9.2.2 LLM 推理能力
- 理解“知识检索”和“推理求解”不是一回事
- 理解 LLM 推理常见的三种任务形态
- 通过可运行示例理解“中间状态”为什么重要
- 理解 Agent 为什么不能只靠工具,还需要推理层
这节和前面 Agent 基础是怎么接上的
Section titled “这节和前面 Agent 基础是怎么接上的”如果你刚学完“什么是 Agent”,可以先把这节理解成:
- 前面已经知道 Agent 需要围绕目标采取行动
- 这一节开始回答:它到底靠什么把复杂问题拆开,并把中间状态维持住
所以这节真正重要的不是“推理听起来很高级”,而是:
- 推理层在 Agent 系统里到底负责什么
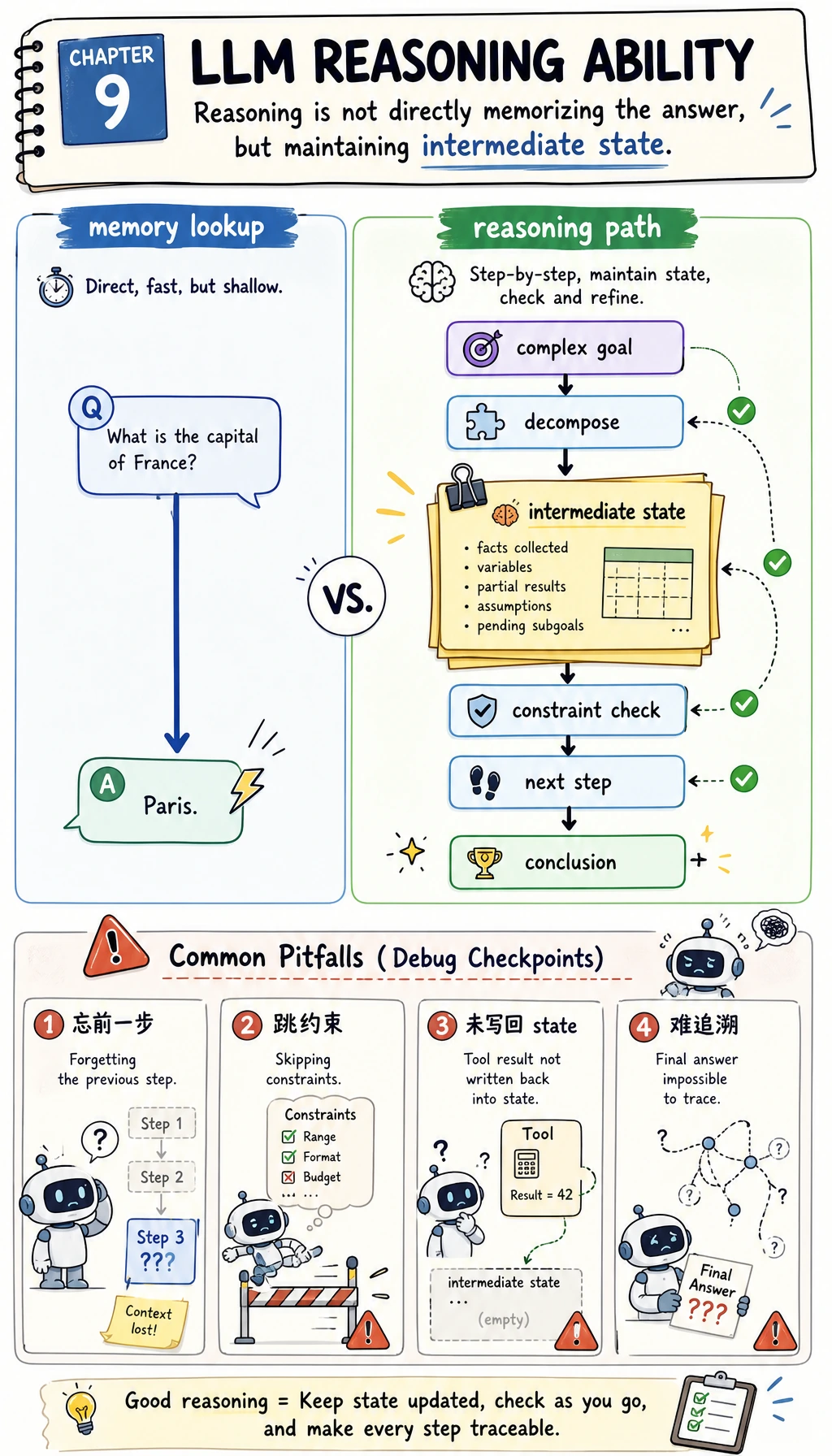
什么叫“推理”,它和“记住答案”有什么区别?
Section titled “什么叫“推理”,它和“记住答案”有什么区别?”记住答案:像查脑内词典
Section titled “记住答案:像查脑内词典”如果我问:
- 法国首都是哪里?
模型更像是在调用已经学到的知识模式。 这类问题更接近:
- 记忆
- 检索
- 模式匹配
推理:答案不直接放在题面里
Section titled “推理:答案不直接放在题面里”如果我问:
3 * (4 + 2) - 5等于多少?
模型不能只靠“背过这个式子”。 它需要做:
- 先算括号
- 再做乘法
- 最后做减法
也就是说:
推理问题的关键,不是有没有见过原题,而是能不能维持一条正确的中间状态链。
第一次学推理,最该先抓住什么?
Section titled “第一次学推理,最该先抓住什么?”最该先抓住的不是术语,而是这句:
推理真正难的不是最后那一下回答,而是中间步骤能不能持续对。
这句话一旦稳住,后面你再看:
- Chain-of-Thought
- ReAct
- Plan-and-Execute
就会更自然地把它们理解成“在帮模型守住中间状态链”。
一个类比:推理像做菜,不是念菜名
Section titled “一个类比:推理像做菜,不是念菜名”“知道宫保鸡丁是什么”更像知识。 “把鸡肉腌一下,再爆香,再调汁,再收汁”更像推理。
它要求系统:
- 知道顺序
- 记住中间结果
- 不要跳步
LLM 推理常见会遇到哪三类问题?
Section titled “LLM 推理常见会遇到哪三类问题?”算术和符号推理
Section titled “算术和符号推理”例如:
- 多步四则运算
- 日期和时间推算
- 单位换算
这类问题的特点是:
- 结论由步骤决定
- 步骤一错,后面全错
约束满足与比较决策
Section titled “约束满足与比较决策”例如:
- 在预算、时间、库存约束下选方案
- 排班
- 路线规划
这类问题不一定只是算数, 它更强调:
- 多条件同时成立
- 中间判断不能互相矛盾
工具调用前后的状态整合
Section titled “工具调用前后的状态整合”这是 Agent 场景里最常见的一类。
例如:
- 先查天气
- 再查航班
- 最后决定是否改签
工具会给你外部信息, 但把这些信息合成结论,仍然需要推理。
为什么这三类问题特别适合当 Agent 入口来学?
Section titled “为什么这三类问题特别适合当 Agent 入口来学?”因为它们都不是“查到就完”的问题,而是:
- 要先拆步骤
- 要保存中间结果
- 要把外部观察再整合回来
这正好就是 Agent 推理层最核心的工作。
先跑一个真正体现“中间状态”的示例
Section titled “先跑一个真正体现“中间状态”的示例”下面这段代码会把一个算式解析成语法树, 然后递归求值,并把每一步计算过程记录下来。
它不是在模拟 LLM 本身, 而是在帮助你建立一层非常关键的直觉:
多步问题的核心,不是最后那一个答案,而是中间状态怎么正确传递。
import astimport operator
OPS = { ast.Add: ("+", operator.add), ast.Sub: ("-", operator.sub), ast.Mult: ("*", operator.mul), ast.Div: ("/", operator.truediv),}
def solve(node): if isinstance(node, ast.Constant): return node.value, []
if isinstance(node, ast.BinOp): left_value, left_steps = solve(node.left) right_value, right_steps = solve(node.right)
symbol, fn = OPS[type(node.op)] result = fn(left_value, right_value) step = f"{left_value} {symbol} {right_value} = {result}"
return result, left_steps + right_steps + [step]
raise TypeError(f"Unsupported node: {type(node)}")
expression = "3 * (4 + 2) - 5"tree = ast.parse(expression, mode="eval").bodyanswer, steps = solve(tree)
print("expression:", expression)print("steps:")for step in steps: print("-", step)print("answer:", answer)预期输出:
expression: 3 * (4 + 2) - 5steps:- 4 + 2 = 6- 3 * 6 = 18- 18 - 5 = 13answer: 13这段代码最值得学的不是 ast
Section titled “这段代码最值得学的不是 ast”真正值得带走的是:
- 每一步都会生成一个明确中间结果
- 后一步依赖前一步
- 最终答案只是最后一层状态
这和 LLM 做复杂推理时非常像。
为什么中间状态比“最终答案”更关键?
Section titled “为什么中间状态比“最终答案”更关键?”因为如果中间某步算错了, 你就算最后碰巧答对,也很难稳定复现。
推理系统真正要追求的是:
- 过程可依赖
- 错误可定位
而不是偶然命中一个答案。
为什么 Agent 特别依赖这种能力?
Section titled “为什么 Agent 特别依赖这种能力?”因为 Agent 处理的问题通常不是单步完成的。 它可能要:
- 先读需求
- 再查数据
- 再比较约束
- 最后再选动作
这本质上就是在维护一条更长的中间状态链。
这段代码为什么比“最后答案对了”更有教学价值?
Section titled “这段代码为什么比“最后答案对了”更有教学价值?”因为它让你清楚看到:
- 每一步是怎么来的
- 下一步依赖什么
- 错误到底会从哪一步开始传下去
而 Agent 系统最需要的,恰恰就是这种:
- 过程可读
- 中间状态可查
- 错误可定位
LLM 推理为什么有时会强,有时又会突然失常?
Section titled “LLM 推理为什么有时会强,有时又会突然失常?”它擅长模式化的逐步结构
Section titled “它擅长模式化的逐步结构”如果任务可以被组织成比较清晰的步骤, LLM 往往能表现不错,例如:
- 分解问题
- 解释理由
- 生成候选方案
它容易在长链条上漂移
Section titled “它容易在长链条上漂移”常见问题包括:
- 漏步骤
- 重复步骤
- 中间数字算错
- 前后约束自相矛盾
也就是说, LLM 的推理能力不是“稳定逻辑引擎”, 而更像:
- 善于生成步骤草稿的语言推理器
所以很多复杂任务要配合外部工具
Section titled “所以很多复杂任务要配合外部工具”例如:
- 用计算器做精确数值
- 用数据库查真实状态
- 用规则引擎检查约束冲突
Agent 里的推理层,常常不是独立工作, 而是和工具协作。
为什么“会推理”和“会聊天”完全不是一回事?
Section titled “为什么“会推理”和“会聊天”完全不是一回事?”因为聊天更像:
- 语言流畅
- 风格自然
而推理更像:
- 步骤要对
- 约束不能冲突
- 中间状态要稳
这也是为什么一个看起来“很会说”的模型,在复杂多步任务里仍然可能失常。
什么时候该启用“更强的推理模式”?
Section titled “什么时候该启用“更强的推理模式”?”当答案需要多步推导
Section titled “当答案需要多步推导”如果问题本身明显需要:
- 分步计算
- 先后判断
- 条件筛选
那就值得启用更显式的推理策略。
当错误代价高
Section titled “当错误代价高”例如:
- 财务计算
- 配置修改
- 医疗建议辅助
这类问题里, “看起来合理”不够, 更需要:
- 过程可核验
当问题依赖外部观察结果
Section titled “当问题依赖外部观察结果”例如:
- 先查库存,再做下单建议
- 先看航班,再做改签判断
这时推理必须和工具观察结合。
最常见的误区
Section titled “最常见的误区”误区一:只要模型大,就天然会推理
Section titled “误区一:只要模型大,就天然会推理”模型更大通常会带来更好的上限, 但不代表所有复杂推理都会稳定。
误区二:推理就是把步骤写长一点
Section titled “误区二:推理就是把步骤写长一点”不是。 真正有效的推理,是:
- 步骤彼此有依赖
- 中间状态可复用
- 最终答案由过程支撑
误区三:有工具就不需要推理
Section titled “误区三:有工具就不需要推理”工具只提供外部能力。 决定:
- 什么时候调用
- 调什么
- 结果怎么整合
仍然要靠推理。
学完这一页,至少保留这张证据卡:
- 任务目标
- Agent 想要解决什么
- 计划或轨迹
- 推理步骤、计划、ReAct 轨迹或执行图
- 观察
- 每次操作后发生了什么变化
- 失败检查
- 虚构步骤、过时观察、循环或未经验证的结论
- 评估动作
- 与期望结果对比并修正计划
这节课最重要的,不是把“推理”神秘化, 而是先建立一个清楚判断:
LLM 推理能力的本质,是在多步问题里维护正确的中间状态,并把外部信息、约束条件和局部结果整合成最终结论。
只要这层判断立住了, 后面你再学:
- CoT
- ReAct
- Plan-and-Execute
就会知道它们其实都是在帮助模型更稳定地完成这件事。
这节最该带走什么
Section titled “这节最该带走什么”- 推理不是“把答案写长一点”,而是维持一条正确中间状态链
- Agent 之所以需要推理,是因为很多任务不是单步完成
- 工具提供能力,推理负责组织这些能力和结果
- 把示例里的算式换成
12 / (3 + 1) + 7,看看步骤输出是否符合你的预期。 - 用自己的话解释:为什么说推理问题的关键在“中间状态”而不只在“最终答案”?
- 想一个你做过的 Agent 任务,找出其中至少两步明确依赖前一步结果的地方。
- 为什么说“有工具”不等于“会推理”?
参考实现与讲解
12 / (3 + 1) + 7应该先变成12 / 4 + 7,再变成3 + 7,最后得到10。真正要检查的是每一步是否一致,而不只是最终数字对不对。- 中间状态能暴露模型是否保留了事实、选择了有效操作,并且没有跳过依赖关系。
- 示例:先检索政策再判断资格;先检查数据列再选择分析方法;先调用工具,再总结工具返回的结果。
- 工具只提供可执行动作;推理负责决定何时用工具、怎样解释 observation,以及怎样把多个步骤连接到目标。