7.5.3 高级 Prompt 技巧
- 理解 few-shot、角色设定、分步约束这些技巧分别在解决什么问题
- 学会判断什么时候值得加技巧,什么时候反而会把 Prompt 写乱
- 建立 Prompt 调优要靠实验而不是靠感觉的意识
- 看懂几类常见高级技巧的真实作用边界
先建立一张地图
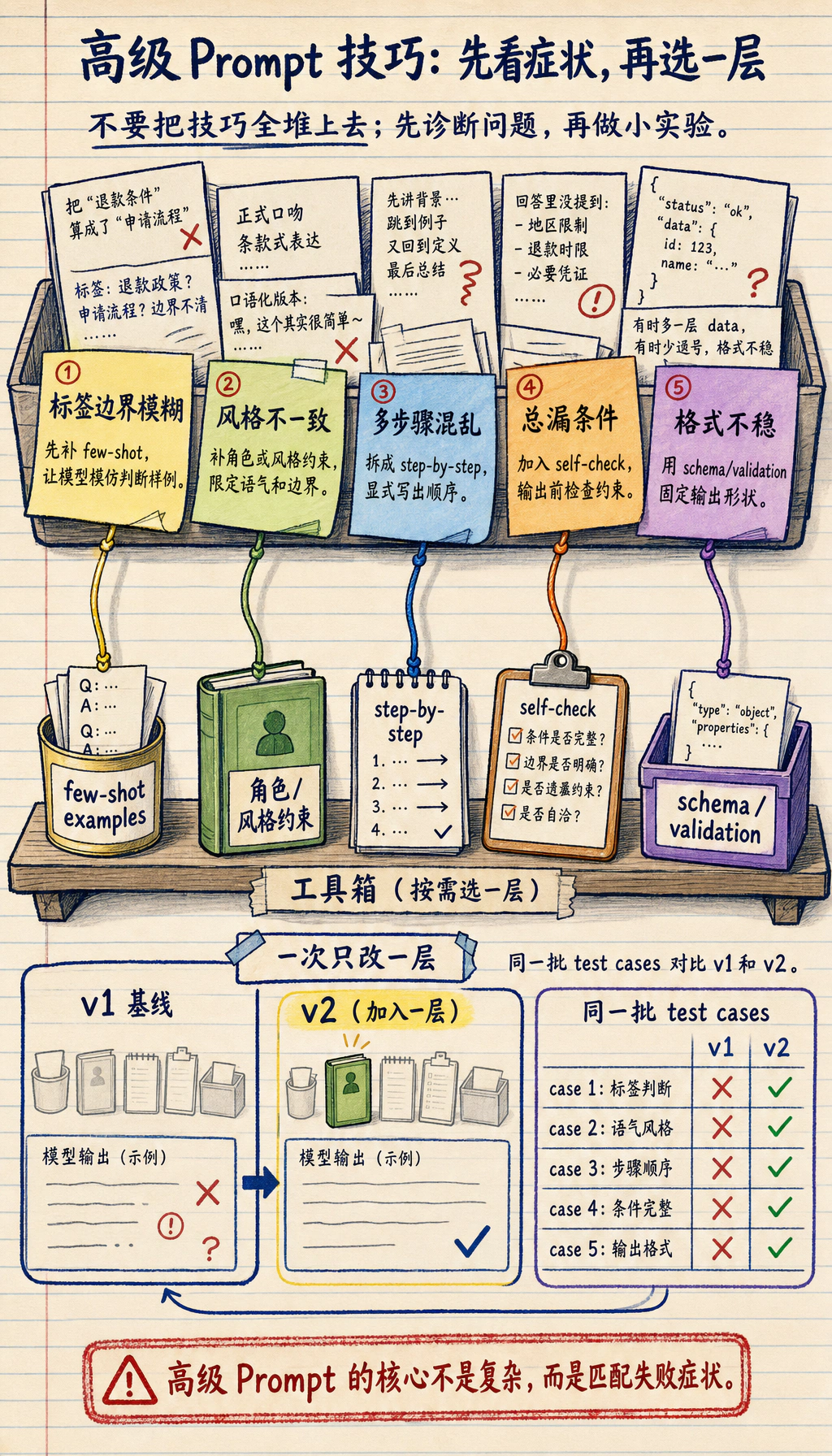
Section titled “先建立一张地图”高级 Prompt 技巧最适合新人的理解方式不是“看到什么招都往上堆”,而是先看清:
flowchart LR A["基础 Prompt 还不够稳"] --> B["Few-shot"] A --> C["角色设定"] A --> D["分步约束"] A --> E["自检"]这节真正想解决的是:
- 哪些技巧分别在补哪类问题
- 什么时候该加,什么时候反而会让 Prompt 变乱
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把高级 Prompt 技巧理解成:
- 给任务说明书继续加护栏和示范
基础 Prompt 像是:
- 把任务说清楚
高级 Prompt 更像是:
- 再补几个例子
- 再说明输出长什么样
- 再提醒模型先检查有没有漏条件
所以“高级”不代表更玄,而是:
- 更适合处理更容易跑偏的任务
一、为什么会需要“高级” Prompt?
Section titled “一、为什么会需要“高级” Prompt?”因为有些任务仅靠一句简单指令不够稳。
例如:
- 标签边界模糊
- 输出格式要求严格
- 任务有多阶段逻辑
- 模型容易漏条件
这时就需要更细的引导。
但最重要的原则仍然是:
不是技巧越多越好,而是越匹配任务越好。
二、Few-shot:为什么“给例子”这么有用?
Section titled “二、Few-shot:为什么“给例子”这么有用?”它最适合哪些问题?
Section titled “它最适合哪些问题?”当任务很难只靠一句定义讲清楚时,few-shot 特别有价值。
例如:
factvsopinion- 信息抽取字段样式
- 某种固定回复风格
一个最小 few-shot 示例
Section titled “一个最小 few-shot 示例”few_shot_examples = [ {"input": "北京是中国的首都。", "output": "fact"}, {"input": "这门课非常有趣。", "output": "opinion"}]
for ex in few_shot_examples: print(ex)预期输出:
{'input': '北京是中国的首都。', 'output': 'fact'}{'input': '这门课非常有趣。', 'output': 'opinion'}它真正的作用是什么?
Section titled “它真正的作用是什么?”不是“多写几行字”,而是:
把抽象规则变成可以模仿的示范。
这在很多边界模糊任务里比单纯定义更稳。
一个很适合初学者先记的判断表
Section titled “一个很适合初学者先记的判断表”| 任务现象 | 更值得优先试哪种技巧 |
|---|---|
| 标签边界很模糊 | few-shot |
| 输出风格总不一致 | 角色设定或风格约束 |
| 任务有明显多步骤 | 分步约束 |
| 总漏条件或格式出错 | 自检 |
这个表很适合新人,因为它会把“技巧列表”重新变成:
- 出现什么问题时,我先补哪一层
四个容易混淆的术语
Section titled “四个容易混淆的术语”| 术语 | 含义 | 什么时候用 |
|---|---|---|
| 零样本(Zero-shot) | 不给例子,直接给任务 | 任务简单、标签边界清楚时先用它 |
| 少样本(Few-shot) | 在真实任务前给几个输入输出示例 | 定义不够清楚、模型需要模仿样例时使用 |
| 角色提示 | 让模型以某种角色或风格工作 | 用来控制语气、视角或专业边界,不能替代任务说明 |
| 自检 | 最终输出前让模型检查约束是否满足 | 字段遗漏、格式错误、无来源事实经常出现时使用 |
三、角色设定什么时候有帮助?
Section titled “三、角色设定什么时候有帮助?”很多 Prompt 会写:
- 你是一个资深技术导师
- 你是一个法律助手
- 你是一个代码 审核者
它什么时候真的能带来收益?
Section titled “它什么时候真的能带来收益?”当你希望模型:
- 采用某种风格
- 进入某种工作模式
- 维持某种角色边界
时,角色设定会很有帮助。
但角色设定不是魔法
Section titled “但角色设定不是魔法”如果任务本身不清楚,只写一句:
- 你是世界顶级专家
通常不会自动让结果变稳。
所以一个很重要的判断是:
角色设定是辅助层,不是替代任务定义层。
一个最小“角色不会替代任务定义”的对比例子
Section titled “一个最小“角色不会替代任务定义”的对比例子”bad_prompt = "你是世界顶级专家,请帮我处理一下这段内容。"better_prompt = "你是一位课程助教。请把下面文本总结成 3 条中文要点,每条不超过 20 个字。"
print("bad_prompt =", bad_prompt)print("better_prompt=", better_prompt)预期输出:
bad_prompt = 你是世界顶级专家,请帮我处理一下这段内容。better_prompt= 你是一位课程助教。请把下面文本总结成 3 条中文要点,每条不超过 20 个字。这个例子很适合初学者,因为它会提醒你:
- 角色设定不是魔法增益
- 真正稳不稳,还是看任务规格有没有说清楚
四、分步约束为什么经常更稳?
Section titled “四、分步约束为什么经常更稳?”因为很多任务天然有多阶段
Section titled “因为很多任务天然有多阶段”例如:
- 先找事实
- 再做判断
- 最后结构化输出
如果你把这几步全揉成一句话,模型更容易乱。
请按以下步骤完成任务:1. 先找出文本里的关键事实2. 再判断其情感倾向3. 最后输出 JSON这种写法的核心价值在于:
把任务内部结构显式写出来。
五、自检(self-check)为什么会出现?
Section titled “五、自检(self-check)为什么会出现?”什么时候它特别有意义?
Section titled “什么时候它特别有意义?”当你最担心模型:
- 漏掉条件
- 格式出错
- 输出和约束不一致
时,可以让它在输出前再做一层自检。
一个最小示意
Section titled “一个最小示意”在输出最终答案前,请检查:1. 是否遗漏了关键信息2. 是否满足输出格式要求3. 是否包含了原文中不存在的事实这类技巧的边界
Section titled “这类技巧的边界”它可能有帮助,但不是万能药。 它更适合:
- 格式敏感
- 漏信息敏感
的场景。
六、为什么高级技巧不能乱叠?
Section titled “六、为什么高级技巧不能乱叠?”因为每多加一层技巧,也在增加:
- Prompt 长度
- 复杂度
- 调试难度
所以更成熟的做法通常不是:
- 什么都加
而是:
- 先明确问题,再加最需要的那一层
这是一个非常重要的 Prompt 工程习惯。
再看一个最小“逐层加技巧”的实验表
Section titled “再看一个最小“逐层加技巧”的实验表”| 版本 | 改了什么 | 你最该观察什么 |
|---|---|---|
| v1 | 只有任务目标 | 输出是否跑偏 |
| v2 | + 输出格式 | 格式是否更稳 |
| v3 | + few-shot | 边界任务是否更稳 |
| v4 | + 自检 | 是否更少漏条件 |
这个表很适合新人,因为它能把 Prompt 调优重新变成:
- 一个能做对照实验的过程
七、一个更稳的 Prompt 调优顺序
Section titled “七、一个更稳的 Prompt 调优顺序”比起“看到一个技巧就往上堆”,更推荐:
- 先把任务目标写清楚
- 再把输出格式写清楚
- 如果还不稳,再补示例
- 如果还是不稳,再加分步约束或自检
这样你更容易判断:
- 哪一层改动真的带来了收益
第一次做 Prompt 调优时最稳的策略
Section titled “第一次做 Prompt 调优时最稳的策略”建议你每次只新增一层技巧,例如:
- 先改输出格式
- 再补 1~2 个 few-shot
- 再考虑加分步约束
不要一次把角色、示例、自检、格式全叠上去,否则很难知道到底哪一层在起作用。
八、最常见的误区
Section titled “八、最常见的误区”觉得 Prompt 越长越高级
Section titled “觉得 Prompt 越长越高级”长但乱的 Prompt 往往更糟。
什么技巧都叠进去
Section titled “什么技巧都叠进去”这会让你很难知道究竟哪一层在起作用。
只凭感觉调,不做小实验
Section titled “只凭感觉调,不做小实验”九、核心提醒
Section titled “九、核心提醒”- 高级 Prompt 不是“更花”,而是“更贴问题”
- few-shot、角色设定、分步约束和自检各有边界
- 最稳的调优方式仍然是逐层实验,而不是一次乱叠
Prompt 调优本质上也应该是实验过程。
如果把它做成笔记或项目,最值得展示什么
Section titled “如果把它做成笔记或项目,最值得展示什么”最值得展示的通常不是:
- 一长串看起来很复杂的 Prompt
而是:
- 原始 Prompt
- 你新增了哪一层技巧
- 输出因此稳定了什么
- 哪些技巧其实没有明显帮助
这样别人会更容易看出:
- 你理解的是 Prompt 调优方法
- 不只是会堆技巧名词
学完这一页,至少保留这张证据卡:
- 技术
- few-shot、角色、步骤约束、自检或分解
- 固定案例
- 改动前后使用相同测试输入
- 改进
- 分数提升或失败减少
- 风险
- 提示过长、相互冲突,或过拟合
- 决策
- 只保留能改善证据的技术
这一节最重要的不是背几个技巧名字,而是理解:
高级 Prompt 技巧真正有价值的地方,在于它们能帮助你把任务定义、示范、约束和校验做得更稳定。
而不是让 Prompt “看起来更高级”。
- 为一个情感分类任务写出一个包含 few-shot 的 Prompt。
- 想一想:角色设定和任务目标哪一个更基础?为什么?
- 用自己的话解释:为什么“分步约束”常常比一句模糊大指令更稳?
- 为什么说高级 Prompt 技巧真正重要的不是复杂,而是适配?
参考实现与讲解
- 一个好的 few-shot prompt 应该定义标签集合,给出至少两个已标注示例,然后要求模型用同样格式分类新输入。
- 任务目标更基础。角色设定可以改变语气或视角,但不能替代清楚的目标、输出契约和约束。
- 分步约束把一个模糊大请求拆成可检查的子决策,降低歧义,也更容易定位失败点。
- 高级技巧只有匹配失败模式时才有价值。角色、示例、推理指令并非越多越好,而是要让任务更可靠。