6.2.2 从 sklearn 到 PyTorch
- 理解
sklearn和PyTorch的职责差异 - 建立数据、模型、损失函数、优化器、训练循环的整体心智模型
- 用一个最小例子同时跑通
sklearn和PyTorch - 明白为什么深度学习需要 PyTorch 这种“更底层”的框架
一、为什么学完 sklearn 还要学 PyTorch?
Section titled “一、为什么学完 sklearn 还要学 PyTorch?”在第 5 站里,你已经用过 scikit-learn:
from sklearn.linear_model import LinearRegression
model = LinearRegression()model.fit(X_train, y_train)pred = model.predict(X_test)这套体验很舒服,但也意味着很多东西被“藏起来”了:
| 你做的事 | sklearn 帮你做了什么 |
|---|---|
| 选模型 | 定义了参数结构 |
调 fit() | 自动完成前向计算、求损失、求梯度、更新参数 |
调 predict() | 自动完成推理 |
而在 PyTorch 中,这些步骤要拆开来写:
| 步骤 | 你需要自己处理什么 |
|---|---|
| 准备数据 | 把数据转成 Tensor |
| 定义模型 | 用 nn.Module 或 nn.Sequential 写网络 |
| 定义损失函数 | 例如 nn.MSELoss() |
| 定义优化器 | 例如 torch.optim.SGD() |
| 训练循环 | forward -> loss -> backward -> step |
这看起来更麻烦,但换来的好处是:
- 你可以定义任何网络结构
- 你可以控制训练过程的每一步
- 你可以做 CNN、RNN、Transformer、大模型微调这些
sklearn很难覆盖的事
二、把两者放在一张图里看
Section titled “二、把两者放在一张图里看”
- 在
sklearn里,这条链路大多被包进了fit() - 在
PyTorch里,这条链路会完整暴露出来
所以 PyTorch 的学习重点不是“多几个 API”,而是: 你开始真正接触模型训练的内部结构。
三、一个最小对照实验
Section titled “三、一个最小对照实验”我们来做一个最简单的线性回归任务:已知学习时长,预测考试分数。
用 sklearn 训练
Section titled “用 sklearn 训练”import numpy as npfrom sklearn.linear_model import LinearRegression
# 学习时长(小时)X = np.array([[1.0], [2.0], [3.0], [4.0], [5.0]], dtype=np.float32)
# 对应分数y = np.array([52.0, 59.0, 66.0, 73.0, 80.0], dtype=np.float32)
sk_model = LinearRegression()sk_model.fit(X, y)
print("sklearn 截距:", round(float(sk_model.intercept_), 2))print("sklearn 权重:", round(float(sk_model.coef_[0]), 2))print("学习 6 小时的预测分数:", round(float(sk_model.predict([[6.0]])[0]), 2))期望输出:
sklearn 截距: 45.0sklearn 权重: 7.0学习 6 小时的预测分数: 87.0你会得到一条直线模型,过程非常顺滑:fit() 已经帮你找到 score = 7 * hours + 45 这条线。
用 PyTorch 训练同一个任务
Section titled “用 PyTorch 训练同一个任务”import torchfrom torch import nn
torch.manual_seed(42)
# 1. 数据转成张量X_torch = torch.tensor([[1.0], [2.0], [3.0], [4.0], [5.0]])y_torch = torch.tensor([[52.0], [59.0], [66.0], [73.0], [80.0]])
# 2. 定义模型:一个线性层 y = wx + bmodel = nn.Linear(in_features=1, out_features=1)
# 3. 定义损失函数loss_fn = nn.MSELoss()
# 4. 定义优化器optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 5. 训练循环for epoch in range(1000): pred = model(X_torch) # forward loss = loss_fn(pred, y_torch) # 计算损失
optimizer.zero_grad() # 清空旧梯度 loss.backward() # backward optimizer.step() # 更新参数
if epoch % 200 == 0: print(f"epoch={epoch:4d}, loss={loss.item():.4f}")
weight = model.weight.item()bias = model.bias.item()pred_6 = model(torch.tensor([[6.0]])).item()
print("PyTorch 截距:", round(bias, 2))print("PyTorch 权重:", round(weight, 2))print("学习 6 小时的预测分数:", round(pred_6, 2))期望输出:
epoch= 0, loss=4031.2007epoch= 200, loss=72.9774epoch= 400, loss=18.8304epoch= 600, loss=4.8588epoch= 800, loss=1.2537PyTorch 截距: 43.67PyTorch 权重: 7.37学习 6 小时的预测分数: 87.88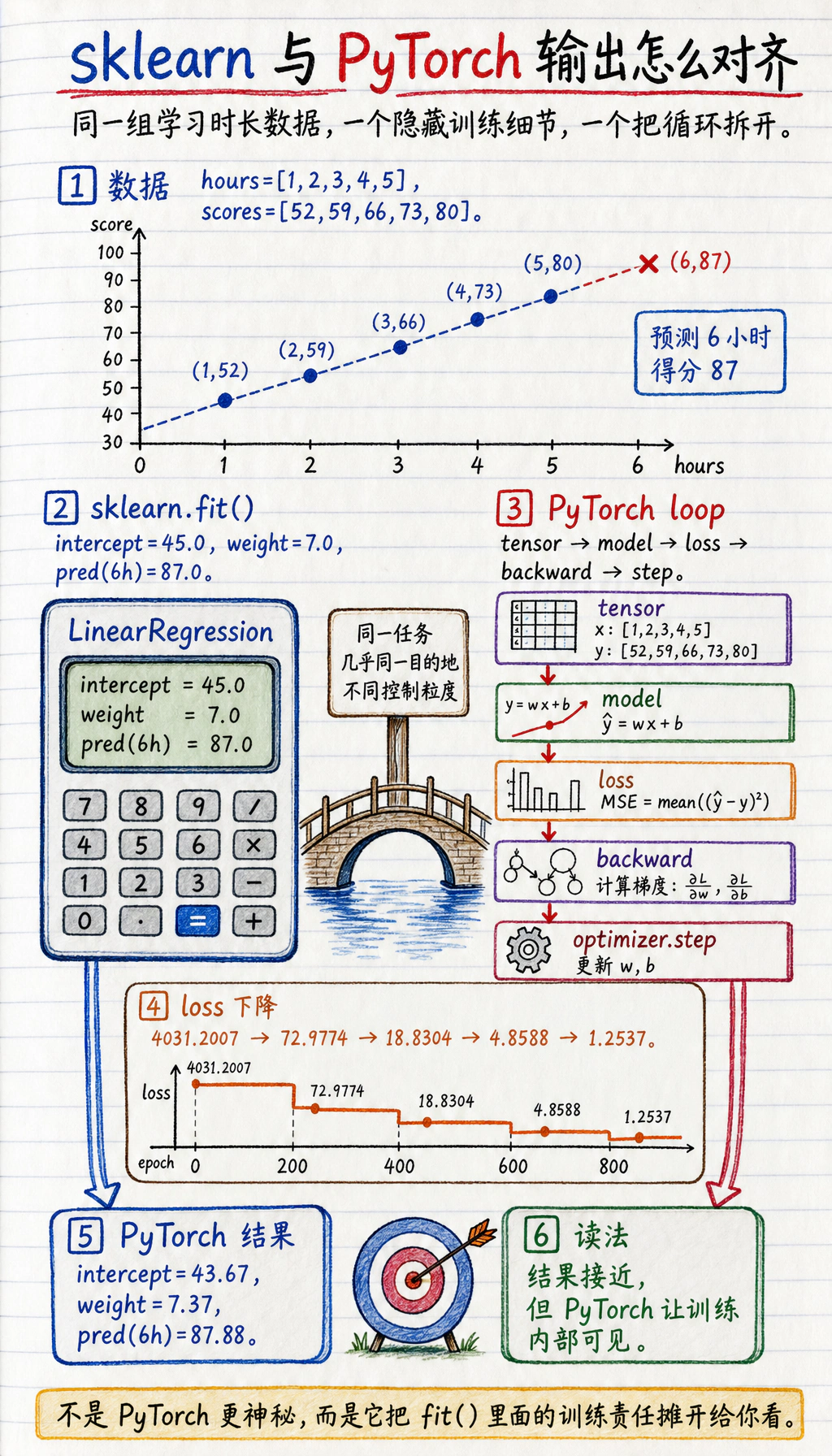
这张图要从上往下读:
sklearn在这个小数据集上直接拟合出精确直线,并预测87.0PyTorch从随机参数出发,通过训练循环不断降低 loss,最后靠近同一条线- 关键差异不是谁更高级,而是谁把训练过程摊开给你看、让你能控制
四、你真正新增学会了什么?
Section titled “四、你真正新增学会了什么?”上面的 PyTorch 代码虽然比 sklearn 长,但它暴露出了深度学习最核心的 5 个组件:
| 组件 | 类比 | 作用 |
|---|---|---|
| 数据 | 食材 | 模型要加工的输入 |
| 模型 | 厨师 | 决定怎么把输入变成输出 |
| 损失函数 | 评分表 | 判断模型做得好不好 |
| 优化器 | 调参师 | 根据误差去改参数 |
| 训练循环 | 每日复盘 | 重复试错直到效果变好 |
以后你学 CNN、Transformer、RAG 微调、本地模型训练,本质上都还是这五件事,只是模型结构变复杂了。
五、什么时候继续用 sklearn,什么时候切 PyTorch?
Section titled “五、什么时候继续用 sklearn,什么时候切 PyTorch?”更适合 sklearn 的情况
Section titled “更适合 sklearn 的情况”- 表格数据为主
- 模型是线性回归、逻辑回归、树模型、随机森林、XGBoost 一类
- 你更在意快速建模与调参
更适合 PyTorch 的情况
Section titled “更适合 PyTorch 的情况”- 图像、语音、文本等非结构化数据
- 需要自定义网络结构
- 需要 GPU 训练
- 需要微调预训练模型
- 需要自己控制训练细节
一句话记忆:
sklearn擅长“传统机器学习的高效应用”,PyTorch擅长“深度学习的灵活构建”。
六、常见误区
Section titled “六、常见误区”误区 1:PyTorch 只是另一个建模库
Section titled “误区 1:PyTorch 只是另一个建模库”不对。它更像是一个“深度学习搭建平台”。 你不只是调用模型,而是在搭建训练系统。
误区 2:PyTorch 比 sklearn 高级,所以以后都用它
Section titled “误区 2:PyTorch 比 sklearn 高级,所以以后都用它”也不对。工程上最重要的是选合适的工具。
很多表格任务里,sklearn 和树模型依然是首选。
误区 3:只要会写训练循环,就等于理解了深度学习
Section titled “误区 3:只要会写训练循环,就等于理解了深度学习”训练循环只是外壳。你还要继续理解:
- 张量和自动求导
nn.Module- 数据加载
- 模型调试
- 训练稳定性和评估方法
这些内容就是本章接下来几节要补上的。
七、本章之后你应该会的事
Section titled “七、本章之后你应该会的事”学完这一小节,你至少应该能回答下面三个问题:
sklearn.fit()到底替你藏了哪些步骤?- 为什么 PyTorch 训练一定绕不开损失函数和优化器?
- 为什么“模型 + 损失 + 优化器 + 训练循环”会成为后面所有深度学习课程的共同结构?
如果这三个问题你已经能说清楚,说明桥已经搭起来了。
保存一条左右对照笔记:
- sklearn 对比
- fit() 会隐藏参数更新
- PyTorch 对比
- 我编写模型、损失、反向传播、优化器步骤
- 相同目标
- 最小化误差,并在留出数据上验证
- 新责任
- 检查 shape、gradient、device 和 checkpoint
重点不是 PyTorch “更高级”,而是 PyTorch 把训练机制显式展开,让你能构建自定义深度学习系统。
- 把上面例子里的学习时长和分数改成你自己的数据,再分别用
sklearn和PyTorch训练一次。 - 把
PyTorch里的学习率从0.01改成0.1和0.001,观察损失下降速度变化。 - 试着打印每 100 轮的
weight和bias,看看参数是怎么逐步逼近答案的。
参考实现与讲解
- 如果数据接近线性,两个模型应该学到相近的直线。它们不一定完全一样,因为
sklearn通常直接优化回归目标,而 PyTorch 版本是通过梯度一步步移动参数。 0.1往往下降更快,但在小数据或尺度不好的数据上可能越过最优点。0.001通常更稳,但训练结束时 loss 可能还在慢慢下降。weight和bias应该逐步移动到让预测更接近分数的位置。如果参数几乎不动而 loss 仍然很高,要检查 learning rate、tensor shape,以及梯度是否真的被应用。