9.5.5 MCP 客户端集成
- 理解 MCP 客户端的核心职责
- 学会把“发现工具”和“调用工具”分成两步看
- 看懂一个最小 MCP 客户端调用流程
- 理解客户端侧为什么仍然需要选择策略、失败处理和缓存
客户端和服务器的职责到底怎么分?
Section titled “客户端和服务器的职责到底怎么分?”服务器提供能力
Section titled “服务器提供能力”服务器更像“工具仓库管理员”,它负责:
- 列出工具
- 暴露能力
- 执行调用
客户端负责消费能力
Section titled “客户端负责消费能力”客户端更像“真正来办事的人”,它负责:
- 发现工具
- 决定调用哪个
- 组织参数
- 接收结果
所以非常重要的一点是:
MCP 客户端不是被动转发器,它通常仍然有自己的调用决策逻辑。
客户端最先要学会什么?先发现工具
Section titled “客户端最先要学会什么?先发现工具”为什么不能直接写死?
Section titled “为什么不能直接写死?”如果客户端一开始就把工具全写死:
- 服务器工具一变就要改代码
- 换一个服务器也要重写
这和 MCP 想解决的问题正好反着来。
一个最小发现示例
Section titled “一个最小发现示例”class MockMCPServer: def list_tools(self): return [ {"name": "search_docs", "description": "搜索课程文档"}, {"name": "get_weather", "description": "查询天气"} ]
server = MockMCPServer()tools = server.list_tools()
for tool in tools: print(tool)预期输出:
{'name': 'search_docs', 'description': '搜索课程文档'}{'name': 'get_weather', 'description': '查询天气'}这一步在教你什么?
Section titled “这一步在教你什么?”它在教你:
客户端先要知道“能用什么”,再谈“怎么用”。
这就是发现阶段的价值。
发现完以后,客户端还要做什么?
Section titled “发现完以后,客户端还要做什么?”不是所有工具都要调。 客户端通常要先判断:
- 当前问题需不需要工具
- 如果需要,调哪个
就算选对工具,也还要正确组织参数。
如果:
- server 超时
- 工具不存在
- 参数校验失败
client 不能只崩掉,还要决定:
- 要不要重试
- 要不要降级
- 要不要换工具
一个最小客户端示例
Section titled “一个最小客户端示例”class MockMCPServer: def list_tools(self): return [ {"name": "search_docs", "description": "搜索课程文档"}, {"name": "get_weather", "description": "查询天气"} ]
def call_tool(self, name, arguments): if name == "search_docs": return {"result": f"检索结果: {arguments['query']}"} if name == "get_weather": return {"result": f"{arguments['city']} 当前晴天 22 度"} return {"error": "unknown_tool"}
class MockMCPClient: def __init__(self, server): self.server = server self.tools = []
def discover(self): self.tools = self.server.list_tools() return self.tools
def call(self, name, arguments): return self.server.call_tool(name, arguments)
server = MockMCPServer()client = MockMCPClient(server)
print(client.discover())print(client.call("search_docs", {"query": "退款政策"}))预期输出:
[{'name': 'search_docs', 'description': '搜索课程文档'}, {'name': 'get_weather', 'description': '查询天气'}]{'result': '检索结果: 退款政策'}这段代码已经在说明什么?
Section titled “这段代码已经在说明什么?”它已经体现了客户端的两大主功能:
- 发现
- 调用
这就是 MCP 客户端的最小闭环。
客户端其实还有“策略层”
Section titled “客户端其实还有“策略层””为什么说客户端不只是协议调用器?
Section titled “为什么说客户端不只是协议调用器?”因为真实系统里,客户端往往还要决定:
- 当前问题需不需要走 MCP
- 如果走,优先哪个服务器 / 哪个工具
- 失败后如何回退
一个简单工具选择器
Section titled “一个简单工具选择器”请接着上一段 client 示例,在同一个 Python 文件或同一个解释器会话里运行,因为这里会继续使用 client。
def choose_tool(user_query, tools): tool_names = [t["name"] for t in tools]
if "退款" in user_query and "search_docs" in tool_names: return {"name": "search_docs", "arguments": {"query": "退款政策"}}
if "天气" in user_query and "get_weather" in tool_names: return {"name": "get_weather", "arguments": {"city": "北京"}}
return None
tools = client.discover()decision = choose_tool("退款政策是什么?", tools)print(decision)print(client.call(decision["name"], decision["arguments"]))预期输出:
{'name': 'search_docs', 'arguments': {'query': '退款政策'}}{'result': '检索结果: 退款政策'}这说明客户端往往还承担一层轻量调度职责。
错误处理为什么对客户端特别重要?
Section titled “错误处理为什么对客户端特别重要?”因为客户端是“最先感知失败的一方”
Section titled “因为客户端是“最先感知失败的一方””服务器那边可能返回:
- unknown_tool
- invalid_arguments
- timeout
而客户端必须决定接下来怎么做。
一个最小错误处理示例
Section titled “一个最小错误处理示例”继续在同一个文件或会话中运行,确保前面的 client 已经定义。
def safe_call(client, name, arguments): result = client.call(name, arguments) if "error" in result: return {"ok": False, "fallback": "当前工具不可用,请稍后重试。"} return {"ok": True, "data": result["result"]}
print(safe_call(client, "search_docs", {"query": "退款政策"}))print(safe_call(client, "bad_tool", {}))预期输出:
{'ok': True, 'data': '检索结果: 退款政策'}{'ok': False, 'fallback': '当前工具不可用,请稍后重试。'}这一步让系统从:
- “一错就崩”
变成:
- “一错也能兜住”
为什么有时客户端也需要缓存?
Section titled “为什么有时客户端也需要缓存?”一个很现实的问题
Section titled “一个很现实的问题”如果你每次请求都重新 list_tools(),会不会浪费?
很多时候:
- 工具列表变化没那么频繁
- 每次重新发现会增加延迟
一个最小缓存思路
Section titled “一个最小缓存思路”继续在同一个文件或会话中运行,确保 MockMCPClient 和 server 已经定义。
class CachedMCPClient(MockMCPClient): def discover_once(self): if not self.tools: self.tools = self.server.list_tools() return self.tools
cached_client = CachedMCPClient(server)print(cached_client.discover_once())print(cached_client.discover_once())预期输出:
[{'name': 'search_docs', 'description': '搜索课程文档'}, {'name': 'get_weather', 'description': '查询天气'}][{'name': 'search_docs', 'description': '搜索课程文档'}, {'name': 'get_weather', 'description': '查询天气'}]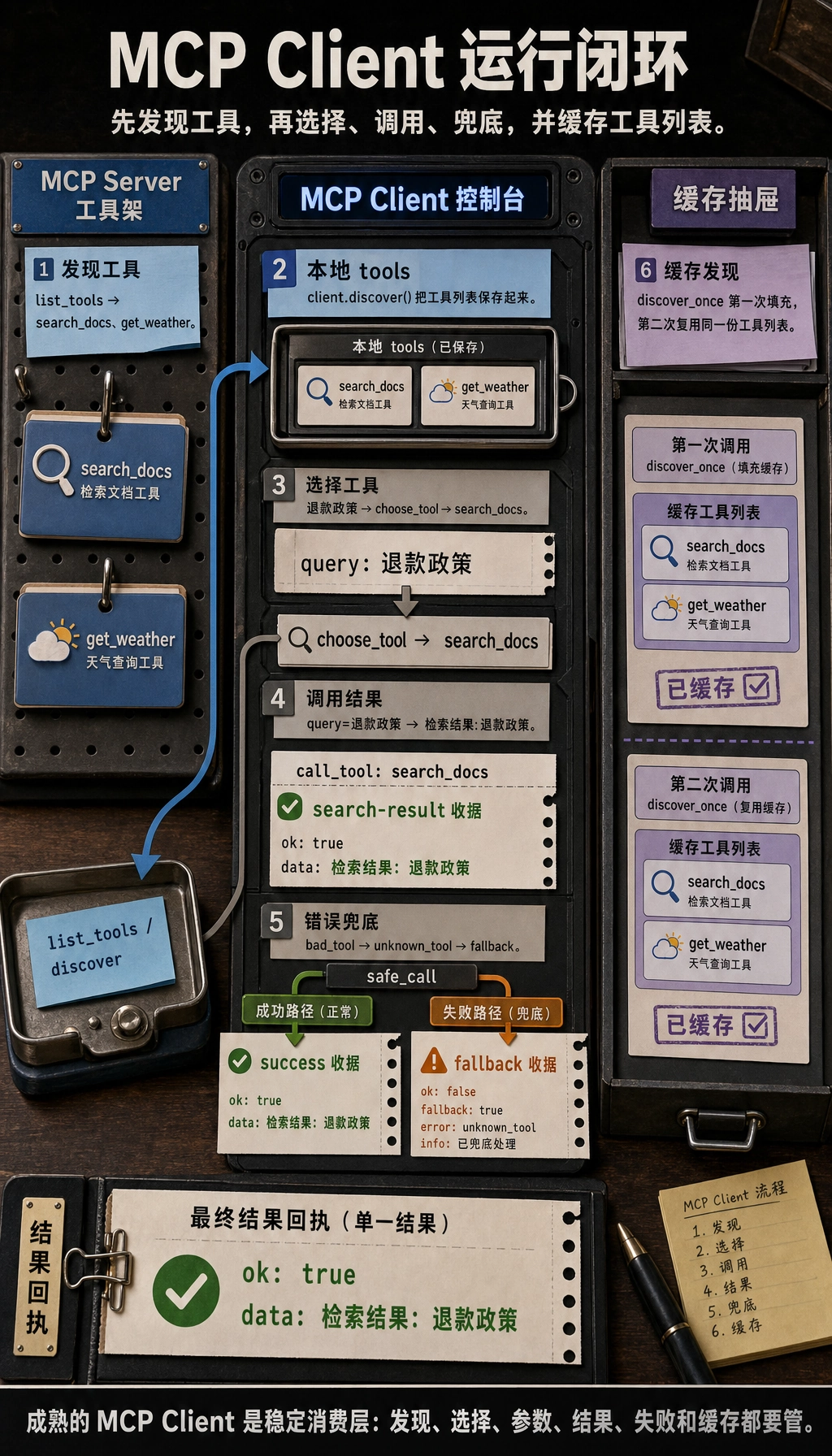
这虽然简单,但已经体现出:
客户端也不只是“转发器”,它本身也有状态和优化空间。
客户端集成里最常见的坑
Section titled “客户端集成里最常见的坑”只会调,不会选
Section titled “只会调,不会选”如果客户端不做选择策略,很容易:
- 工具虽多,但不会用
只看成功,不看失败路径
Section titled “只看成功,不看失败路径”一旦服务器出错,系统体验就会突然变差。
每次都重新发现工具
Section titled “每次都重新发现工具”可能会浪费很多不必要的开销。
学完这一页,至少保留这张证据卡:
- 能力
- 服务器暴露的资源、Prompt 或工具
- 契约
- schema、传输、权限和错误形式
- 调用轨迹
- 发现、调用、响应和失败处理
- 失败检查
- 架构不兼容、缺少认证、不安全工具或服务器错误
- 集成动作
- 在加入自主能力前先验证服务端契约
这一节最重要的不是写出一个能调服务器的类,而是理解:
MCP 客户端的核心,不只是“发请求”,而是把“发现工具、选择工具、组织参数、处理结果”整成一个稳定消费层。
客户端做得越成熟,服务器侧的能力就越容易真正被上层系统利用。
- 给
MockMCPServer再加一个read_file工具,然后扩展客户端选择逻辑。 - 想一想:为什么有些系统适合每次都重新发现工具,而有些适合做缓存?
- 给
safe_call()再加一个“出错后重试一次”的逻辑。 - 用自己的话解释:为什么说 MCP 客户端通常还要有“策略层”?
参考实现与讲解
- 一个合格的
read_file接入,要先在 server 侧增加 tool schema,让 client 能发现它,然后只有在路径权限或安全 allowlist 检查通过后,才把读文件请求路由到这个 tool。 - 工具动态变化、server 经常变化时,每次重新发现更合适;契约稳定、启动成本敏感、重复发现只会增加延迟时,缓存更合适。
- 安全的重试只应该用于临时失败,要在 trace 里记录两次尝试,并且只重试一次。权限错误、参数校验错误或高风险操作不应该盲目重试。
- client 需要策略层,是因为发现只说明“能调用什么”。client 仍然要决定何时调用、选择哪个 tool、失败后如何恢复,以及如何把结果接回 Agent 循环。