7 大模型原理、Prompt 与微调

本章只回答一个实用问题:用户把文字发给大模型后,这段文字经历了什么路径,我们又怎样让输出稳定到可以放进应用里?
不要从背模型名字开始。先掌握你能操作的循环:文本变成 token,token 变成向量,Transformer 根据上下文预测下一个 token,然后你用 Prompt、结构化输出、RAG、微调或工具来控制结果。
你在主线中的位置
Section titled “你在主线中的位置”现在你会把第 4-6 章的模型基础用到语言模型场景里。向量会变成 embedding,评估习惯会变成 Prompt 和输出评估,Transformer 直觉会变成从 token 到答案的路径。
这一章是从理解模型走向构建大模型应用的桥。第 8 章会加入外部文档和检索,第 9 章会加入围绕目标的工具使用和可追踪动作。
它和第 11 章的 NLP 专题会有少量重叠,这是有意安排的:第 7 章关心“怎样把 LLM 用进应用”,所以 token、embedding、Transformer 只讲到能支撑 Prompt、RAG、微调判断为止;第 11 章会从文本任务本身重新组织这些概念,更关注标签、抽取、序列标注、评估和传统 NLP 到预训练模型的路线。
先看完整流程
Section titled “先看完整流程”
整章学习都可以围绕这张图走。
| 术语 | 通俗含义 | 实操时检查什么 |
|---|---|---|
| Token | 文本切分后的较小单位 | Prompt 是否放得进上下文窗口? |
| Embedding | token 或文本片段对应的向量 | 相似含义是否足够接近,能否用于比较或检索? |
| Transformer | 用 attention 混合上下文的模型架构 | 前面的哪些词、例子或规则影响了回答? |
| 预训练 | 从大量数据中学习通用语言规律 | 任务开始前,模型已经具备了什么通用能力? |
| Prompt | 当前发送给模型的任务说明和上下文 | 能否先用更清楚的说明解决问题? |
| 微调 | 用训练样本改变模型的长期行为 | 这是反复出现的行为问题,还是只是缺少知识? |
| 对齐 | 让输出更安全、更接近人的意图 | 即使回答流畅,还可能在哪些地方失败? |
学习顺序与任务表
Section titled “学习顺序与任务表”完整工作坊应该放在最后。先建立心智模型,再跑全流程实验。优先走核心应用路径:7.1 -> 7.2 -> 7.5 -> 7.8。7.3、7.4、7.6、7.7 作为更深的模型适配章节,用来解释行为、成本或训练选择。
| 步骤 | 阅读内容 | 要动手做什么 | 留下什么证据 |
|---|---|---|---|
| 7.1 | NLP 速成 | 运行 tokenizer 和 embedding 示例 | 能解释 token、向量和上下文的笔记 |
| 7.2 | LLM 概览与发展史 | 标出规模、数据、指令微调、对齐如何改变模型行为 | 一张时间线或能力来源图 |
| 7.5 | Prompt 工程 | 用固定输入比较多个 Prompt 版本 | Prompt 版本、输出、分数和失败样本 |
| 7.8 | 阶段项目 | 运行 7.8.4 实操:第 7 章完整工作坊 | 终端输出、通过率、README 记录 |
| 7.3-7.4 | Transformer 与预训练 | 读懂直觉,再跑通 mini GPT-2 | 一张解释 attention、上下文和训练目标的图,以及一次 device: cuda GPU 训练日志 |
| 7.6 | 微调 | 判断任务该用 Prompt、RAG 还是微调 | 一张简短方案判断表 |
| 7.7 | 对齐 | 检查失败模式和安全边界 | 一份安全/评估清单 |
必修主线、扩展和深度挑战
Section titled “必修主线、扩展和深度挑战”- 必修核心:Tokenization、embedding、上下文窗口、LLM API 调用、Prompt 测试、结构化输出和基础安全检查。这是进入 RAG 和 Agent 应用前的最小能力。
- 可选扩展:Transformer 内部结构、预训练细节、微调和对齐历史。当模型行为、成本或适配方案需要更深解释时再回来。
- 深度挑战:手搓 mini GPT-2、固定评估集,只改一个 Prompt/结构约束/模型设置,并保存失败样本。它会把大模型使用从演示变成工程闭环。
第一个可运行循环:不用 API 测 Prompt
Section titled “第一个可运行循环:不用 API 测 Prompt”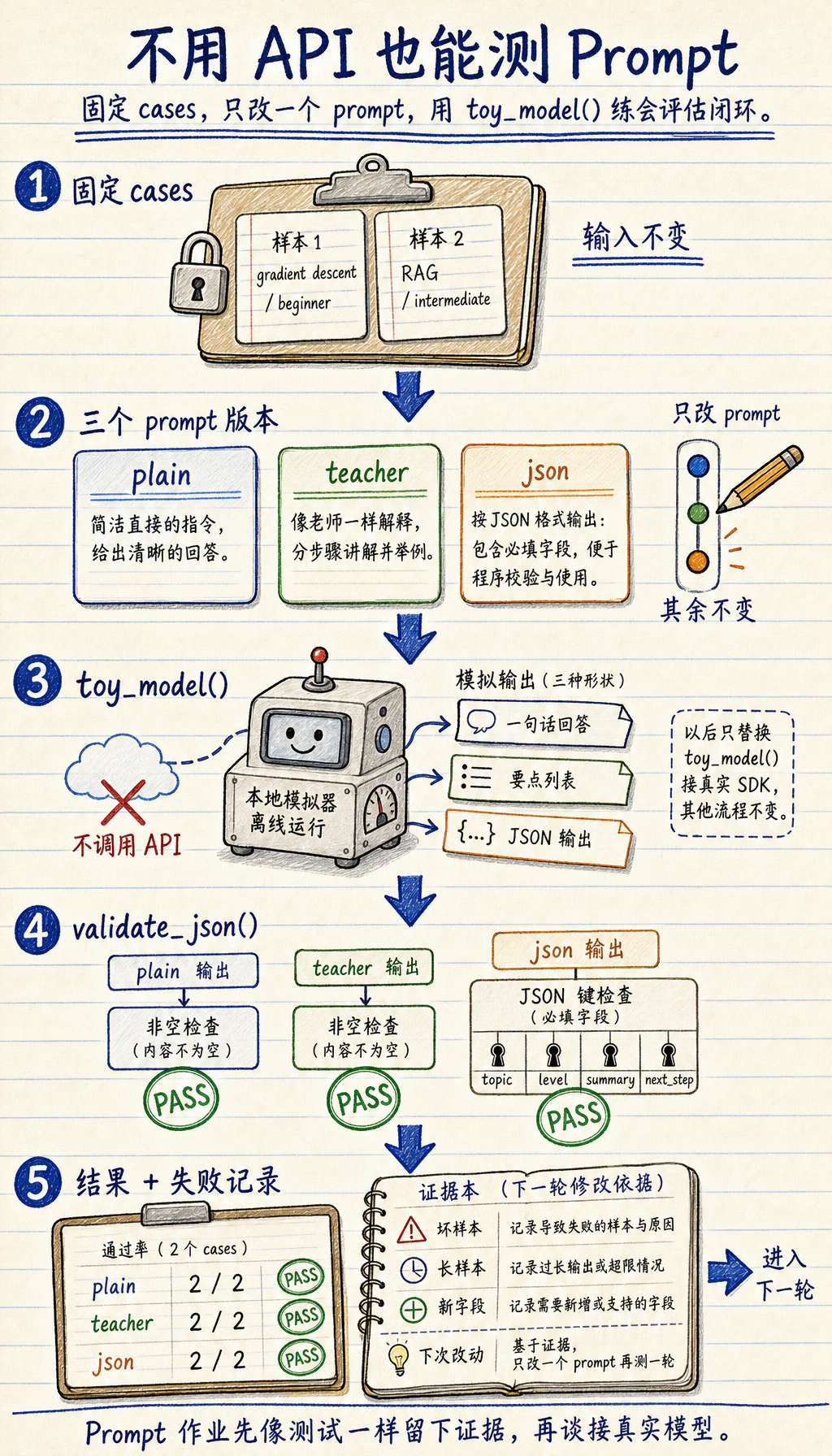
Prompt 工作应该像软件测试:固定输入样本,每次只改一个 Prompt 变量,校验输出,并保存失败样本。
新建 ch07_prompt_test.py,用 Python 3.10 或更新版本运行。这个离线示例不会调用真实模型,它只是帮你练会评估循环。后面接入真实 LLM SDK 时,只需要替换 toy_model()。
import json
cases = [ {"topic": "gradient descent", "level": "beginner"}, {"topic": "RAG", "level": "intermediate"},]
prompts = { "plain": "Explain the topic.", "mentor": "You are a patient AI mentor. Explain the topic in 3 short bullets.", "json": "Return JSON with keys: topic, level, summary, next_step.",}
def toy_model(prompt: str, case: dict) -> str: topic = case["topic"] level = case["level"] if "Return JSON" in prompt: return json.dumps( { "topic": topic, "level": level, "summary": f"{topic} explained for {level} learners", "next_step": "Run one small example and record the result", }, ensure_ascii=False, ) if "patient AI mentor" in prompt: return f"- Define {topic}\n- Show one example\n- Ask the learner to retry" return f"{topic} is an AI concept."
def validate_json(raw: str) -> bool: try: data = json.loads(raw) except json.JSONDecodeError: return False return {"topic", "level", "summary", "next_step"} <= data.keys()
for prompt_name, prompt in prompts.items(): passed = 0 for case in cases: output = toy_model(prompt, case) ok = validate_json(output) if prompt_name == "json" else bool(output.strip()) passed += int(ok) print(f"{prompt_name}: {passed}/{len(cases)} cases passed")预期输出:
plain: 2/2 cases passedmentor: 2/2 cases passedjson: 2/2 cases passed操作提示:再加一个坏样本、一个更长样本、一个新的输出字段要求。如果分数变化了,就记录是哪一次 Prompt 改动导致的。这个习惯比单次“看起来不错”的回答更重要。
| 层级 | 你能证明什么 |
|---|---|
| 最低通过 | 能解释从 token 到答案的路径,并在没有真实 API 的情况下运行固定 Prompt 测试。 |
| 项目可用 | 能固定输入,每次只改一个 Prompt 或 结构约束 变量,校验结构化输出,并保存失败样本。 |
| 深度检查 | 能用证据判断该用 Prompt、RAG、微调还是工具,而不是凭偏好选择,并说清安全边界。 |
选择 Prompt、RAG、微调还是工具
Section titled “选择 Prompt、RAG、微调还是工具”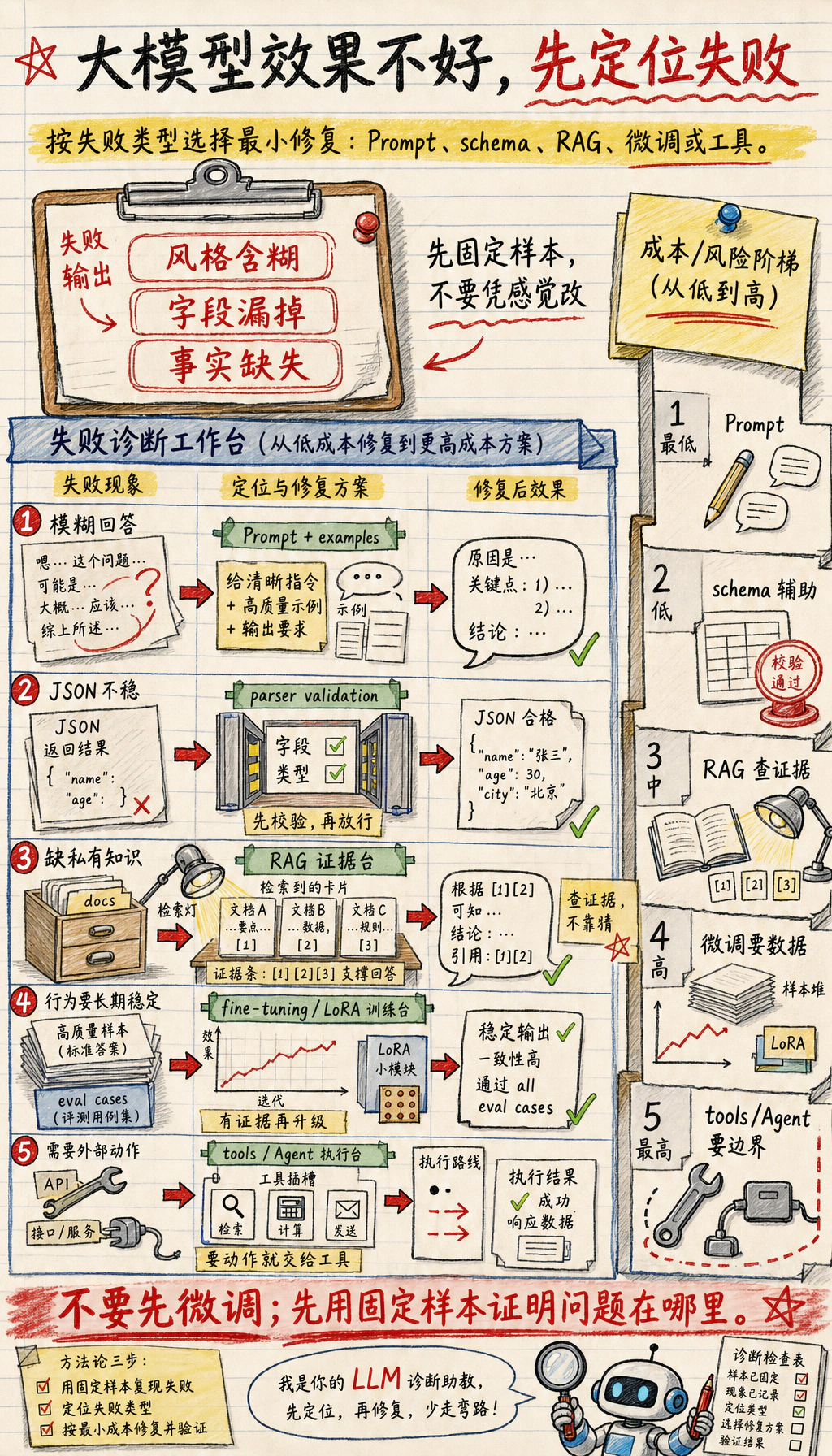
大模型效果不好时,不要直接跳到微调。
| 现象 | 先尝试什么 | 什么时候升级方案 |
|---|---|---|
| 回答风格含糊 | 改 Prompt,并加入示例 | 明确说明后,固定样本仍然失败 |
| 应用需要 JSON 或表格 | 加 结构约束,并做解析校验 | 模型反复漏字段或类型错误 |
| 回答缺少私有或新知识 | 用 RAG 检索文档 | 检索准确,但模型仍按错行为执行 |
| 模型需要长期遵守领域行为 | 考虑微调或 LoRA | 已有足够高质量样本和评估集 |
| 任务需要外部动作 | 使用工具或 Agent 工作流 | 模型必须调用 API、搜索文件或执行步骤 |
学完这一页,至少保留这张证据卡:
- token 路径
- 文本 → token → embedding → Transformer 上下文 → 下一个 token
- 核心路线
- 先走 7.1 → 7.2 → 7.5 → 7.8
- 固定案例
- 在比较改动前,提示测试使用相同输入
- 方法选择
- 根据证据选择 Prompt、RAG、微调、工具或 Agent
- 章节桥接
- 第 8 章增加了检索和应用架构
- 把大模型当数据库:文字流畅不等于事实正确。
- 同时改 Prompt、输入样本和模型:你无法判断到底是谁改善了结果。
- 要求结构化输出却不校验:看起来像 JSON 的文本也可能无效。
- 过早微调:很多问题应该先用 Prompt、RAG、工具或产品逻辑解决。
- 还没看过输出循环就钻 Transformer 细节:理论会很难落地。
进入第 8 章前,你应该能做到:
- 用自己的话解释 token、embedding、attention、上下文窗口、预训练、Prompt、微调和对齐;
- 运行上面的 Prompt 测试循环,并做到每次只改一个变量;
- 保存 Prompt 版本、固定输入样本、输出、分数和失败样本;
- 判断一个任务该先用 Prompt、结构化输出、RAG、微调、工具还是 Agent;
- 跑通完整章节工作坊,并在简短 README 中记录结果。
可打印清单见 7.0 学习检查表。如果想直接做项目,从 7.8.4 实操:第 7 章完整工作坊 开始。