3.3.7 分组与聚合
- 理解 groupby 的”拆分—应用—合并”机制
- 掌握常用聚合函数和
agg方法 - 学会分组转换(transform)和分组过滤(filter)
- 掌握数据透视表(pivot_table)
先建立一张地图
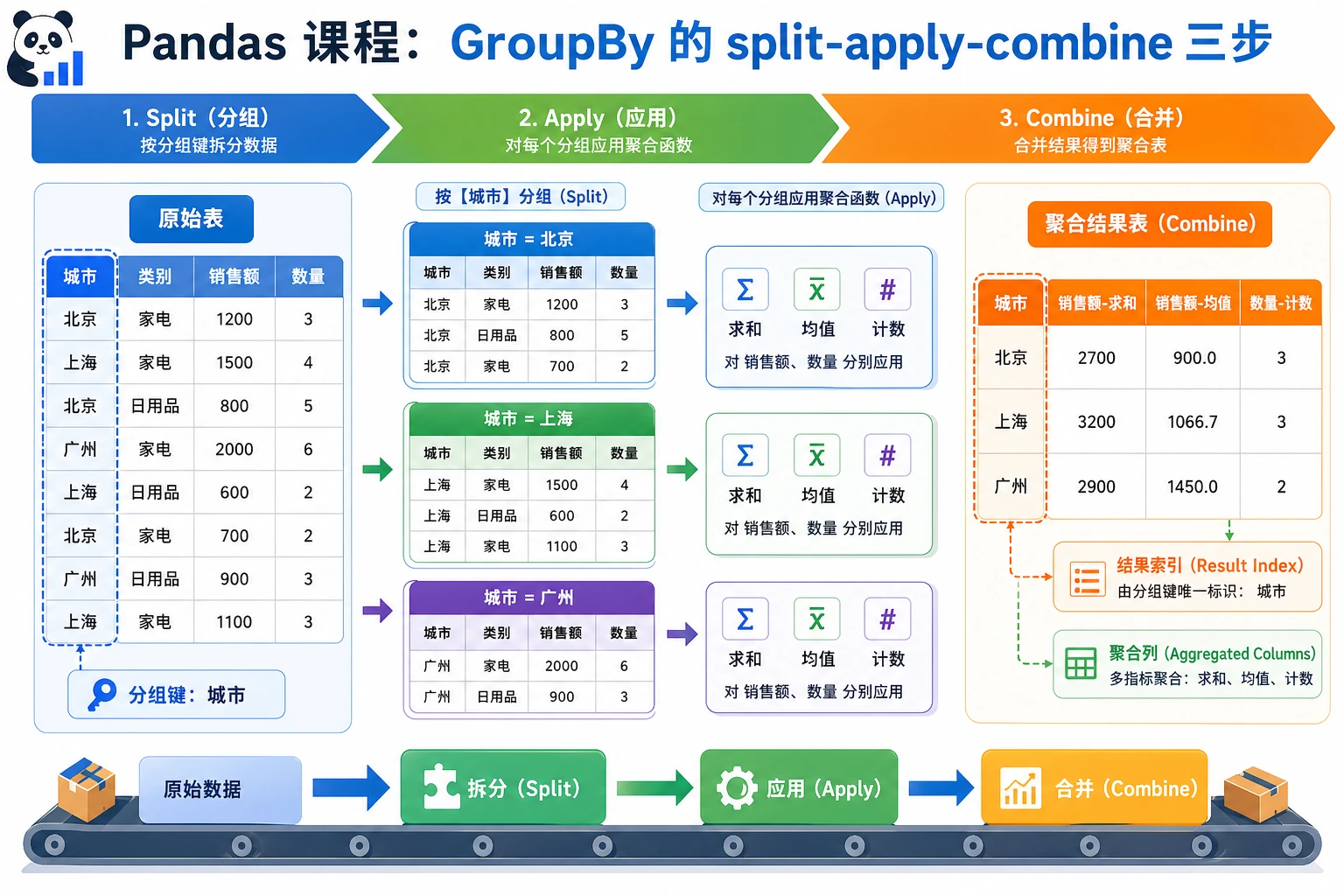
Section titled “先建立一张地图”groupby 更适合按“拆分 -> 应用 -> 合并”来理解:
flowchart LR A["原始表"] --> B["按某个字段拆成多组"] B --> C["每组单独做统计"] C --> D["把结果重新合起来"]所以这节真正想解决的是:
- 为什么
groupby能把很多“按部门 / 按类别 / 按月份统计”的题一把抓住 agg / transform / filter / pivot_table各自到底在补什么
为什么 groupby 这么重要?
Section titled “为什么 groupby 这么重要?”回想第 1 章——用纯 Python 做”按性别统计生存率”,需要手写字典和循环。用 Pandas 的 groupby 一行搞定:
# 纯 Python:15 行代码# Pandas:1 行df.groupby("Sex")["Survived"].mean()groupby 就像 SQL 的 GROUP BY——按某个字段分组,然后对每组分别计算。
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把 groupby 理解成:
- 先把同类东西分成几堆,再分别数、算、比较
比如:
- 按部门分
- 按城市分
- 按月份分
这会比你脑子里一直想着“Pandas 语法”更容易抓住本质。
groupby 基础
Section titled “groupby 基础”flowchart LR A["原始数据"] --> B["拆分<br/>Split"] B --> C1["组1"] B --> C2["组2"] B --> C3["组3"] C1 --> D["应用<br/>Apply"] C2 --> D C3 --> D D --> E["合并<br/>Combine"] E --> F["结果"]import pandas as pdimport numpy as np
df = pd.DataFrame({ "部门": ["技术", "市场", "技术", "管理", "市场", "技术", "管理"], "姓名": ["张三", "李四", "王五", "赵六", "钱七", "孙八", "周九"], "薪资": [15000, 18000, 22000, 35000, 20000, 19000, 30000], "年龄": [22, 28, 25, 35, 30, 24, 40]})
# 按部门分组,计算平均薪资result = df.groupby("部门")["薪资"].mean()print(result)# 部门# 市场 19000.0# 技术 18666.7# 管理 32500.0grouped = df.groupby("部门")
# 常用聚合函数print(grouped["薪资"].sum()) # 总薪资print(grouped["薪资"].mean()) # 平均薪资print(grouped["薪资"].median()) # 中位数print(grouped["薪资"].min()) # 最低薪资print(grouped["薪资"].max()) # 最高薪资print(grouped["薪资"].std()) # 标准差print(grouped["薪资"].count()) # 人数# 对多列聚合print(df.groupby("部门")[["薪资", "年龄"]].mean())# 薪资 年龄# 部门# 市场 19000.0 29.000000# 技术 18666.7 23.666667# 管理 32500.0 37.500000df2 = pd.DataFrame({ "部门": ["技术", "技术", "市场", "市场", "技术", "市场"], "级别": ["初级", "高级", "初级", "高级", "初级", "初级"], "薪资": [15000, 25000, 12000, 22000, 18000, 14000]})
# 按部门和级别分组result = df2.groupby(["部门", "级别"])["薪资"].mean()print(result)# 部门 级别# 市场 初级 13000.0# 高级 22000.0# 技术 初级 16500.0# 高级 25000.0第一次做分组题时,最稳的默认顺序
Section titled “第一次做分组题时,最稳的默认顺序”更稳的顺序通常是:
- 先问自己按谁分
- 再问每组里要算什么
- 最后再决定返回的是汇总表,还是要写回原表
这一步很关键,因为它会直接决定你后面该用:
aggtransformfilter
哪一种。
agg:多种聚合一起做
Section titled “agg:多种聚合一起做”agg 让你对同一列或不同列应用不同的聚合函数:
# 对薪资列同时计算多个统计量result = df.groupby("部门")["薪资"].agg(["mean", "min", "max", "count"])print(result)# mean min max count# 部门# 市场 19000.0 18000 20000 2# 技术 18666.7 15000 22000 3# 管理 32500.0 30000 35000 2# 对不同列用不同的聚合函数result = df.groupby("部门").agg({ "薪资": ["mean", "max"], "年龄": ["mean", "min"], "姓名": "count" # 人数})print(result)
# 自定义聚合函数result = df.groupby("部门")["薪资"].agg( 平均薪资="mean", 最高薪资="max", 薪资差距=lambda x: x.max() - x.min())print(result)什么时候最适合先想到 agg?
Section titled “什么时候最适合先想到 agg?”当你脑子里的问题长得像:
- “每个部门的平均值、最大值、人数分别是多少?”
这时通常就该先想到:
groupby(...).agg(...)
也就是说,agg 最适合:
- 一次性做多种汇总统计
transform:分组转换
Section titled “transform:分组转换”transform 对每组应用函数,但返回和原数据同样长度的结果——非常适合生成新列。
# 场景:给每个人标注"与部门平均薪资的差距"df["部门平均薪资"] = df.groupby("部门")["薪资"].transform("mean")df["薪资差距"] = df["薪资"] - df["部门平均薪资"]print(df[["姓名", "部门", "薪资", "部门平均薪资", "薪资差距"]])
# 场景:组内标准化(每组减去均值除以标准差)df["薪资_标准化"] = df.groupby("部门")["薪资"].transform( lambda x: (x - x.mean()) / x.std() if x.std() > 0 else 0)一个很适合初学者先记的对比表
Section titled “一个很适合初学者先记的对比表”| 方法 | 最值得先记住的返回结果 |
|---|---|
agg | 每组一条汇总结果 |
transform | 行数不变,只是补一列“组内统计” |
filter | 把整组留下或删掉 |
pivot_table | 把结果整理成交叉表 |
这个表特别适合新人,因为它能把最容易混的几种方式重新拉开。
filter:分组过滤
Section titled “filter:分组过滤”filter 根据条件保留或排除整个组:
# 只保留平均薪资 > 20000 的部门result = df.groupby("部门").filter(lambda x: x["薪资"].mean() > 20000)print(result)# 只有"管理"部门的平均薪资 > 20000,所以只保留管理部门的人
# 只保留人数 >= 3 的部门result = df.groupby("部门").filter(lambda x: len(x) >= 3)print(result)数据透视表(pivot_table)
Section titled “数据透视表(pivot_table)”透视表是 Excel 用户最熟悉的功能——Pandas 也完美支持。
# 准备销售数据sales = pd.DataFrame({ "日期": ["1月", "1月", "2月", "2月", "1月", "2月"], "商品": ["苹果", "牛奶", "苹果", "牛奶", "面包", "面包"], "销量": [50, 30, 60, 25, 40, 45], "金额": [250, 240, 300, 200, 120, 135]})
# 透视表:每月每种商品的总销量pivot = pd.pivot_table( sales, values="销量", # 聚合的值 index="商品", # 行 columns="日期", # 列 aggfunc="sum" # 聚合方式)print(pivot)# 日期 1月 2月# 商品# 牛奶 30 25# 苹果 50 60# 面包 40 45
# 多个聚合pivot2 = pd.pivot_table( sales, values="金额", index="商品", columns="日期", aggfunc=["sum", "mean"], margins=True # 添加合计行和列)print(pivot2)交叉表(crosstab)
Section titled “交叉表(crosstab)”# 统计部门和级别的人数分布ct = pd.crosstab(df2["部门"], df2["级别"])print(ct)# 级别 初级 高级# 部门# 市场 2 1# 技术 2 1
# 加上合计和占比ct2 = pd.crosstab(df2["部门"], df2["级别"], margins=True, normalize="index")print(ct2) # 每行占比(各部门中初级/高级的比例)实战:销售数据分组分析
Section titled “实战:销售数据分组分析”import pandas as pdimport numpy as np
rng = np.random.default_rng(seed=42)n = 200
orders = pd.DataFrame({ "月份": rng.choice(["1月", "2月", "3月", "4月"], n), "区域": rng.choice(["华东", "华南", "华北", "西南"], n), "商品": rng.choice(["手机", "电脑", "耳机", "平板"], n), "销量": rng.integers(1, 50, n), "单价": rng.choice([99, 299, 999, 2999, 5999], n)})orders["金额"] = orders["销量"] * orders["单价"]
# 1. 每个区域的总销售额print(orders.groupby("区域")["金额"].sum().sort_values(ascending=False))
# 2. 每种商品的平均销量和总金额print(orders.groupby("商品").agg( 平均销量=("销量", "mean"), 总金额=("金额", "sum"), 订单数=("金额", "count")))
# 3. 透视表:区域 × 商品的总金额print(pd.pivot_table(orders, values="金额", index="区域", columns="商品", aggfunc="sum"))
# 4. 每个月销售额最高的区域monthly_top = orders.groupby(["月份", "区域"])["金额"].sum().reset_index()idx = monthly_top.groupby("月份")["金额"].idxmax()print(monthly_top.loc[idx])学完这一页,至少保留这张证据卡:
- 数据框状态
- 列、数据类型、行数、缺失值和样本行
- 操作
- 读/写、select/filter、清洗、转换、groupby、merge,或时间序列步骤
- 输出
- 结果表、保存的文件、聚合、连接结果,或时间索引视图
- 失败检查
- dtype 不匹配、缺失数据、重复键、链式赋值或时间频率错误
- 期望产出
- 前后对比表格样本,以及转换原因
| 操作 | 方法 | 返回行数 | 用途 |
|---|---|---|---|
| 基本聚合 | groupby().mean() 等 | 组数 | 汇总统计 |
| 多重聚合 | groupby().agg() | 组数 | 多种统计量 |
| 分组转换 | groupby().transform() | 原始行数 | 生成新列 |
| 分组过滤 | groupby().filter() | ≤ 原始行数 | 按条件保留组 |
| 透视表 | pivot_table() | 行值种数 | 交叉统计 |
| 交叉表 | crosstab() | 行值种数 | 频次统计 |
练习 1:基本分组
Section titled “练习 1:基本分组”# 用上面的 orders 数据# 1. 按月份统计平均客单价(金额/销量)# 2. 哪个月份哪种商品的销量最高?# 3. 每个区域卖得最好的商品是什么?练习 2:transform 应用
Section titled “练习 2:transform 应用”# 1. 给每个订单添加"区域平均金额"列# 2. 标记每个订单的金额是否高于其所在区域的平均水平# 3. 计算每个订单金额占其区域总金额的百分比练习 3:透视表
Section titled “练习 3:透视表”# 1. 创建一个透视表:行=区域,列=月份,值=总金额,带合计# 2. 哪个区域在哪个月份的销售额最高?参考实现与讲解
- 客单价是总金额除以订单数,所以要同时计算分子和分母,不要对已经平均过的行再求平均。
- 查每月或每地区最佳产品时,先聚合到正确粒度,再排序或用
idxmax。直接取原始行最大值,在同一产品出现多次时会出错。 - 当每条原始记录都需要附上组级信息时用
transform,例如地区均值或月销售占比;当输出应为每组一行时用agg。