6.3.5 迁移学习
- 解释为什么从零训练 CNN 往往很浪费。
- 区分 pretrained backbone 和 classification head。
- 冻结 backbone,只训练新的 head。
- 用更小学习率解冻最后一个卷积 block 做微调。
- 避免数据泄漏、破坏性微调等常见迁移学习错误。
先看决策流程
Section titled “先看决策流程”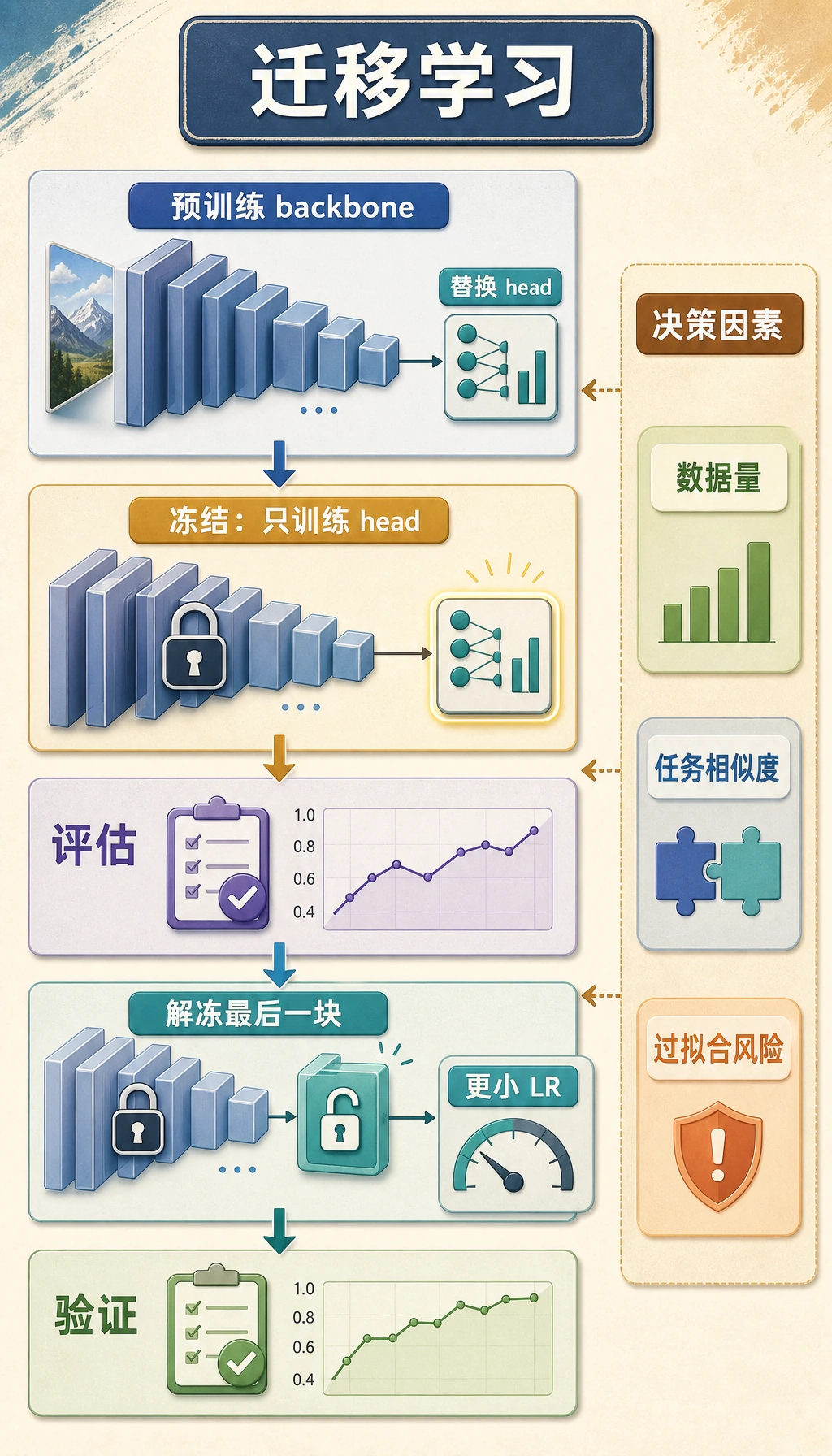
按这条线读图:
pretrained backbonereplace headtrain headvalidate必要时解冻后面层
两个问题决定选择:
| 问题 | 数据少 / 任务相近 | 数据多 / 任务差异大 |
|---|---|---|
| 你有多少标注数据? | 先冻结大部分层 | 谨慎微调更多层 |
| 新任务和原任务像不像? | 预训练特征可能迁移得很好 | 后面层可能需要适配 |
本节用纯 PyTorch 和合成图像,所以不需要下载 torchvision 权重也能运行。真实项目中,backbone 通常来自预训练的 torchvision 或 timm 模型。
| 术语 | 含义 |
|---|---|
| backbone | 特征提取器,通常是最终分类器之前的所有层 |
| head | 接在 backbone 后面的任务相关分类器或回归器 |
| freeze | 设置 requires_grad=False,让参数不更新 |
| fine-tune | 解冻一部分预训练层并继续训练 |
| logits | softmax 之前的原始类别分数 |
实践规则:
数据少 -> 先训练 head效果不够 -> 用更小学习率解冻后面的 backbone 层完整实验:离线模拟迁移学习
Section titled “完整实验:离线模拟迁移学习”这个实验有三个阶段:
- 在简单线条图案上预训练一个 tiny backbone。
- 在新的目标任务上复用 backbone,只训练 head。
- 解冻最后一个卷积层,用更小学习率轻微微调。
运行完整脚本:
import copyimport numpy as npimport torchfrom torch import nn
SEED = 7np.random.seed(SEED)torch.manual_seed(SEED)
def make_image(label, task, size=16, noise=0.05): img = np.zeros((size, size), dtype=np.float32) c = size // 2
if task == "source": if label == 0: img[:, c] = 1.0 elif label == 1: img[c, :] = 1.0 else: for i in range(size): img[i, i] = 1.0 elif task == "target": if label == 0: img[:, c] = 1.0 img[c, :] = 1.0 elif label == 1: for i in range(size): img[i, size - 1 - i] = 1.0 else: img[3:-3, 3] = 1.0 img[3:-3, -4] = 1.0 img[3, 3:-3] = 1.0 img[-4, 3:-3] = 1.0
img += np.random.randn(size, size).astype(np.float32) * noise return np.clip(img, 0.0, 1.0)
def make_dataset(task, per_class, size=16): X, y = [], [] for label in range(3): for _ in range(per_class): X.append(make_image(label, task, size=size)) y.append(label) X = torch.tensor(np.array(X)).unsqueeze(1) y = torch.tensor(np.array(y), dtype=torch.long) return X, y
class TinyBackbone(nn.Module): def __init__(self): super().__init__() self.features = nn.Sequential( nn.Conv2d(1, 8, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(2), nn.Conv2d(8, 16, kernel_size=3, padding=1), nn.ReLU(), nn.AdaptiveAvgPool2d((1, 1)), )
def forward(self, x): return self.features(x).flatten(1)
class ImageClassifier(nn.Module): def __init__(self, backbone=None, num_classes=3): super().__init__() self.backbone = backbone if backbone is not None else TinyBackbone() self.head = nn.Linear(16, num_classes)
def forward(self, x): return self.head(self.backbone(x))
def accuracy(model, X, y): with torch.no_grad(): return (model(X).argmax(dim=1) == y).float().mean().item()
def train(model, X, y, optimizer, epochs, label, print_every): loss_fn = nn.CrossEntropyLoss() for epoch in range(1, epochs + 1): logits = model(X) loss = loss_fn(logits, y)
optimizer.zero_grad() loss.backward() optimizer.step()
if epoch == 1 or epoch % print_every == 0: acc = accuracy(model, X, y) print(f"{label} epoch={epoch:02d} loss={loss.item():.4f} acc={acc:.3f}")
source_X, source_y = make_dataset("source", per_class=80)target_train_X, target_train_y = make_dataset("target", per_class=12)target_val_X, target_val_y = make_dataset("target", per_class=40)
# Stage 1: pretrain a source model.source_model = ImageClassifier(num_classes=3)train( source_model, source_X, source_y, torch.optim.Adam(source_model.parameters(), lr=0.03), epochs=60, label="pretrain", print_every=20,)
# Stage 2: transfer the backbone and train only a new head.frozen_backbone = copy.deepcopy(source_model.backbone)transfer_model = ImageClassifier(backbone=frozen_backbone, num_classes=3)for p in transfer_model.backbone.parameters(): p.requires_grad = False
print("trainable_after_freeze")for name, p in transfer_model.named_parameters(): print(f"{name:<28} {p.requires_grad}")
train( transfer_model, target_train_X, target_train_y, torch.optim.Adam(transfer_model.head.parameters(), lr=0.05), epochs=20, label="head", print_every=10,)print("head_only_val_acc", round(accuracy(transfer_model, target_val_X, target_val_y), 3))
# Stage 3: unfreeze the last conv layer and fine-tune gently.for p in transfer_model.backbone.features[3].parameters(): p.requires_grad = True
optimizer = torch.optim.Adam( [ {"params": transfer_model.backbone.features[3].parameters(), "lr": 0.0005}, {"params": transfer_model.head.parameters(), "lr": 0.005}, ])train( transfer_model, target_train_X, target_train_y, optimizer, epochs=20, label="finetune", print_every=10,)print("finetune_val_acc", round(accuracy(transfer_model, target_val_X, target_val_y), 3))预期输出:
pretrain epoch=01 loss=1.0995 acc=0.667pretrain epoch=20 loss=0.0000 acc=1.000pretrain epoch=40 loss=0.0000 acc=1.000pretrain epoch=60 loss=0.0000 acc=1.000trainable_after_freezebackbone.features.0.weight Falsebackbone.features.0.bias Falsebackbone.features.3.weight Falsebackbone.features.3.bias Falsehead.weight Truehead.bias Truehead epoch=01 loss=2.4749 acc=0.361head epoch=10 loss=0.7364 acc=0.667head epoch=20 loss=0.4991 acc=0.944head_only_val_acc 0.875finetune epoch=01 loss=0.4759 acc=0.667finetune epoch=10 loss=0.4367 acc=1.000finetune epoch=20 loss=0.4096 acc=1.000finetune_val_acc 1.0
这张图分三步读:
pretrain说明 tiny backbone 已经能提取可复用的线条特征。trainable_after_freeze是安全检查:backbone 保持冻结,只有新的 head 更新。head_only_val_acc=0.875已经可用,而finetune_val_acc=1.0说明只轻微解冻最后卷积层,在这个验证集上确实有帮助。
这个实验说明了什么
Section titled “这个实验说明了什么”| 阶段 | 发生了什么 | 实践含义 |
|---|---|---|
| pretrain | backbone 学到类似线条的视觉特征 | 这里模拟真实预训练模型 |
| freeze | 只有新 head 可训练 | 对小目标数据更快、更安全 |
| train head | 目标验证准确率已经可用 | 复用特征已经有帮助 |
| fine-tune | 最后一个卷积层轻微适配 | 小学习率能降低破坏旧特征的风险 |
微调并不自动更好。如果目标数据很少,或者学习率太大,它可能过拟合,也可能破坏预训练特征。判断标准永远是验证集,而不是训练 loss。
迁移学习实验要保留这条决策记录:
- 冻结检查
- 哪些层的 requires_grad=False
- 头部结果
- 只训练新头部后的验证分数
- 微调结果
- 解冻后层后的验证分数
- 决策
- 根据验证结果而非训练损失决定冻结还是微调
- 风险说明
- 数据规模、领域不匹配、预处理不匹配
这样迁移学习就不是“套一个大模型”,而是可控的工程流程。
真实项目流程
Section titled “真实项目流程”- 在碰模型之前,先切好 train/validation/test。
- 加载预训练 backbone。
- 替换 head,让输出类别数匹配你的任务。
- 冻结 backbone,只训练 head。
- 查看验证集错误。
- 如有必要,解冻后面的 block,并给 backbone 更小学习率。
- 验证集不再提升时停止。
对真实图片,还要匹配预训练权重期待的预处理:输入尺寸、归一化 mean/std、颜色通道顺序。
冻结还是微调?
Section titled “冻结还是微调?”| 情况 | 起步选择 |
|---|---|
| 数据很少,任务相近 | 冻结 backbone,只训练 head |
| 中等数据,任务相近 | 先冻结,再解冻最后一个 block |
| 数据较多,视觉领域不同 | 谨慎微调更多 block |
| 医疗、遥感、工业图像 | 认真验证;自然图像预训练特征可能只部分迁移 |
| 部署设备受限 | 先用更小 backbone 或 freeze-and-head baseline |
| 错误 | 为什么有问题 | 修复 |
|---|---|---|
| 一开始就微调所有层 | 小数据上不稳定 | 先训练 head |
| 所有层用同一个学习率 | backbone 更新太猛 | 给预训练层更小 LR |
忘记检查 requires_grad | 错误层静悄悄地训练 | 打印可训练参数 |
| 只在训练集评估 | 看不出过拟合 | 保留验证集 |
| 预处理不匹配 | 预训练特征收到陌生输入尺度 | 使用权重要求的 transform |
| split 泄漏 | 验证集失去意义 | 必要时按图片来源、用户或物体分组切分 |
- 增加第 4 个目标类别,并设计一个新的合成图案。
- 把目标训练数据从每类
12张增加到40张,只训 head 会不会更好? - 把 backbone 微调学习率从
0.0005改成0.05,观察发生什么。 - 解冻最后一个卷积后,只打印可训练参数名。
- 解释什么时候 GAP 加小 head 比大型
Flattenhead 更合适。
参考实现与讲解
- 新类别需要同步修改标签生成、类别数、分类头输出维度和评估展示。图案应和原类别有可区分特征。
- 数据更多时,只训 head 通常更稳定,也可能带来更好泛化;是否明显提升取决于目标域和预训练特征是否接近。
0.05对 backbone 往往过大,可能破坏已有特征,表现为 loss 抖动、验证集下降或训练不稳定。- 只打印
requires_grad=True的参数即可确认解冻范围,避免不小心训练整段 backbone。 - GAP 加小 head 参数少、对输入尺寸更稳,适合小数据迁移;大型
Flattenhead 更容易过拟合。
- 迁移学习复用视觉特征,而不是从零重新学一切。
- 最安全的第一个 baseline 通常是:替换 head、冻结 backbone、训练 head。
- 只有验证结果说明有必要时,才微调后面层。
- 预训练层要用更小学习率。
- 好的迁移学习是一套工程流程,不只是复制一个大模型。