7.2.1 LLM 概览路线图:能力、成本、产品适配
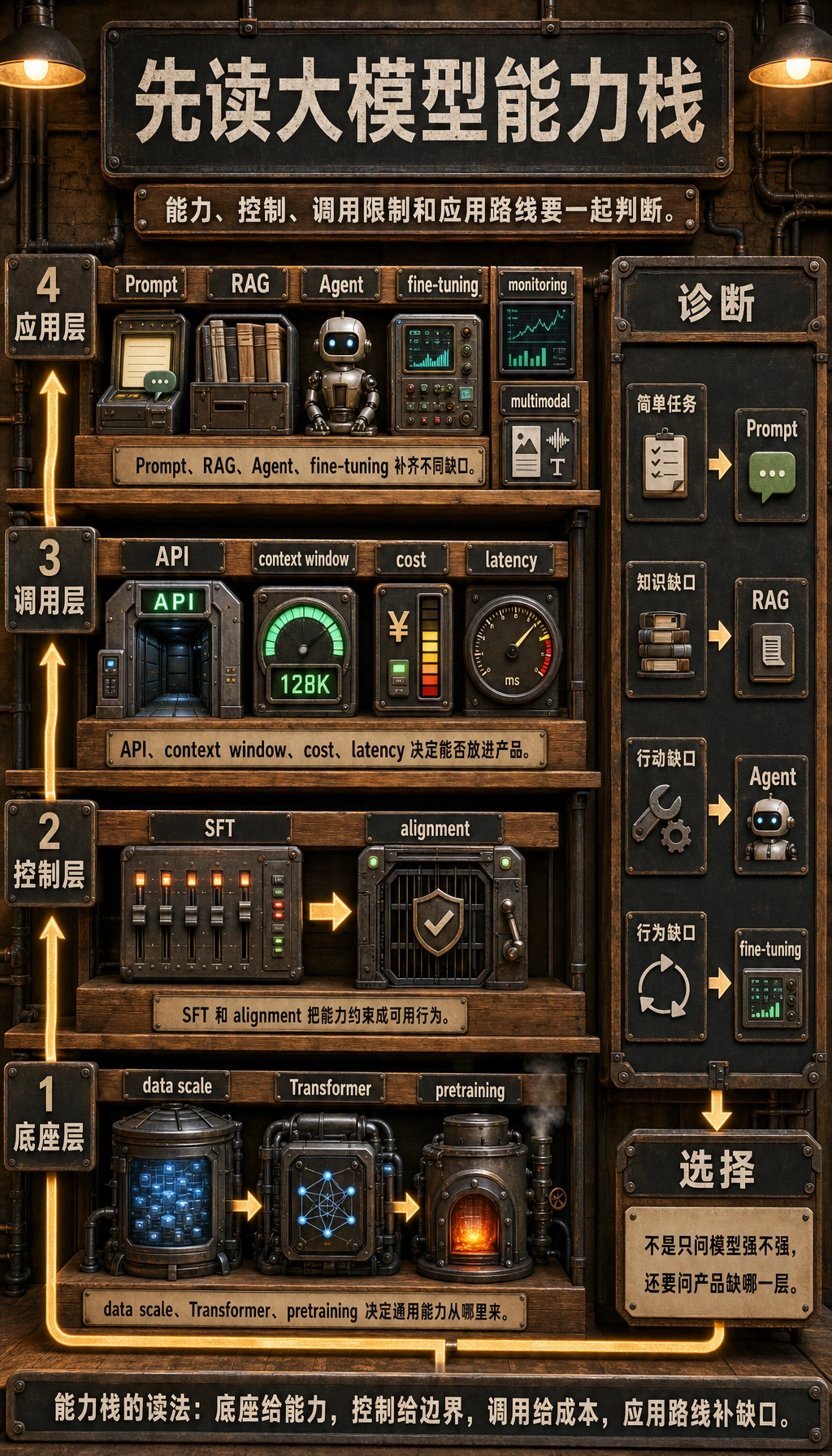
LLM 概览不是模型名称清单,而是帮你判断大模型能做什么、代价是什么,以及什么时候该用 Prompt、RAG、Agent 或微调。
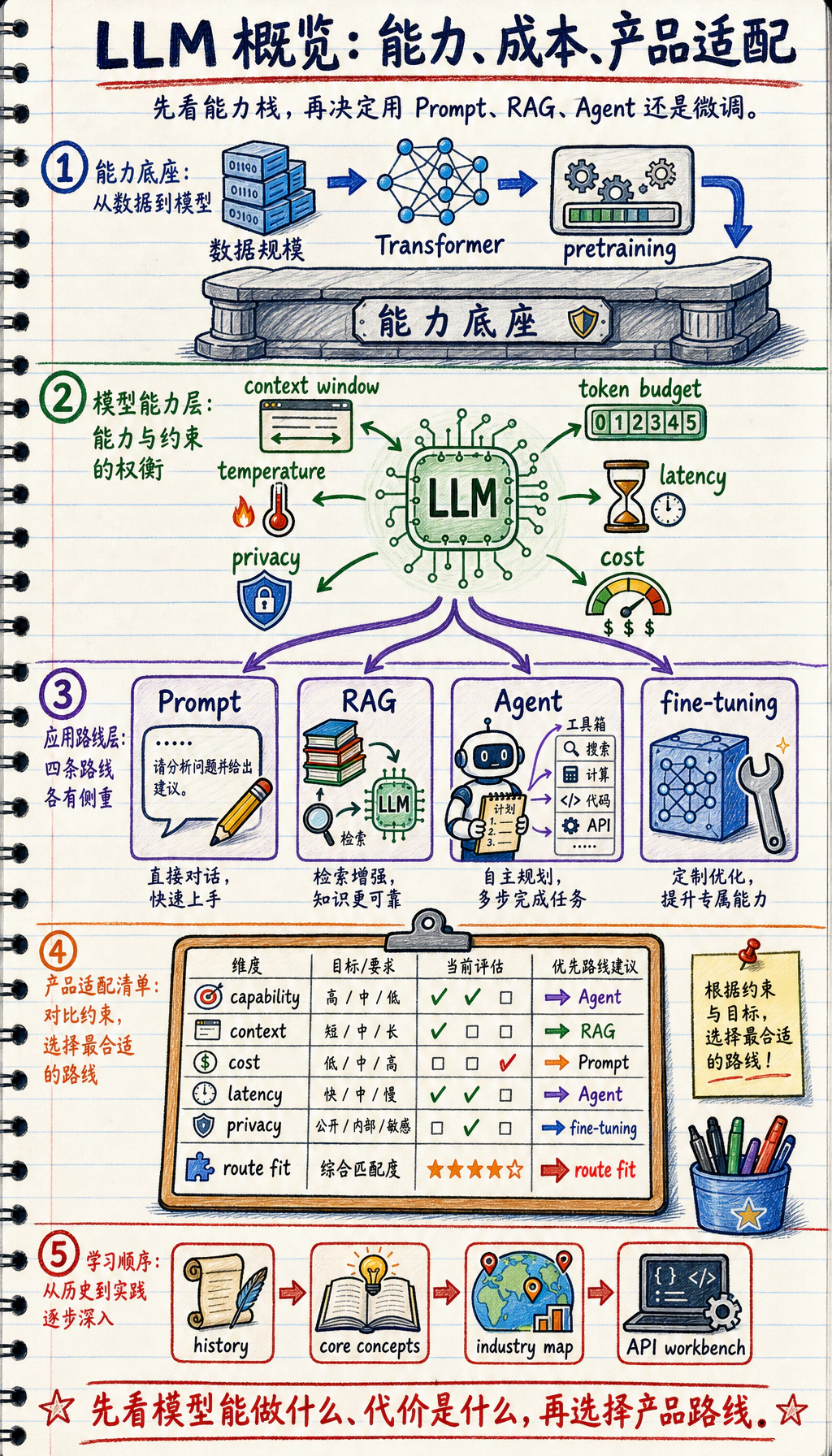
| 路线 | 适合什么时候 |
|---|---|
| prompt | 模型本身已经足够懂,任务简单 |
| RAG | 私有或会变化的知识需要引用 |
| Agent | 模型需要用工具或分步骤行动 |
| 微调 | 行为、风格、格式需要长期适配 |
跑一次路线判断
Section titled “跑一次路线判断”request = { "needs_private_docs": True, "needs_tool_action": False, "needs_repeated_style": False,}
if request["needs_tool_action"]: route = "Agent"elif request["needs_private_docs"]: route = "RAG"elif request["needs_repeated_style"]: route = "fine-tuning"else: route = "prompt"
print("recommended_route:", route)预期输出:
recommended_route: RAG
这不是完整架构决策,只是在训练习惯:选择能解决实际产品问题的最小路线。
按这个顺序学
Section titled “按这个顺序学”| 顺序 | 阅读 | 留下什么 |
|---|---|---|
| 1 | 7.2.2 发展历史 | 为什么 scaling 和指令微调重要 |
| 2 | 7.2.3 核心概念 | 上下文、token、temperature、延迟、成本 |
| 3 | 7.2.4 产业图谱 | 模型/供应商选择记录 |
| 4 | 7.2.5 LLM 调用工作台 | 一条请求/响应记录 |
学完这一页,至少保留这张证据卡:
- 能力栈
- tokens、上下文、预训练、指令、对齐
- 成本检查
- 上下文长度和输出长度会影响成本/延迟
- 产品契合
- 按任务需求选择模型行为,而不是看噱头
- 评估循环
- 固定案例、分数、失败说明
- 下一步动作
- 把概览与 7.5 中的 Prompt 测试连接起来
能从能力、上下文、成本、延迟、数据隐私和路线适配解释一次模型选择,就算通过。
检查思路与讲解
- 合格答案要说明 token、上下文、attention、prompt 和生成行为如何组成一次请求到回答的路径。
- 证据至少包含一个可复现 prompt 或结构化输出测试,并说明输出为什么通过或失败。
- 自检时要区分 prompt、RAG、微调和对齐:优先使用能解决已观察问题的最轻方案。