5.5.1 特征工程路线图:让数据更容易被学习
特征工程是在让输入对模型更有用、更稳定、更安全。很多模型问题,其实是特征问题。
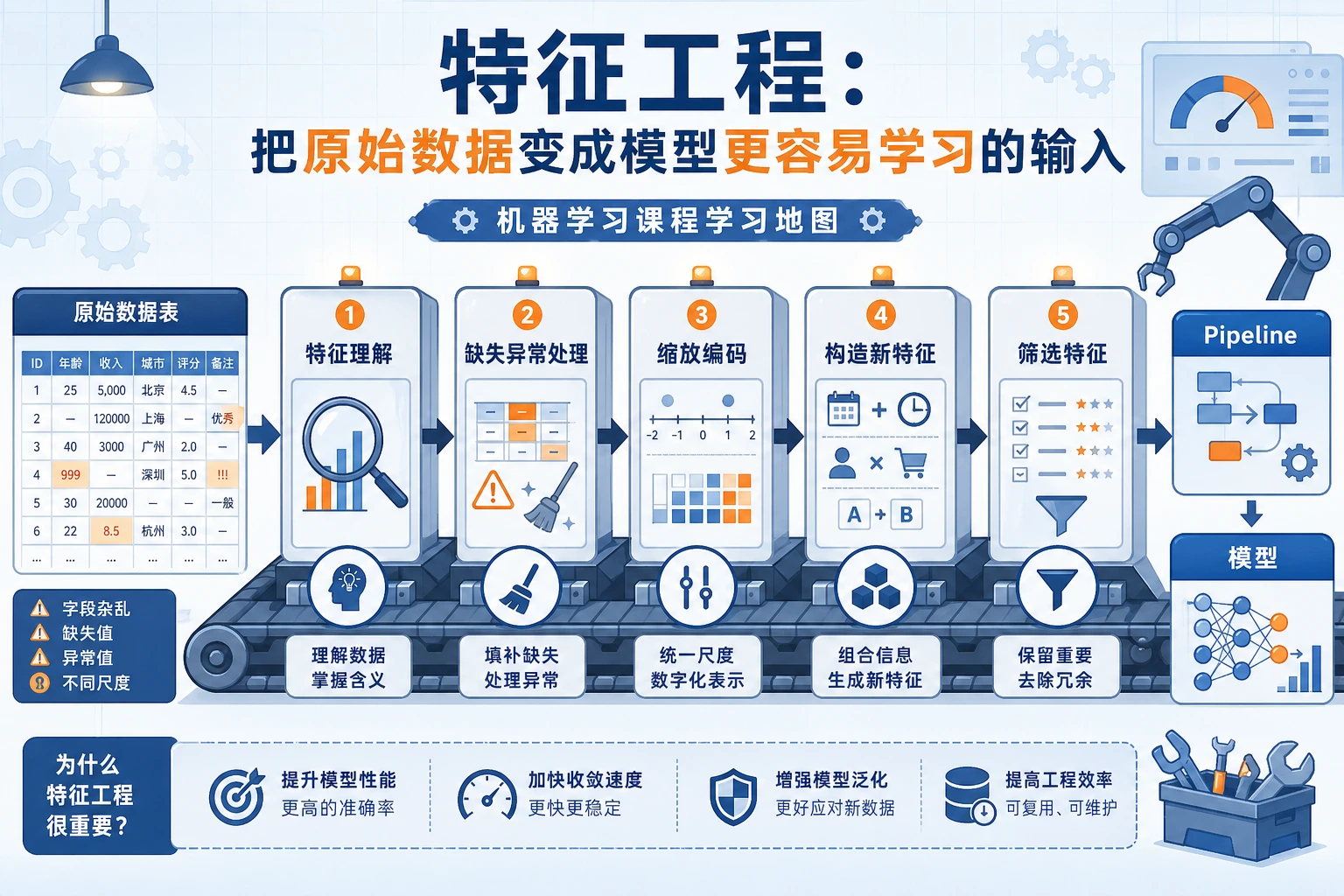
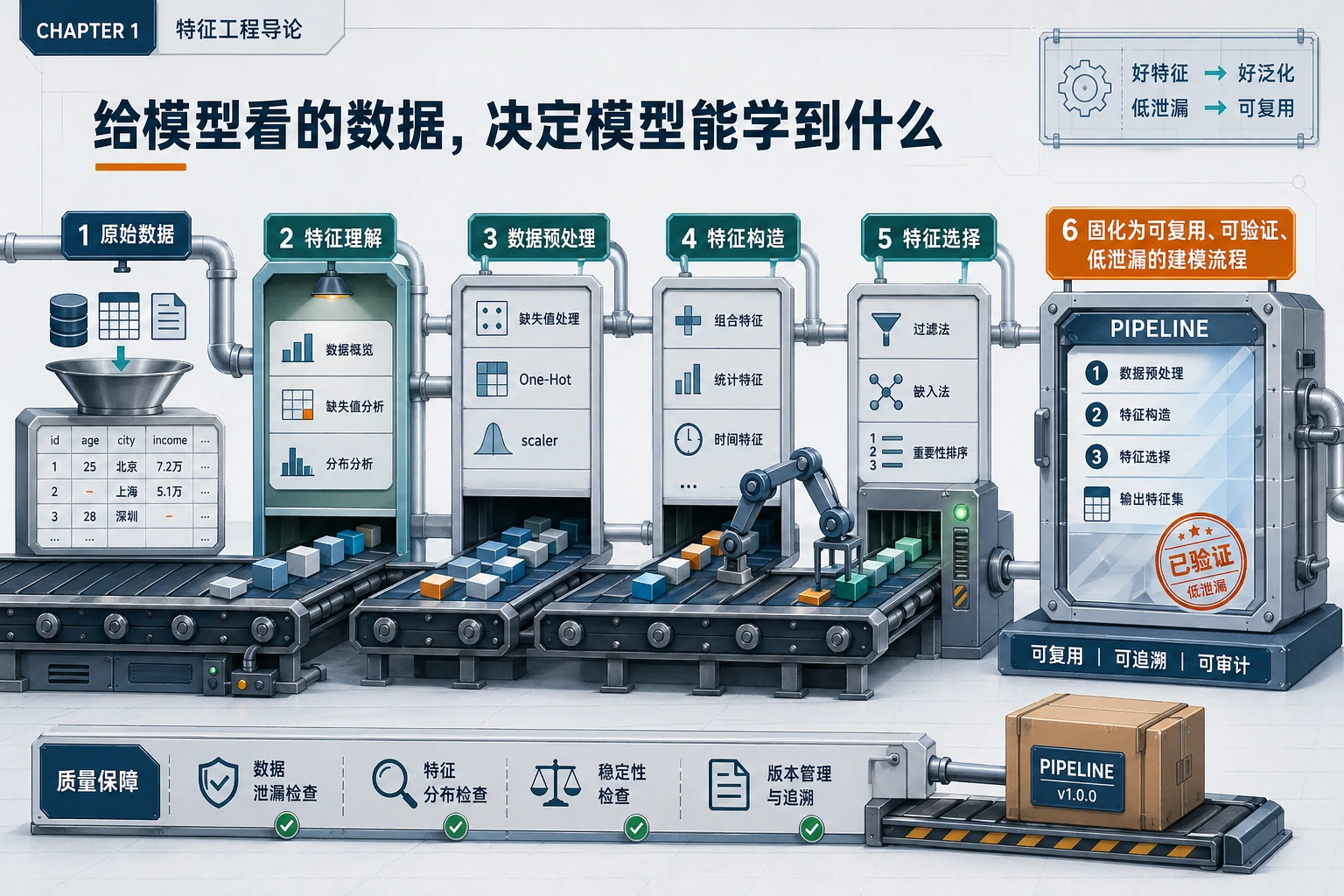
理解字段预处理构造选择封装成 Pipeline
| 步骤 | 第一动作 |
|---|---|
| 理解 | 列出数值、类别、文本、日期、目标列 |
| 预处理 | 缩放、编码、填补缺失值 |
| 构造 | 创建比例、计数、日期、交互特征 |
| 选择 | 去掉无用或泄漏特征 |
| Pipeline | 让预处理可复现 |
跑一个 Pipeline
Section titled “跑一个 Pipeline”创建 feature_first_loop.py,安装 pandas 和 scikit-learn 后运行。
import pandas as pdfrom sklearn.compose import ColumnTransformerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import OneHotEncoder, StandardScaler
X = pd.DataFrame( { "age": [22, 35, 47, 52, 28, 41], "city": ["A", "B", "A", "C", "B", "C"], "visits": [2, 6, 5, 9, 3, 7], })y = [0, 1, 1, 1, 0, 1]
preprocess = ColumnTransformer( transformers=[ ("num", StandardScaler(), ["age", "visits"]), ("cat", OneHotEncoder(handle_unknown="ignore"), ["city"]), ])
pipe = Pipeline([("preprocess", preprocess), ("model", LogisticRegression())])pipe.fit(X, y)
print("pipeline_steps:", list(pipe.named_steps))print("training_accuracy:", round(pipe.score(X, y), 3))预期输出:
pipeline_steps: ['preprocess', 'model']training_accuracy: 1.0这个数据太小,不能当真实评估。这里要学的是流程:预处理和模型应该一起走。
按这个顺序学
Section titled “按这个顺序学”| 顺序 | 阅读 | 练什么 |
|---|---|---|
| 1 | 5.5.2 特征理解 | 特征类型、目标列、泄漏风险 |
| 2 | 5.5.3 数据预处理 | 缩放、编码、缺失值 |
| 3 | 5.5.4 特征构造 | 比例、分箱、日期、交互 |
| 4 | 5.5.5 特征选择 | 去噪声、去冗余、防泄漏 |
| 5 | 5.5.6 Pipeline | 可复现的预处理和训练 |
能列出特征类型,构建一个预处理 Pipeline,并解释为什么在训练/测试流程外做预处理可能导致泄漏,就算通过。
检查思路与讲解
- 先列出特征类型、缺失值、尺度差异、类别基数,以及可能的目标泄漏。
- 预处理应放进
Pipeline或ColumnTransformer,这样训练集和测试集会使用同一套学到的转换,同时减少泄漏。 - 有价值的特征改动要留下前后证据:转换后的字段、分数变化、错误样本变化,或拒绝这个特征的理由。
学完这一页,至少保留这张证据卡:
- 特征状态
- 原始列、类型、缺失值、尺度,以及与目标的关系
- 特征变换
- 预处理、构造、选择或流水线步骤
- 输出
- 转换后的特征表、pipeline 对象、分数变化,或选出的特征
- 失败检查
- 泄漏、训练/测试转换不一致、高基数陷阱或无意义特征
- 期望产出
- 带有前后对比和指标影响的特征流水线证据