6.8.1 深度学习项目路线图:训练、检查、打包
本小章是第 6 章出口。深度学习项目不只是训练脚本,还需要数据证据、形状检查、loss 日志、预测样本、失败案例和 README。
先看项目闭环
Section titled “先看项目闭环”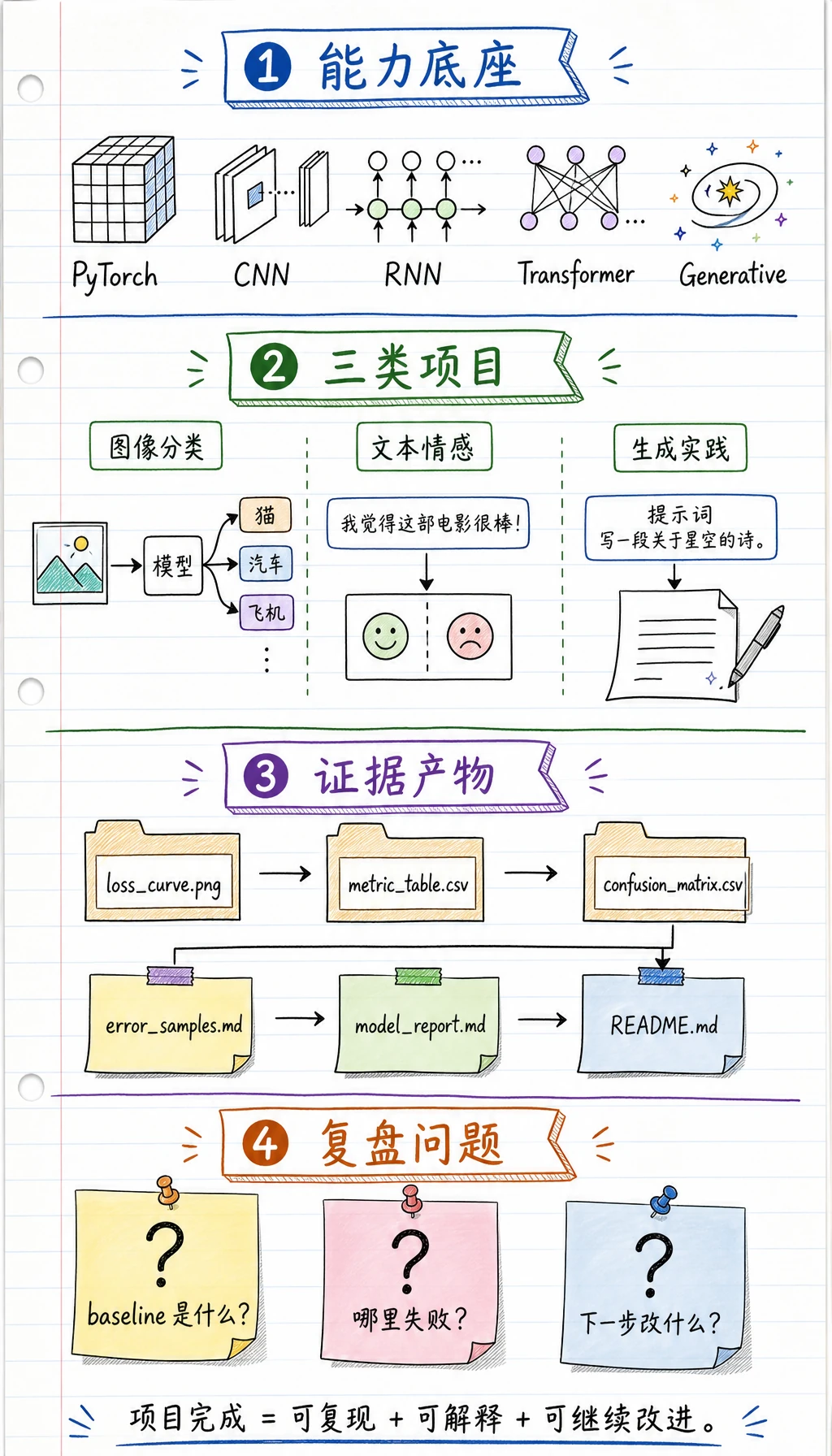
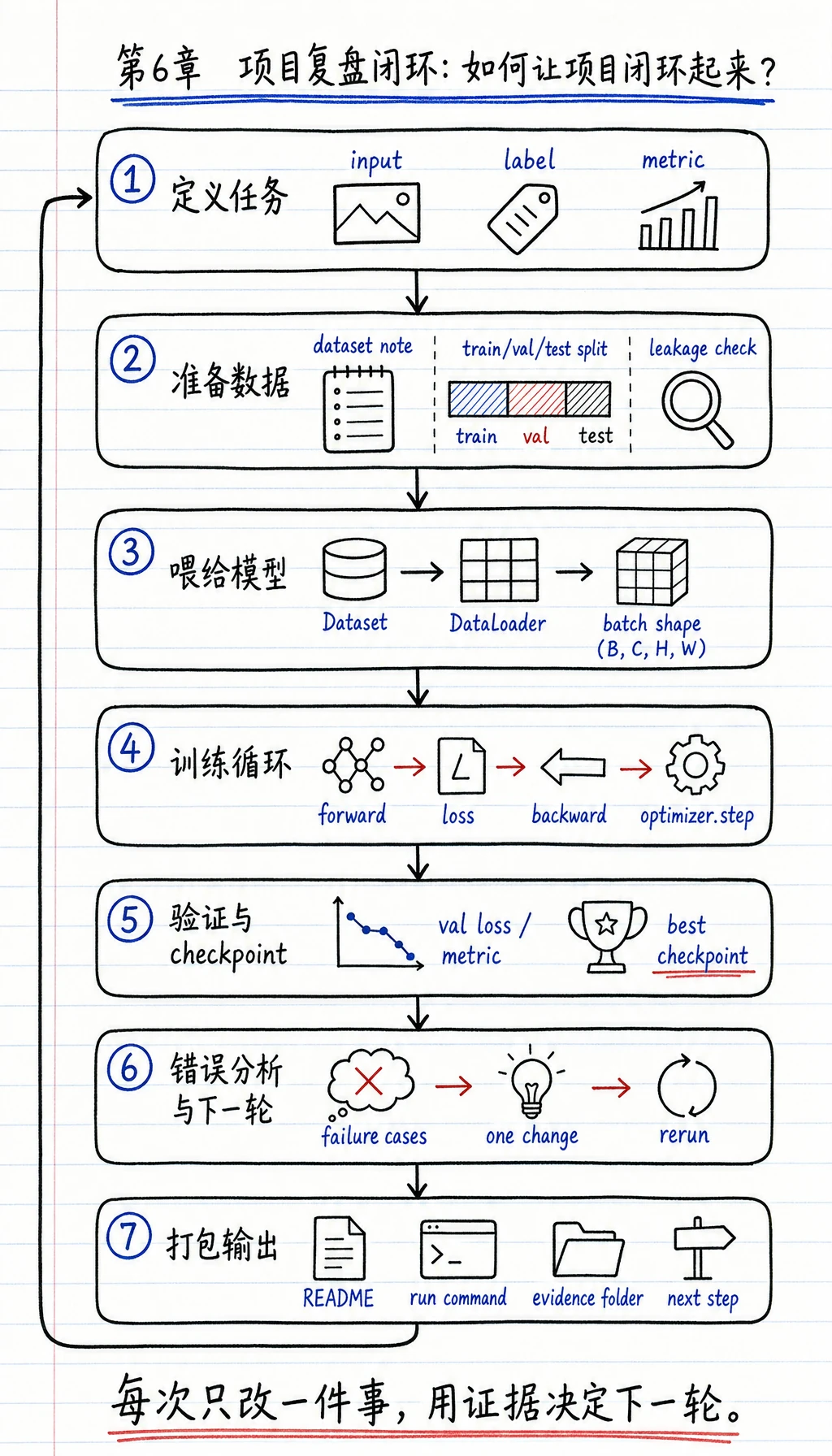
数据集模型训练日志评估失败案例打包
保留一份证据记录
Section titled “保留一份证据记录”创建 dl_project_evidence_first_loop.py。
evidence = { "task": "image classification", "baseline_accuracy": 0.71, "current_accuracy": 0.82, "failure_case_count": 5, "next_step": "inspect confused classes and add augmentation",}
print("task:", evidence["task"])print("improvement:", round(evidence["current_accuracy"] - evidence["baseline_accuracy"], 3))print("failure_case_count:", evidence["failure_case_count"])print("next_step:", evidence["next_step"])预期输出:
task: image classificationimprovement: 0.11failure_case_count: 5next_step: inspect confused classes and add augmentation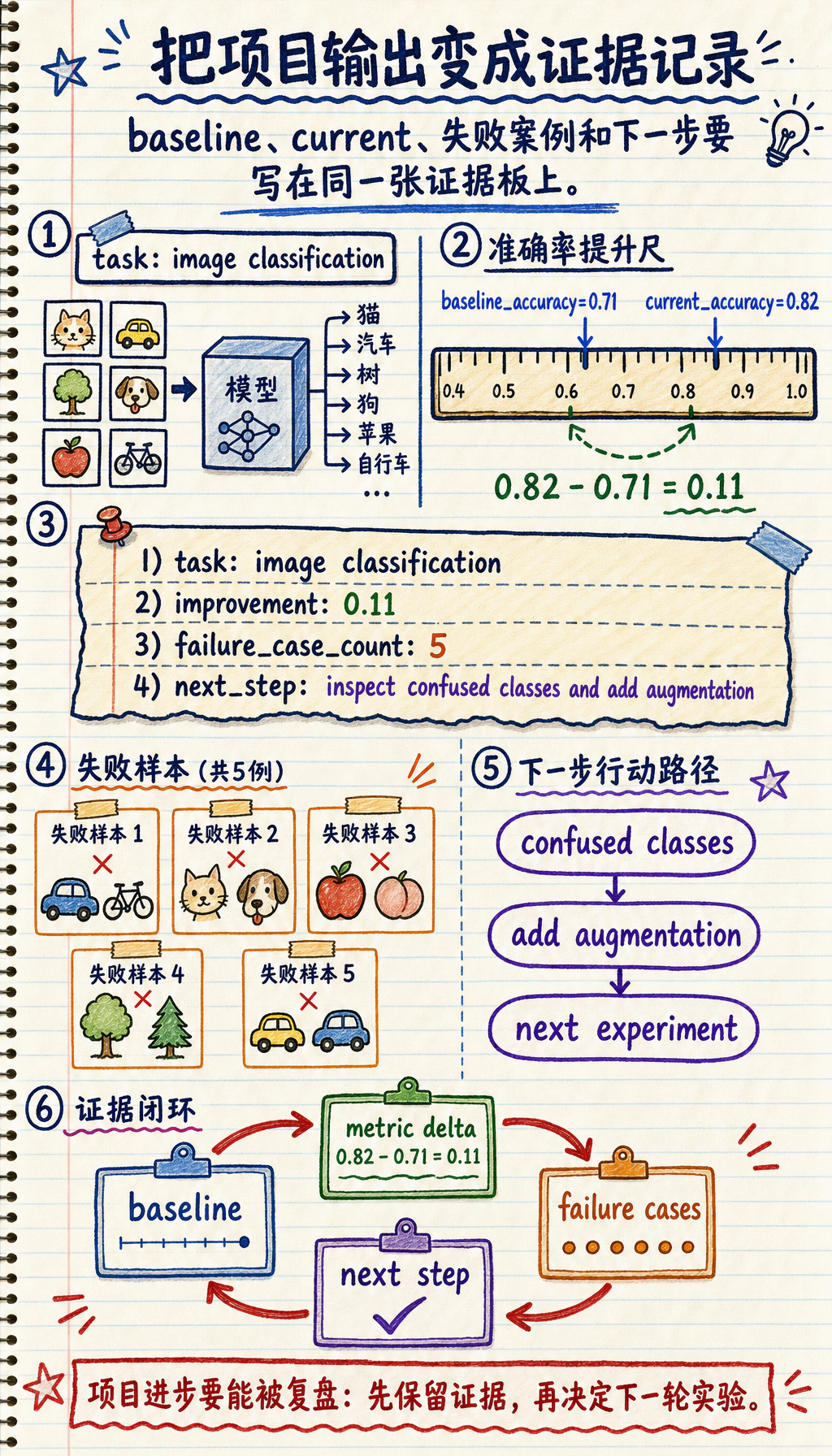
这就是项目习惯:每次改进都要有 baseline、指标、失败证据和下一步。
把项目打包成另一个学习者可以复现和审查的样子:
- 运行命令
- 可复现结果的准确命令
- 数据集说明
- 数据来源以及划分方式
- 基线
- 第一个简单的分数或行为
- 当前结果
- 当前指标加上成功样本
- 失败案例
- 至少三个错误或较弱示例
- 下一步
- 基于失败结果做一个改动
这样项目就不会停留在一次性演示。好的第 6 章项目应该可复现、可检查、可继续改进。
按这个顺序学
Section titled “按这个顺序学”| 顺序 | 阅读 | 交付什么 |
|---|---|---|
| 1 | 6.8.2 图像分类 | 数据集、CNN/迁移 baseline、预测样本 |
| 2 | 6.8.3 情感分析 | 文本流程、训练日志、错误样本 |
| 3 | 6.8.4 生成实践 | 生成样本和审查记录 |
| 4 | 6.8.5 DL 实操工作坊 | 一份可复现 PyTorch 证据包 |
项目交付物标准
Section titled “项目交付物标准”至少为一个项目保留这些文件:README.md、运行命令、数据集说明、模型摘要、loss 曲线或日志、指标表、预测样本、失败案例、下一步计划。
在说项目完成前,回答:
- Baseline
- what simple method did this beat?
- Metric
- what number proves improvement?
- Sample Success
- which predictions look correct?
- Sample Failure
- which predictions still fail?
- Debug Next
- what would you change first, and why?
如果不能展示失败,项目还只是演示,不是学习作品。
另一个学习者能运行你的项目、查看训练证据、看到成功和失败样本,并理解你下一步会怎么改,就算通过。
检查思路与讲解
- 合格答案要把 tensor、模型层、loss、
backward()和 optimizer 更新连成一个训练闭环。 - 证据应包含可运行的小实验、tensor shape 检查,以及能解释的 loss 或验证曲线。
- 自检时要能指出一个失败模式,例如 shape 不匹配、loss 不下降、过拟合、数据泄漏,或只会说 Attention/Transformer 名词却讲不出数据流。