 新人理解 | 它应该解决什么 |
|---|---|---|
fine-tuning | 微调,在基础模型上继续用任务样例训练 | 让行为、格式、领域表达更稳定 |
SFT | Supervised Fine-Tuning,监督微调,用人工编写或整理的输入输出样例训练 | 教模型“好答案长什么样” |
LoRA | Low-Rank Adaptation,低秩适配,只训练较小的适配器参数 | 降低训练成本,同时调整模型行为 |
QLoRA | 量化 LoRA,把低精度加载和 LoRA 结合 | 让较小硬件也能做微调实验 |
domain adaptation | 领域适配,让系统适合某个具体行业或业务语境 | 通常既需要领域知识,也需要领域回答方式 |
eval set | 固定评测集,一组测试问题和预期检查点 | 避免只凭一个看起来不错的例子判断改进 |
实用规则是:不要用微调去记忆经常变化的文档。变化的知识交给 RAG,稳定的行为和格式再用微调或 SFT 样例去补。
一、为什么要把 RAG 和微调组合起来?
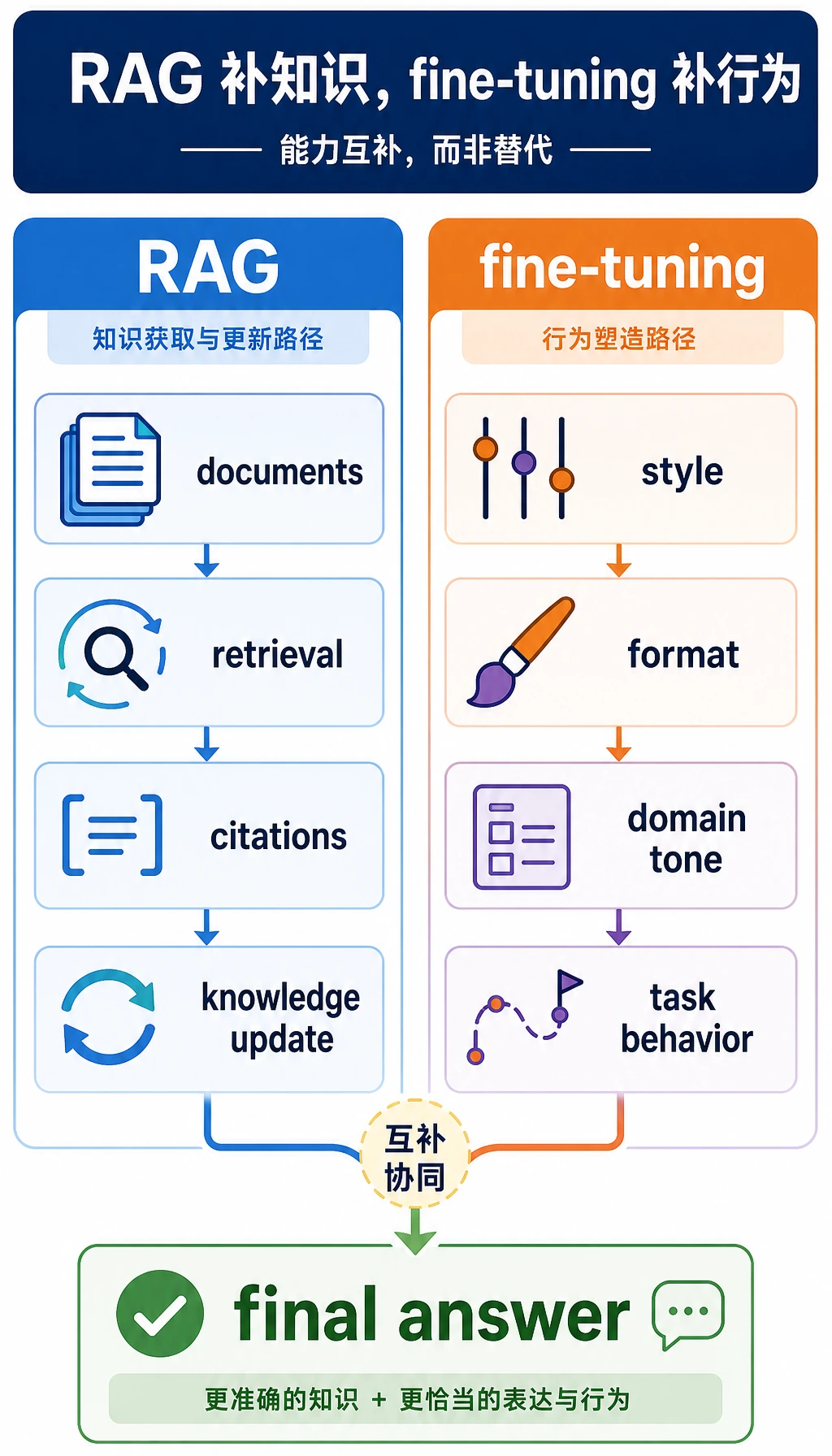
Section titled “一、为什么要把 RAG 和微调组合起来?”单独 RAG 的优点和局限
Section titled “单独 RAG 的优点和局限”RAG 的优点:
- 知识可更新
- 可引用来源
- 不必重新训练模型
但它也有局限:
- 模型未必懂你的领域表达
- 检索到了也未必会答得符合业务格式
- 复杂任务时,模型的“回答习惯”未必够稳
单独微调的优点和局限
Section titled “单独微调的优点和局限”微调的优点:
- 能让模型更懂特定任务形式
- 输出风格更稳定
- 指令跟随更贴合业务
但它也有局限:
- 新知识更新没那么灵活
- 很难靠微调记住所有细节文档
- 成本更高
所以它们经常是互补关系
Section titled “所以它们经常是互补关系”可以先用一句话记住:
RAG 负责补知识,微调负责补行为。
这正是组合式系统的核心逻辑。
二、这个项目到底在做什么?
Section titled “二、这个项目到底在做什么?”我们把目标定成一个领域问答助手,比如:
- 面向企业内部政策文档
- 回答时要稳定引用来源
- 输出格式必须规范
- 某些问题需要用固定业务口径回答
也就是说,这个系统既要:
- 查得到知识
- 又要答得像该领域系统
先画出系统结构
Section titled “先画出系统结构”flowchart LR A["用户问题"] --> B["检索器"] B --> C["相关文档块"] C --> D["微调后的回答模型"] D --> E["规范化输出"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style B fill:#fff3e0,stroke:#e65100,color:#333 style C fill:#f3e5f5,stroke:#6a1b9a,color:#333 style D fill:#e8f5e9,stroke:#2e7d32,color:#333 style E fill:#ffebee,stroke:#c62828,color:#333这张图真正重要的地方
Section titled “这张图真正重要的地方”不是“组件多”,而是职责清楚:
- 检索器负责找资料
- 微调模型负责按业务方式组织答案
这能让系统更可解释,也更容易迭代。
一个最小知识库和检索器
Section titled “一个最小知识库和检索器”from sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics.pairwise import cosine_similarity
kb = [ {"id": "doc1", "text": "退款政策:购买后 7 天内且学习进度低于 20% 可退款。"}, {"id": "doc2", "text": "证书政策:完成项目并通过测试后可获得证书。"}, {"id": "doc3", "text": "客服处理规范:回答时需要先说明政策依据,再给出结论。"}]
vectorizer = TfidfVectorizer(analyzer="char", ngram_range=(2, 4))doc_vectors = vectorizer.fit_transform([item["text"] for item in kb])
def retrieve(query, top_k=2): query_vec = vectorizer.transform([query]) scores = cosine_similarity(query_vec, doc_vectors)[0] top_idx = scores.argsort()[::-1][:top_k] return [kb[i] for i in top_idx]
print(retrieve("退款条件是什么"))预期输出:
[{'id': 'doc1', 'text': '退款政策:购买后 7 天内且学习进度低于 20% 可退款。'}, {'id': 'doc3', 'text': '客服处理规范:回答时需要先说明政策依据,再给出结论。'}]中文示例这里使用 analyzer="char" 和 ngram_range=(2, 4),因为中文没有天然空格分词。这样即使不额外安装分词库,也能得到稳定的教学结果。
这个检索器本身不复杂,但它已经是组合系统的第一半。
再模拟一个“微调后的回答风格”
Section titled “再模拟一个“微调后的回答风格””在真实项目里,这一步可能来自:
- 指令微调
- LoRA / QLoRA
- 监督数据集训练
为了让代码能直接运行,这里我们先用规则模拟“已经被训练过的业务输出风格”。
def domain_answer_style(question, retrieved_docs): evidence = " ".join(doc["text"] for doc in retrieved_docs)
if "退款" in question: return { "answer": "根据现行退款政策,购买后 7 天内且学习进度低于 20% 的用户可申请退款。", "reasoning_style": "先政策后结论", "evidence": evidence }
if "证书" in question: return { "answer": "根据证书政策,完成项目并通过测试后可以获得证书。", "reasoning_style": "先政策后结论", "evidence": evidence }
return { "answer": "当前没有找到足够匹配的业务规则。", "reasoning_style": "谨慎拒答", "evidence": evidence }为什么这个模拟是有意义的?
Section titled “为什么这个模拟是有意义的?”因为它在帮你理解:
- RAG 解决的是“知道什么”
- 微调解决的是“怎么答”
把两部分真正串起来
Section titled “把两部分真正串起来”def rag_plus_finetune_system(question): docs = retrieve(question, top_k=2) result = domain_answer_style(question, docs) return { "question": question, "retrieved_docs": docs, **result }
result = rag_plus_finetune_system("退款条件是什么?")print(result["question"])print(result["answer"])print("evidence:", result["evidence"])预期输出:
退款条件是什么?根据现行退款政策,购买后 7 天内且学习进度低于 20% 的用户可申请退款。evidence: 退款政策:购买后 7 天内且学习进度低于 20% 可退款。 客服处理规范:回答时需要先说明政策依据,再给出结论。这个系统已经说明了什么?
Section titled “这个系统已经说明了什么?”它已经说明:
组合系统不是把两种技术硬拼,而是让它们各自做最擅长的部分。
真正项目里,微调通常微调什么?
Section titled “真正项目里,微调通常微调什么?”不是为了“记住所有文档”
Section titled “不是为了“记住所有文档””很多新人会误以为:
微调后模型就该把知识库都背下来
但更常见、更现实的目标其实是:
- 学会领域术语风格
- 学会输出格式
- 学会业务回答模板
- 学会某类任务的固定结构
你可能希望模型学会:
- “先引用政策,再给结论”
- “不确定时明确拒答”
- “所有回答都输出标准字段”
这类能力就很适合靠微调或至少靠强监督式训练来强化。
一个真正有项目价值的拆分方式
Section titled “一个真正有项目价值的拆分方式”RAG 层负责
Section titled “RAG 层负责”- 文档切块
- 检索
- 来源引用
- 知识更新
- 回答风格
- 输出格式
- 任务模板
- 业务术语理解
这个职责拆分一清楚,项目的可维护性会好很多。
怎样评估这个综合系统?
Section titled “怎样评估这个综合系统?”不能只看“答得顺不顺”
Section titled “不能只看“答得顺不顺””你至少要看两层:
- 检索层:有没有找到对的文档
- 回答层:输出是否符合业务要求
一个最小评估思路
Section titled “一个最小评估思路”eval_data = [ {"question": "退款条件是什么", "gold_doc": "doc1", "must_contain": "7 天内"}, {"question": "证书如何获得", "gold_doc": "doc2", "must_contain": "通过测试"}]
for item in eval_data: result = rag_plus_finetune_system(item["question"]) hit = result["retrieved_docs"][0]["id"] == item["gold_doc"] good_answer = item["must_contain"] in result["answer"] print(item["question"], "retrieval_hit=", hit, "answer_ok=", good_answer)预期输出:
退款条件是什么 retrieval_hit= True answer_ok= True证书如何获得 retrieval_hit= True answer_ok= True这已经比“只看看演示像不像”前进很多了。
增加一个小型分层诊断练习
Section titled “增加一个小型分层诊断练习”组合系统出问题时,先判断是哪一层负责。这个小表就是项目复盘的起点。
diagnostics = [ {"symptom": "正确文档没有进入 top-2", "likely_layer": "RAG", "next_step": "改进切块、查询改写或检索策略"}, {"symptom": "正确文档已命中,但回答格式不稳定", "likely_layer": "微调 / 提示词", "next_step": "补监督样例或收紧结构化 schema"}, {"symptom": "回答引用 A 来源,却用了 B 来源的事实", "likely_layer": "grounding", "next_step": "增加引用检查和句子级证据校验"},]
for row in diagnostics: print(f"{row['likely_layer']}: {row['symptom']} -> {row['next_step']}")预期输出:
RAG: 正确文档没有进入 top-2 -> 改进切块、查询改写或检索策略微调 / 提示词: 正确文档已命中,但回答格式不稳定 -> 补监督样例或收紧结构化 schemagrounding: 回答引用 A 来源,却用了 B 来源的事实 -> 增加引用检查和句子级证据校验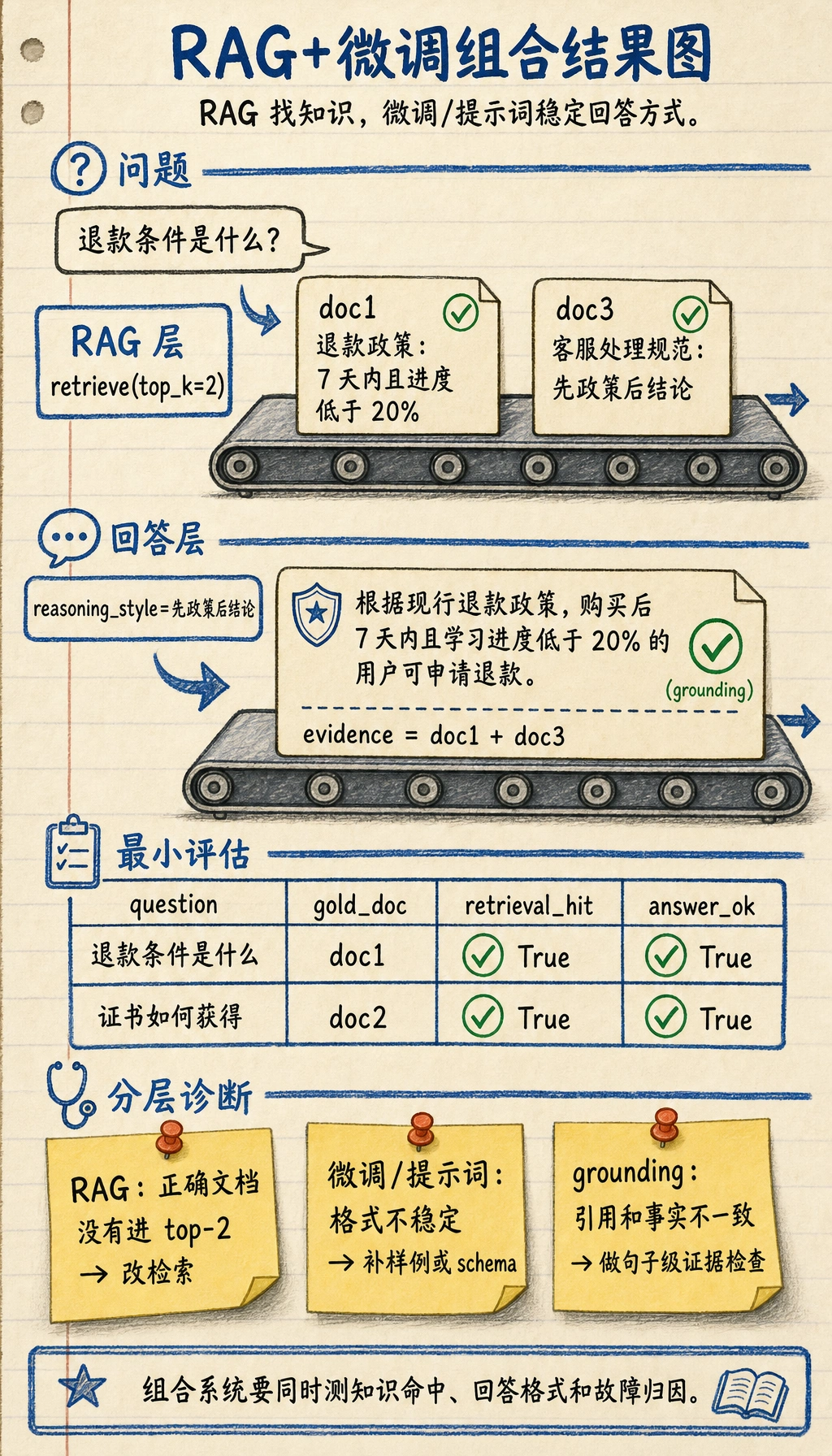
初学者最常踩的坑
Section titled “初学者最常踩的坑”用微调去解决知识更新问题
Section titled “用微调去解决知识更新问题”这通常会很低效。
用 RAG 去强行解决输出风格稳定问题
Section titled “用 RAG 去强行解决输出风格稳定问题”这也不总合适。
两层职责混乱
Section titled “两层职责混乱”如果你自己都说不清“哪一层在负责什么”,系统后面会很难调。
学完这一页,至少保留这张证据卡:
- 项目目标
- 用户任务和业务边界
- 基线
- 最简单的提示/RAG/应用版本优先
- 评估
- 固定案例、检索证据、答案质量和引用检查
- 失败日志
- 至少一个失败案例及其可能原因
- 交付物
- README、运行命令、截图/日志、下一步
这一节最重要的不是把 RAG 和微调两个词放在一起,而是理解:
RAG+微调综合系统的价值,在于让“知识获取”和“回答行为”分别由最合适的机制负责。
这才是组合式 LLM 系统真正的工程思路。
作品集级交付清单
Section titled “作品集级交付清单”如果你想把这个项目放进作品集,不要只展示“问一句能答一句”。更好的做法是把 RAG 层、回答层、评估层和复盘材料都交付出来。
| 交付物 | 最低要求 | 作品集级要求 |
|---|---|---|
| 知识库样例 | 至少 3~5 条文档片段 | 展示原始资料、切块结果、metadata 字段和来源 |
| 检索日志 | 能打印命中文档 | 保存查询、top-k、分数、来源和上下文长度 |
| 回答输出 | 能给出答案 | 答案包含结论、依据、来源和“不足以回答”的兜底 |
| 评估集 | 2~5 条测试问题 | 20~50 条问题,覆盖同义问法、边界条件和混淆问题 |
| 失败样本 | 简单记录错误 | 区分检索失败、生成失败、引用失败、格式失败 |
| README | 能说明怎么运行 | 有架构图、运行命令、示例输入输出、指标和下一步计划 |
这张表的重点是让项目从“技术演示”升级成“可解释作品”。别人看你的项目时,不只看它有没有答对,还会看你是否知道系统为什么答对、为什么答错、怎么继续改。
一个推荐的项目目录结构
Section titled “一个推荐的项目目录结构”你可以把最终项目整理成下面这种结构:
| 区域 | 建议文件 |
|---|---|
| 根目录 | README.md |
data/ | raw_docs/、chunks.jsonl、eval_questions.csv |
src/ | ingest.py、retrieve.py、answer.py、evaluate.py |
logs/ | retrieval_logs.jsonl、failure_cases.md |
reports/ | baseline_result.md、improvement_record.md |
第一次做时不必一次写满所有文件,但至少要让别人能看见三条线:资料怎么进入系统,问题怎么命中文档,答案怎么被评估。
README 里最该展示什么
Section titled “README 里最该展示什么”作品集项目的 README 不应该只写“本项目使用了 RAG 和微调”。更有价值的是展示完整闭环。
| README 模块 | 应该回答的问题 |
|---|---|
| 项目目标 | 这个系统解决什么领域问题,为什么需要 RAG 或微调 |
| 系统架构 | 用户问题如何经过检索、上下文、回答和引用 |
| 运行方式 | 如何安装依赖、准备数据、运行问答和评估 |
| 示例输出 | 输入问题、命中文档、最终答案、来源引用 |
| 评估结果 | 基线表现、优化后表现、失败样本 |
| 技术取舍 | 为什么用 RAG,为什么考虑微调,二者边界是什么 |
| 后续计划 | 下一步要优化检索、回答风格、成本还是部署 |
一个很小但有效的示例输出可以写成:
问题:退款条件是什么?命中文档:doc1 退款政策 score=0.92回答:根据退款政策,购买后 7 天内且学习进度低于 20% 可申请退款。来源:doc1评估:retrieval_hit=true, answer_ok=true, citation_ok=true最小失败样本记录
Section titled “最小失败样本记录”RAG+微调项目最能体现工程能力的地方,往往不是成功样例,而是失败样例。建议至少记录 3 类失败:
- 检索失败:正确政策没有进入 top-k。先检查 chunk、关键词匹配和 embedding,再调整切块、混合检索或查询改写。
- 回答失败:检索到了资料,但答案漏掉关键条件。先检查 prompt 约束和回答模板稳定性,再强化输出格式、增加
must_contain检查。 - 引用失败:答案结论和引用片段对不上。先检查引用拼接和模型自由发挥,再做 citation check,要求逐句依据。
- 风格失败:答案事实对,但不符合业务表达。先检查微调数据和示例,再增加格式样例或监督数据。
把失败样本写清楚,会比只贴一个成功截图更有说服力。
版本路线建议
Section titled “版本路线建议”| 版本 | 目标 | 交付重点 |
|---|---|---|
| 基础版 | 跑通最小闭环 | 能输入、能处理、能输出,并保留一组示例 |
| 标准版 | 形成可展示项目 | 增加配置、日志、错误处理、README 和截图 |
| 挑战版 | 接近作品集质量 | 增加评估、对比实验、失败样本分析和下一步路线 |
建议先完成基础版,不要一开始就追求大而全。每提升一个版本,都要把“新增了什么能力、怎么验证、还有什么问题”写进 README。
- 给知识库再加两条新文档,观察检索结果是否变化。
- 设计一个你自己的“领域回答风格规则”,模拟微调层行为。
- 想一想:如果系统检索总是对,但回答格式总乱,你该优先优化 RAG 还是微调?
- 用自己的话解释:为什么说“RAG 补知识,微调补行为”?
项目交付参考与讲解
- 新文档应测试检索结果是否只在查询意图匹配时变化,而不是随机波动。
- 风格规则可以规定语气、章节顺序、引用格式、拒答边界和领域术语。
- 如果文档总是正确但格式混乱,优先优化行为层:先改 prompt/schema,模式足够稳定后再考虑微调。
- RAG 在查询时补充变化的、领域相关的知识;微调更适合学习稳定的回答行为、风格和格式。