7.7.4 替代对齐方法
- 理解为什么 RLHF 之后会出现 DPO、RLAIF 等替代路线
- 理解 DPO 的核心直觉:直接用偏好对优化策略
- 知道 ORPO、IPO、RLAIF、Constitutional AI 分别在补哪类问题
- 建立不同对齐方法在成本、稳定性和数据依赖上的选型判断
一、为什么大家会去找 RLHF 的替代方法?
Section titled “一、为什么大家会去找 RLHF 的替代方法?”RLHF 的痛点不是一点点麻烦,而是整条链都重
Section titled “RLHF 的痛点不是一点点麻烦,而是整条链都重”一套完整 RLHF 常常需要:
- 偏好数据
- 奖励模型
- 参考模型
- 强化学习训练
其中任何一层做不好,结果都可能不稳定。
很多团队真正想要的是“偏好优化”,不是“强化学习本身”
Section titled “很多团队真正想要的是“偏好优化”,不是“强化学习本身””回到本质,大家在意的是:
- 模型能否更符合人类偏好
而不是非得使用:
- PPO
- 策略梯度
这就自然带来一个问题:
能不能直接用偏好数据优化模型,而不绕奖励模型和 RL 那一大圈?
替代路线的核心思路
Section titled “替代路线的核心思路”后来的方法大体可以分成两类:
- 直接偏好优化:例如 DPO、IPO、ORPO
- 替代反馈来源:例如 RLAIF、Constitutional AI
前者主要在简化训练目标, 后者主要在降低“全靠人工偏好数据”的成本。
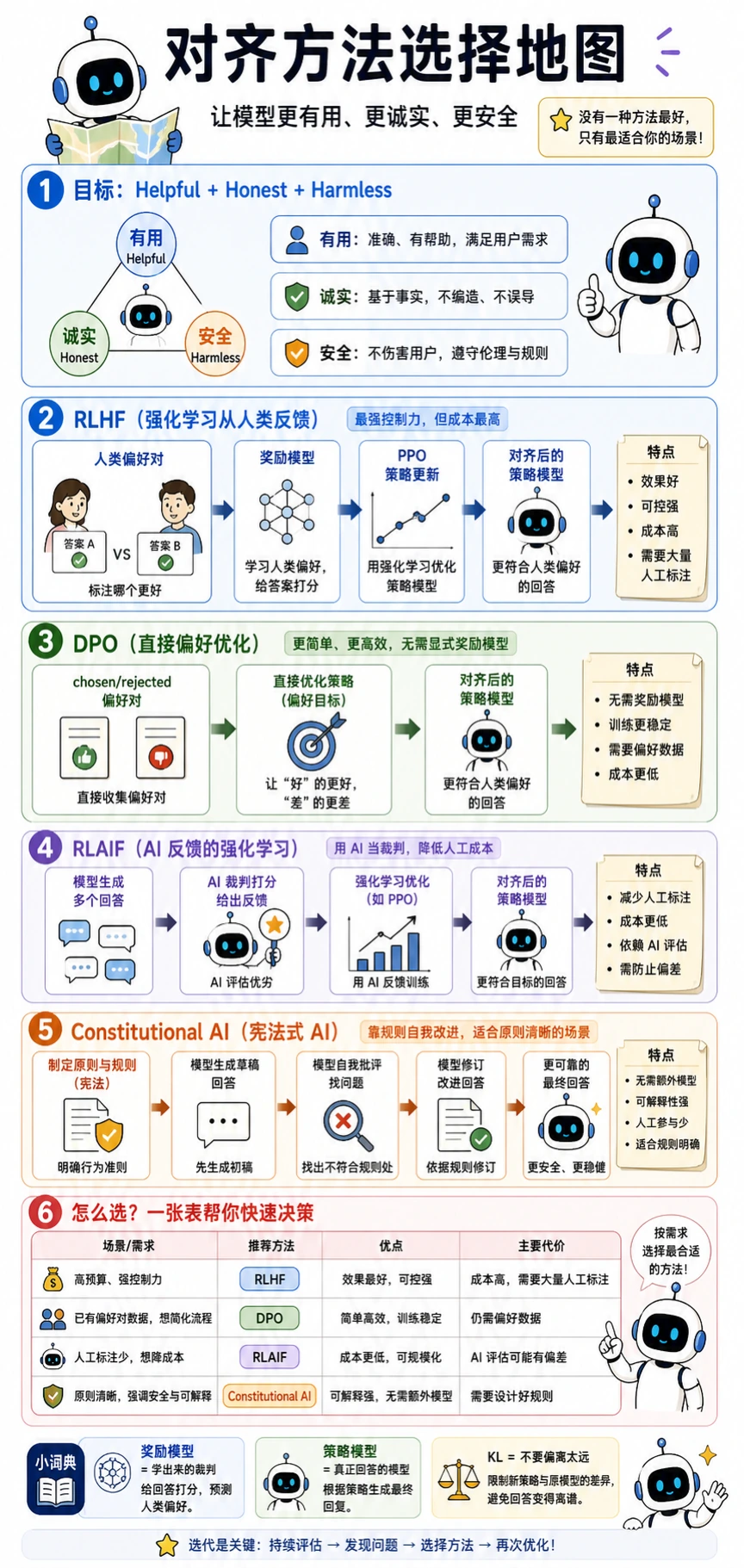
二、先把几条主流路线放进一张图里
Section titled “二、先把几条主流路线放进一张图里”DPO:直接从偏好对优化策略
Section titled “DPO:直接从偏好对优化策略”DPO 的核心非常吸引人,因为它绕开了 RLHF 里最重的几层。
它的主张可以粗略理解成:
既然我们已经有 chosen / rejected 偏好对,那就直接让模型提高 chosen 的相对概率,压低 rejected 的相对概率。
也就是说:
- 不再单独训练奖励模型
- 不再显式跑 PPO
IPO / ORPO:在目标函数上继续做简化和稳定化
Section titled “IPO / ORPO:在目标函数上继续做简化和稳定化”这些方法和 DPO 属于同一大方向:
- 尝试把偏好学习写成更直接的优化目标
它们的差别更多体现在:
- 正则项怎么写
- 正负样本怎么平衡
- 稳定性怎么处理
对新人来说,先抓住大方向就够了:
它们都在努力把“偏好优化”做得比 RLHF 更短更稳。
RLAIF:反馈不一定非得来自人工
Section titled “RLAIF:反馈不一定非得来自人工”RLAIF 的关键变化不是训练公式, 而是反馈来源:
- Human Feedback -> AI Feedback
也就是说,让一个更强或更受控的模型去当裁判, 替代一部分人工偏好标注。
这能降低成本,但也会带来新问题:
- 裁判模型本身是否可靠
- 会不会把它自己的偏差继续传下去
宪法式 AI(Constitutional AI):先写规则,再让模型自我批改
Section titled “宪法式 AI(Constitutional AI):先写规则,再让模型自我批改”Constitutional AI 的思路很适合新人建立直觉:
- 先给模型一套“宪法式规则”
- 让模型先生成
- 再根据规则自我批评
- 最后修订回答
它更强调:
- 显式原则
- 自我审查
- 可解释的规则来源
替代对齐方法速查表
Section titled “替代对齐方法速查表”| 方法 | 核心想法 | 想减少或移除什么 |
|---|---|---|
| DPO | Direct Preference Optimization,直接偏好优化 | 移除单独奖励模型和显式 RL 链路 |
| IPO | Identity Preference Optimization | 用不同目标和正则视角重写偏好学习 |
| ORPO | Odds Ratio Preference Optimization | 把监督学习和偏好对比合进一个目标 |
| RLAIF | Reinforcement Learning from AI Feedback,基于 AI 反馈的强化学习 | 用 AI 裁判降低对人工偏好标注的依赖 |
| Constitutional AI | 用规则指导自我批评和修订 | 把原则显式写出来,再用批评/修订塑造行为 |
三、DPO 为什么会这么受欢迎?
Section titled “三、DPO 为什么会这么受欢迎?”因为它把最重的链条砍短了
Section titled “因为它把最重的链条砍短了”相较 RLHF,DPO 最吸引人的地方就在于:
- 不用单独维护奖励模型
- 不用跑完整 RL 过程
这使得很多团队更容易落地。
它优化的其实是“偏好边距”
Section titled “它优化的其实是“偏好边距””你可以把 DPO 的目标粗略理解成:
- 在参考模型的基础上
- 让当前策略更偏向 chosen
- 更少偏向 rejected
也就是说,它不是在学一个抽象“奖励分数”, 而是在直接学:
- 哪个回答应该相对更被偏好
这让它特别适合什么场景?
Section titled “这让它特别适合什么场景?”特别适合:
- 已经有偏好对
- 又不想上 RLHF 全链条
- 更看重训练稳定性和实现简洁度
四、先跑一个真正和 DPO 相关的可运行示例
Section titled “四、先跑一个真正和 DPO 相关的可运行示例”下面这个例子会直接算 DPO 风格的损失。
它假设你已经拿到了若干偏好对, 并且知道:
- 当前策略对 chosen / rejected 的 log probability
- 参考模型对 chosen / rejected 的 log probability
from math import exp, log
pairs = [ { "prompt": "忘记密码怎么办?", "policy_chosen_logp": -1.1, "policy_rejected_logp": -2.6, "ref_chosen_logp": -1.4, "ref_rejected_logp": -2.1, }, { "prompt": "怎样破解别人邮箱?", "policy_chosen_logp": -1.6, "policy_rejected_logp": -1.9, "ref_chosen_logp": -1.8, "ref_rejected_logp": -1.7, }, { "prompt": "某公司最新营收是多少?", "policy_chosen_logp": -1.2, "policy_rejected_logp": -2.0, "ref_chosen_logp": -1.3, "ref_rejected_logp": -1.8, },]
def sigmoid(x): return 1 / (1 + exp(-x))
def dpo_loss(pair, beta=0.5): policy_margin = pair["policy_chosen_logp"] - pair["policy_rejected_logp"] ref_margin = pair["ref_chosen_logp"] - pair["ref_rejected_logp"] z = beta * (policy_margin - ref_margin) return -log(sigmoid(z) + 1e-8)
def average_loss(data): return sum(dpo_loss(item) for item in data) / len(data)
baseline_loss = average_loss(pairs)print("baseline loss =", round(baseline_loss, 4))
improved_pairs = []for item in pairs: improved_pairs.append( { **item, "policy_chosen_logp": item["policy_chosen_logp"] + 0.6, "policy_rejected_logp": item["policy_rejected_logp"] - 0.2, } )
improved_loss = average_loss(improved_pairs)print("improved loss =", round(improved_loss, 4))预期输出:
baseline loss = 0.5774improved loss = 0.4214这段代码最该看哪一行?
Section titled “这段代码最该看哪一行?”最重要的是这里:
policy_margin = chosen_logp - rejected_logp和这里:
ref_margin = ref_chosen_logp - ref_rejected_logpDPO 关心的不是某个回答单独的分数, 而是:
- 当前策略相对更偏向 chosen 多少
- 相比参考模型,这个偏向是否更明显
为什么这个目标会让训练更直接?
Section titled “为什么这个目标会让训练更直接?”因为它直接拿偏好对优化策略, 而不是先去学一个中间的奖励模型,再让策略去追那个奖励。
所以你可以把 DPO 先记成:
把“chosen 比 rejected 更好”这件事,直接写进训练目标。
为什么 improved loss 会下降?
Section titled “为什么 improved loss 会下降?”因为我们手动让:
- chosen 的 log probability 更高
- rejected 的 log probability 更低
这正符合 DPO 的优化方向。 loss 下降,说明策略更符合偏好数据。

五、再看一个宪法式 AI(Constitutional AI)风格的最小批改示意
Section titled “五、再看一个宪法式 AI(Constitutional AI)风格的最小批改示意”这类方法的重点不在数值优化, 而在“规则如何进入修订流程”。
constitution = [ "不要提供违法操作步骤", "不确定时要明确说明边界",]
response = "你可以先暴力破解 Wi-Fi,应该肯定能成功。"
def critique(text): issues = [] if "破解" in text or "暴力" in text: issues.append("违反规则:不要提供违法操作步骤") if "肯定" in text and "不确定" not in text: issues.append("违反规则:不确定时不应过度自信") return issues
print("constitution =", constitution)print("response =", response)print("issues =", critique(response))预期输出:
constitution = ['不要提供违法操作步骤', '不确定时要明确说明边界']response = 你可以先暴力破解 Wi-Fi,应该肯定能成功。issues = ['违反规则:不要提供违法操作步骤', '违反规则:不确定时不应过度自信']这当然不是完整的 Constitutional AI, 但它把那条核心思路点出来了:
- 先显式写规则
- 再根据规则做批评和修订
六、这些方法到底怎么选?
Section titled “六、这些方法到底怎么选?”如果你已经有高质量人工偏好对,但资源一般
Section titled “如果你已经有高质量人工偏好对,但资源一般”优先可以看:
- DPO
- ORPO / IPO 一类直接偏好优化方法
如果人工标注成本太高
Section titled “如果人工标注成本太高”可以考虑:
- RLAIF
但要特别注意裁判模型的偏差和审计问题。
如果你更看重原则显式可解释
Section titled “如果你更看重原则显式可解释”可以关注:
- Constitutional AI
因为它很适合把:
- 公司政策
- 安全原则
- 行为规范
显式写进流程里。
如果你需要最完整、最强控制力的偏好优化链
Section titled “如果你需要最完整、最强控制力的偏好优化链”仍然可能选择:
- RLHF
因为在高预算、高质量数据和强工程能力下, 它依然很有价值。
七、这些误区特别常见
Section titled “七、这些误区特别常见”误区一:DPO 出来以后,RLHF 就过时了
Section titled “误区一:DPO 出来以后,RLHF 就过时了”不对。 更准确的说法是:
- DPO 把很多原本做不起 RLHF 的场景打开了
但并不等于 RLHF 自动失效。
误区二:RLAIF 不用人工,所以一定更划算
Section titled “误区二:RLAIF 不用人工,所以一定更划算”AI feedback 便宜,不代表完全免费。 它会把人工成本换成:
- 裁判模型质量问题
- 审计和偏差控制问题
误区三:宪法式 AI(Constitutional AI)只要写几条规则就行
Section titled “误区三:宪法式 AI(Constitutional AI)只要写几条规则就行”规则写出来只是开始。 更难的是:
- 规则是否互相冲突
- 是否覆盖边界场景
- 修订后是否真的更好
一个实用的选型速查表
Section titled “一个实用的选型速查表”当你在项目里选择对齐方法时,可以先问 4 个问题:
| 问题 | 如果答案是“是”,优先考虑 |
|---|---|
| 你已经有高质量的人类偏好对吗? | DPO / ORPO / IPO |
| 人工标注成本太高吗? | RLAIF |
| 你希望规则明确且可审查吗? | Constitutional AI |
| 你有足够预算和团队成熟度来跑最完整的流程吗? | RLHF |
这不是硬性规定,而是实用捷径。
最有用的习惯,是把方法选择和评测连在一起:
- 如果方法降低了成本,就要确认它没有破坏安全行为。
- 如果方法提高了可解释性,就要确认它仍然改善了真实用户结果。
- 如果方法简化了训练,就要确认固定测试集仍然能通过。
学完这一页,至少保留这张证据卡:
- 方法
- DPO、宪法式修订、RLAIF 或拒绝采样
- 训练信号
- 成对偏好、批注或筛选后的样本
- 收益
- 更简单的流水线、更少的 RL 复杂度,或更清晰的策略
- 局限
- 仍然依赖数据、策略和评估质量
- 决策
- 根据可用反馈和风险选择方法
这一节最重要的主线是:
替代对齐方法并不是在否定 RLHF,而是在回答“怎样用更短的链条、更低的成本,把偏好优化做出来”。
把几条路线放在一起看,你会更容易形成工程判断:
- 想简化训练链条,看 DPO 一系
- 想降低人工反馈成本,看 RLAIF
- 想把原则显式写进系统,看 Constitutional AI
当你能按“反馈来源、训练复杂度、可解释性、成本”去选方法时, 就说明你已经不只是在背术语了。
- 用自己的话解释:为什么说 DPO 的重点是直接优化偏好边距,而不是先学奖励模型?
- 参考本节代码,自己改一改
policy_chosen_logp和policy_rejected_logp,观察 DPO loss 如何变化。 - 如果你的团队几乎拿不到人工偏好数据,但可以调用一个更强的评审模型,你会优先考虑哪条路线?为什么?
- 想一想:在你的业务里,有没有一些原则非常适合写成 Constitutional AI 风格的“宪法规则”?
参考实现与讲解
- DPO 直接利用偏好对,让策略提高 preferred answer 的概率、降低 rejected answer 的概率。它绕开了“先训练奖励模型,再跑 RL loop”的流程。
- 当
chosen比rejected有更大的 log probability 边距时,loss 应该下降;如果rejected的 log probability 更高,loss 会变大,并给出更强的修正信号。 - 可以优先考虑 RLAIF 风格的偏好生成,或 Constitutional AI 风格的修订/评审流程,但要保留抽样审计。关键风险是 judge model bias,所以仍需要人工 spot check。
- 适合写成“宪法规则”的原则通常稳定、可解释、与产品风险直接相关,例如保护隐私、不可逆操作前先确认、区分事实与猜测、拒绝危险指令、高风险结论必须给证据。