8.0 学习检查表:LLM 应用开发与 RAG
这页当成可打印检查表使用。需要完整讲解时,回到 第 8 章入口页。
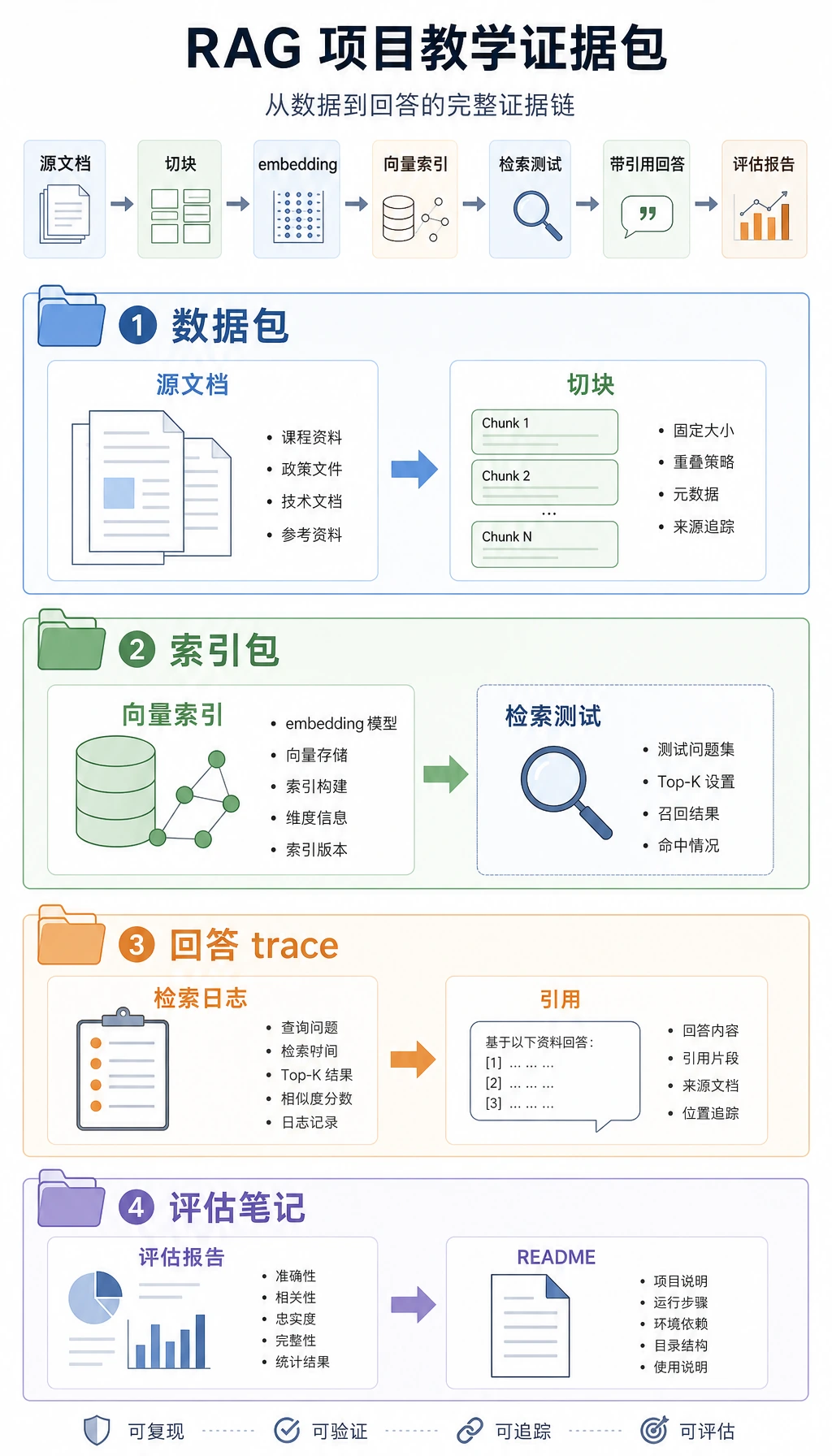
两小时快速通读
Section titled “两小时快速通读”| 时间 | 做什么 | 能说出这句话就停 |
|---|---|---|
| 20 分钟 | 看入口页的 RAG 应用闭环 | “RAG 答案应该绑定检索证据。” |
| 25 分钟 | 运行 Tiny RAG 脚本 | “信任答案前,我能先检查 top-k 片段。” |
| 25 分钟 | 浏览 8.1 RAG 基础和文档处理 | “chunk 大小、重叠和 metadata 会影响检索与引用。” |
| 25 分钟 | 浏览 8.3 API 实践和工具/函数调用 | “LLM 应用需要请求、响应、错误和重试路径。” |
| 25 分钟 | 阅读调试阶梯 | “我能区分文档、检索、生成、引用和运维失败。” |
必须留下的证据
Section titled “必须留下的证据”| 证据 | 最小版本 |
|---|---|
chunks.jsonl | 5~10 个 chunk,包含 id、source、text、version |
retrieval_logs.jsonl | 每个测试问题的 查询、top-k chunk ID、score、source |
eval_questions.csv | 至少 10 个固定问题,带期望来源或答案要点 |
failure_cases.md | 至少三个失败样本,标注 document、chunking、retrieval、generation、citation 或 deploy |
rag_config.md | chunk 大小、overlap、top-k、是否 rerank、Prompt 版本 |
context_strategy.md | long context、RAG、memory 或 hybrid 决策,并说明一个未选方案 |
rag_app_workshop_output.txt | 8.5.6 实操:第 8 章 RAG 应用完整工作坊 的输出 |
README.md | 运行命令、示例问题、带引用答案、评估结果、下一步修复 |
| 闸门 | 通过条件 |
|---|---|
| 引用 | 每个事实性答案都引用 chunk、source 和 version。 |
| 空检索 | 没有证据时,系统会拒绝回答。 |
| 回归评估 | 每次修改 chunking、retrieval、reranking 或 Prompt 前后,都跑同一批问题。 |
| 运维记录 | 日志包含 查询、top-k、Prompt 版本、延迟、token cost 和失败标签。 |
预期结果:你的第 8 章项目文件夹里有 chunks、检索日志、固定评测问题、带引用答案、失败标签、应用日志,以及说明下一步检索或生成修复的 README。
- 你能解释 RAG 和“写更长 Prompt”有什么不同吗?
- 你能展示一个问题检索到了哪些文档片段吗?
- 你能说明 chunk metadata 为什么对引用和排障必不可少吗?
- 检索为空时,你能返回“资料不足”,而不是让模型猜吗?
- 你能用同一组评估问题比较两个 RAG 版本吗?
- 你能说明什么时候长上下文比 RAG 更简单,什么时候仍然必须使用 RAG 或记忆吗?
检查思路与讲解
- RAG 的不同之处在于它会先检索证据再回答。更长的 Prompt 仍然主要依赖模型已有记忆或猜测,而 RAG 可以把新鲜、私有或来自文档的事实拉进答案。
- 要把查询、top-k chunks、分数、source 和 version 都展示出来,这样别人才能检查检索路径。
- metadata 会把 source、version 和位置一起保留下来,所以才能做引用、排障和回归分析。
- 检索为空时,最稳妥的回答是“无法回答”或“需要更多信息”,而不是猜一个答案。
- 在检索、分块或 reranking 调整前后,都用同一组评估问题比较,这样结果才公平。
如果答案都是可以,就进入第 9 章。第 9 章会把系统从“生成答案”升级成能规划、调用工具、从失败中恢复的 Agent。
学完这一页,至少保留这张证据卡:
- RAG 评估集
- 带有期望证据的固定问题
- 检索轨迹
- 查询、分块、分数、选中的证据
- 答案追踪
- 引用的答案和未支持主张检查
- 应用追踪
- 请求、响应、验证、日志
- 项目说明
- 运行命令、指标、失败、下一步动作