6.7.2 超参数调优策略
- 按稳定顺序调参,而不是一次改一堆。
- 在 PyTorch 中跑一个小型 learning-rate sweep。
- 同时阅读 validation loss、validation accuracy 和训练稳定性。
- 用可复用表格记录实验证据。
- 判断什么时候该调 learning rate、batch size、正则或 early stopping。
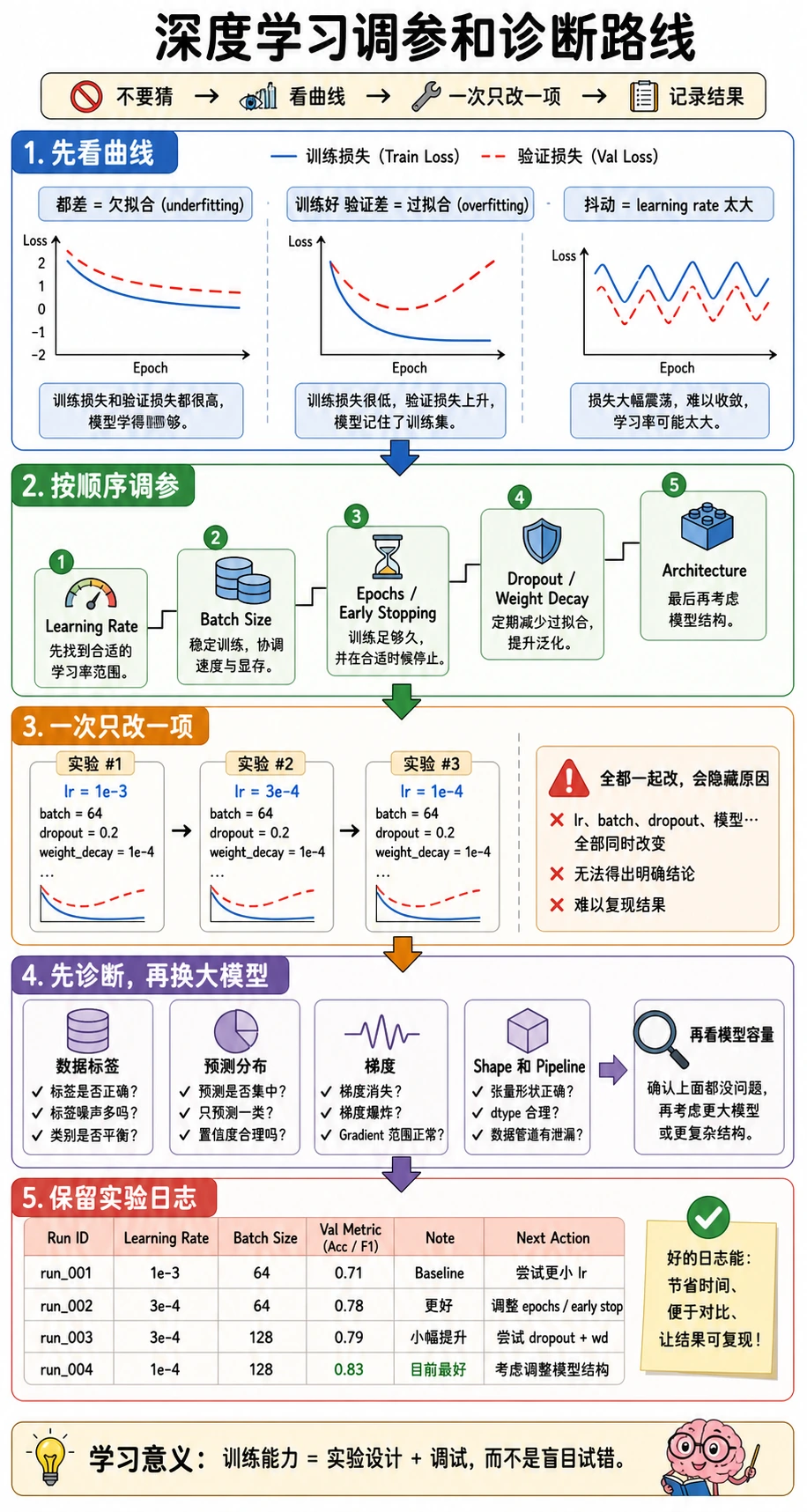
实操顺序:
先让训练跑起来调 learning rate看验证集控制过拟合局部细调
不要一开始就调所有旋钮。一次有用的调参实验,应该回答一个问题。
| 问题 | 优先尝试的参数 | 观察什么 |
|---|---|---|
| 模型到底能不能学? | learning rate | train loss 趋势 |
| 训练是否不稳定? | learning rate、gradient clipping、batch size | spike 或发散 |
| validation 比 training 差很多? | weight decay、dropout、augmentation、early stopping | generalization gap |
| 训练太慢? | batch size、模型大小、precision | 时间和显存 |
| 部署太重? | 架构、pruning、quantization | latency 和 size |
实验:跑一个 Learning-Rate Sweep
Section titled “实验:跑一个 Learning-Rate Sweep”这个 toy classification 很小,运行快,但能展示完整流程。
创建 lr_sweep.py:
import torchfrom torch import nn
torch.manual_seed(11)
X = torch.randn(240, 2)y = ((X[:, 0] * 0.8 + X[:, 1] * -0.5) > 0).long()
train_x, val_x = X[:180], X[180:]train_y, val_y = y[:180], y[180:]
def run(lr): torch.manual_seed(123) model = nn.Sequential(nn.Linear(2, 8), nn.ReLU(), nn.Linear(8, 2)) opt = torch.optim.SGD(model.parameters(), lr=lr) loss_fn = nn.CrossEntropyLoss()
for _ in range(40): logits = model(train_x) loss = loss_fn(logits, train_y) opt.zero_grad() loss.backward() opt.step()
with torch.no_grad(): train_loss = loss_fn(model(train_x), train_y).item() val_logits = model(val_x) val_loss = loss_fn(val_logits, val_y).item() val_acc = (val_logits.argmax(dim=1) == val_y).float().mean().item()
return train_loss, val_loss, val_acc
results = []for lr in [1e-3, 1e-2, 1e-1, 1.0, 10.0]: train_loss, val_loss, val_acc = run(lr) results.append((lr, train_loss, val_loss, val_acc))
print("lr_sweep")for lr, train_loss, val_loss, val_acc in results: print( f"lr={lr:g} " f"train_loss={train_loss:.3f} " f"val_loss={val_loss:.3f} " f"val_acc={val_acc:.3f}" )
best = min(results, key=lambda row: row[2])print("best_lr:", best[0])运行:
python lr_sweep.py预期输出:
lr_sweeplr=0.001 train_loss=0.763 val_loss=0.733 val_acc=0.450lr=0.01 train_loss=0.675 val_loss=0.663 val_acc=0.533lr=0.1 train_loss=0.340 val_loss=0.373 val_acc=0.967lr=1 train_loss=0.053 val_loss=0.072 val_acc=0.983lr=10 train_loss=0.280 val_loss=0.291 val_acc=0.883best_lr: 1.0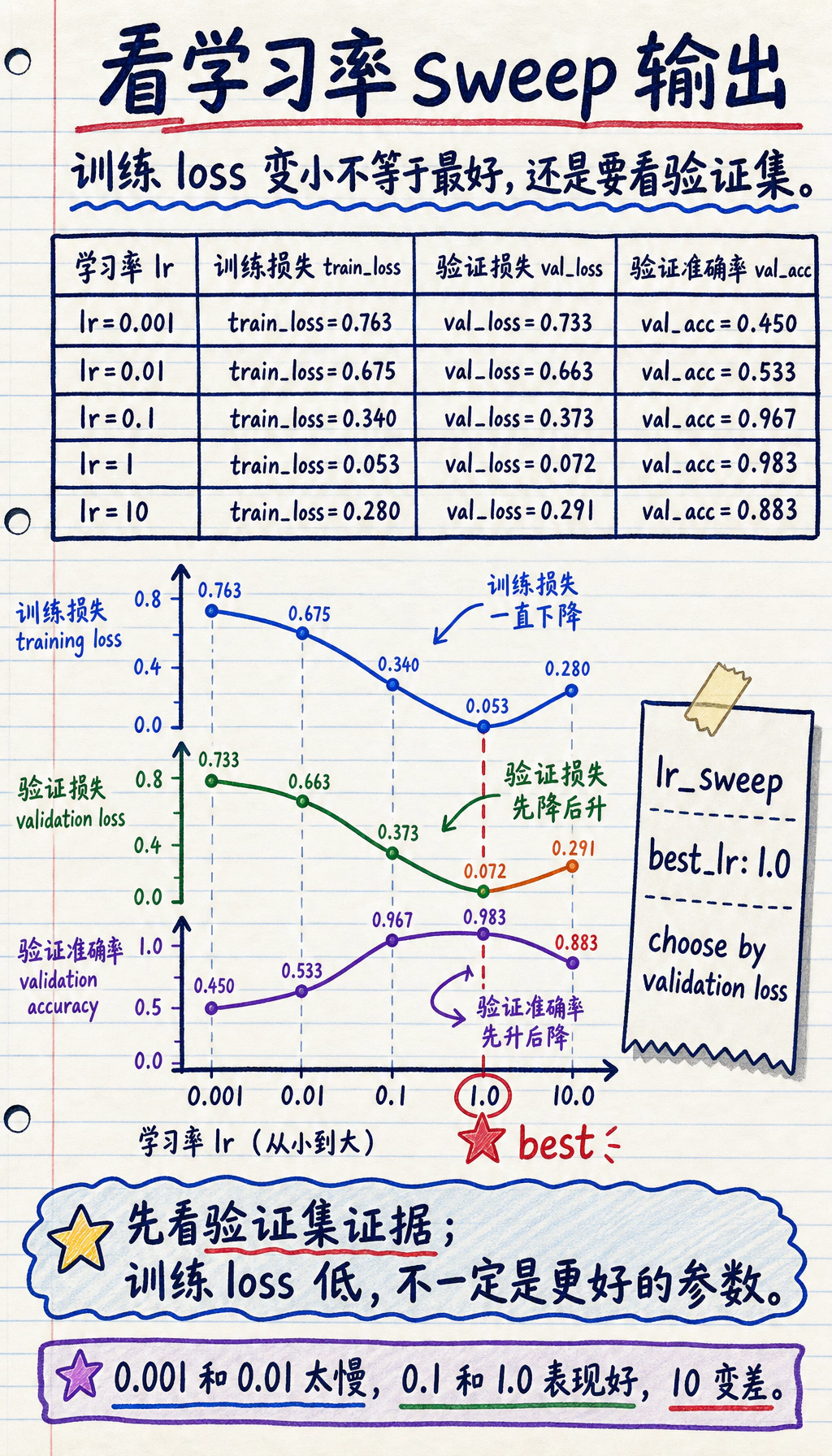
仔细读:
0.001和0.01对这个预算太慢;0.1和1.0学得不错;10.0虽然还能训练,但变差了,所以不是越大越好;- 这里按 validation loss 选,而不是按 training loss 选。
下一步调什么
Section titled “下一步调什么”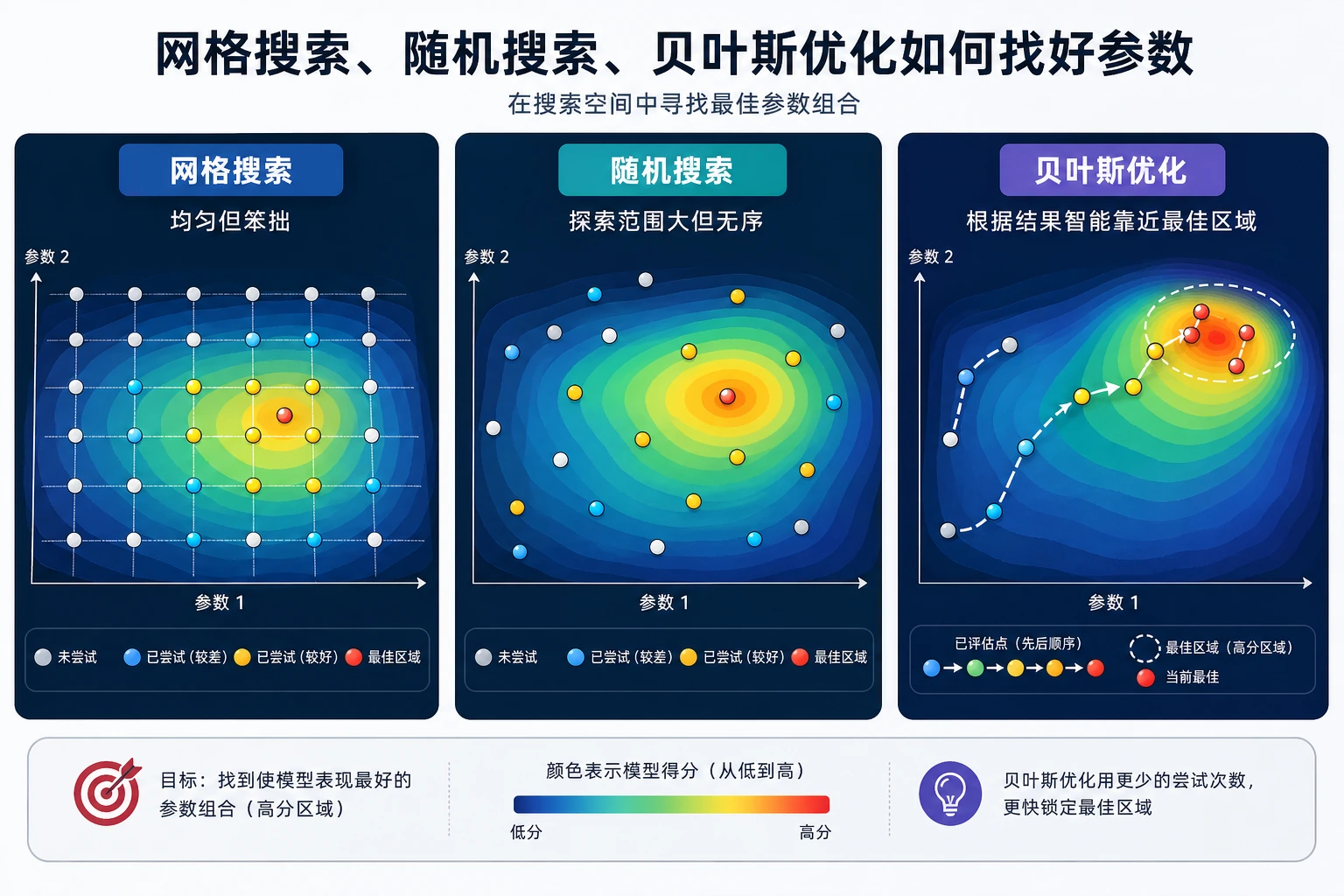
找到合理 learning rate 后,按这个顺序继续:
- Batch size:影响显存、速度和梯度噪声。
- Epochs 与 early stopping:验证集不再提升时停止。
- Weight decay 与 dropout:控制过拟合。
- 架构大小:训练循环稳定后再改容量。
- Optimizer 细节:必要时再调 betas、scheduler、warmup 或 momentum。
规则:
先做全局粗搜,再做局部细调最小实验日志
Section titled “最小实验日志”小项目也要记录日志。
| 分组 | 需要记录的字段 |
|---|---|
| 身份信息 | experiment_id、code_version、data_version、seed |
| 超参数 | lr、batch_size、optimizer、weight_decay、dropout、epochs |
| 结果 | best_val_metric、train_time、decision |
示例结论:
lr=1.0 在 quick sweep 中验证集 loss 最好。下一步:固定 lr=1.0,比较 batch_size=32 和 64。保留一张调参决策卡:
- 问题
- 测试的是哪个单一变量?
- 已固定
- 数据划分、随机种子、模型、优化器家族、训练预算
- 已更改
- 学习率数值
- 选择指标
- 验证损失或验证准确率
- 最佳设置
- 快速搜索中 lr=1.0
- 下一次实验
- 只做一个本地改进,不要同时调很多参数
| 现象 | 可能原因 | 下一组实验 |
|---|---|---|
| train loss 不动 | LR 太低、模型太小、标签有问题 | 提高 LR,检查数据,试大模型 |
| train loss 发散 | LR 太高、梯度不稳定 | 降低 LR,加 gradient clipping |
| train 好,validation 差 | 过拟合或泄漏 | 加正则,检查划分 |
| validation 先变好再变坏 | 最佳 epoch 后过拟合 | early stopping |
| 换 seed 后差很多 | 训练不稳定或数据太少 | 跑 3 个 seed,报 mean/std |
| 错误 | 修复 |
|---|---|
| 同时改 LR、batch size、optimizer 和模型 | 每次实验只改一个主变量 |
| 按 training metric 选模型 | 用 validation metric 选 |
| 忽略运行时间 | 同时记录时间和显存 |
| 相信单个幸运 seed | 重要实验跑多个 seed |
| 数据还没清理就调参 | 先检查标签、泄漏和预处理 |
- 把
lr=0.3和lr=3.0加入 sweep。哪个更接近最好区域? - 把训练预算从
40step 改成10step。最佳 LR 会变化吗? - 每个 LR 跑两个 seed,并增加
seed列。 - 为 LR sweep 写一句下一步实验决策。
- 解释为什么每个实验只回答一个问题会让调参更简单。
参考实现与讲解
- 通常
lr=0.3更可能接近可用区域,lr=3.0更容易发散或震荡;最终以验证曲线为准。 - 预算变短时,较大学习率可能看起来更好,因为它下降更快;长预算下稳定性更重要。
- 增加 seed 后要比较均值和波动,避免被一次好运或坏运误导。
- 下一步决策应具体,例如“在
0.03到0.3之间做更细搜索,并保留两个 seed”。 - 单变量实验能把结果变化归因到一个因素,调参记录更清楚,也更容易复现。
- 调参是受控实验设计,不是猜。
- Learning rate 通常是第一个要测的旋钮。
- 决策应该由验证集证据驱动。
- 日志让实验可复现、可解释。
- 先粗调全局设置,再局部细调。