12.2.5 图像生成微调

- 理解为什么图像生成模型也需要微调
- 分清 DreamBooth、LoRA、Textual Inversion 的差别
- 理解这些方法分别更像在“改什么”
- 建立一个非常实用的选型直觉
先建立一张地图
Section titled “先建立一张地图”图像生成微调更适合按“你到底想改概念、风格,还是专属主体”来理解:
flowchart LR A["想加一个概念词"] --> B["Textual Inversion"] C["想低成本挂一个适配层"] --> D["LoRA"] E["想强绑定一个专属主体"] --> F["DreamBooth"]所以这节真正想解决的是:
- 不是哪条路线最火
- 而是你到底在微调什么目标
一、为什么基础模型还不够?
Section titled “一、为什么基础模型还不够?”基础模型当然已经会生成很多东西。 但真实需求通常会更具体:
- 生成某个专属角色
- 生成某种固定品牌风格
- 让某个产品在不同场景里保持一致
这时只靠 prompt 往往不够稳定。
所以微调的本质可以先记成:
让模型在原有能力上,往某个更具体的视觉目标收敛。
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把图像生成微调理解成:
- 给一个已经会画很多东西的画师做“定向风格训练”
基础模型像一个会画很多题材的通才, 但你真正想要的可能是:
- 某个固定 IP 角色
- 某种品牌视觉
- 某种专属风格
这时你不是要他从零学画画, 而是要他在某个方向上画得更稳定。
二、图像生成微调最核心的三种路线
Section titled “二、图像生成微调最核心的三种路线”Textual Inversion
Section titled “Textual Inversion”最轻的一种思路。 它更像:
给模型学一个新的触发词 / 概念词。
更像:
给基础模型挂一个小型可插拔适配器。
DreamBooth
Section titled “DreamBooth”更像:
强化模型对某个专属主体的记忆。
如果你先把这三个直觉区分开,后面很多术语就不会混。
三、Textual Inversion:为什么说它最轻?
Section titled “三、Textual Inversion:为什么说它最轻?”它本质上在学什么?
Section titled “它本质上在学什么?”不是大规模改整个模型,而是更像:
- 学一个新的 token 表示
你可以把它理解成:
教模型认识一个新的“词”。
一个极简示意
Section titled “一个极简示意”textual_inversion = { "new_token": "<my_style>", "meaning": "一种特定视觉风格", "learned_object": "token embedding"}
print(textual_inversion)预期输出:
{'new_token': '<my_style>', 'meaning': '一种特定视觉风格', 'learned_object': 'token embedding'}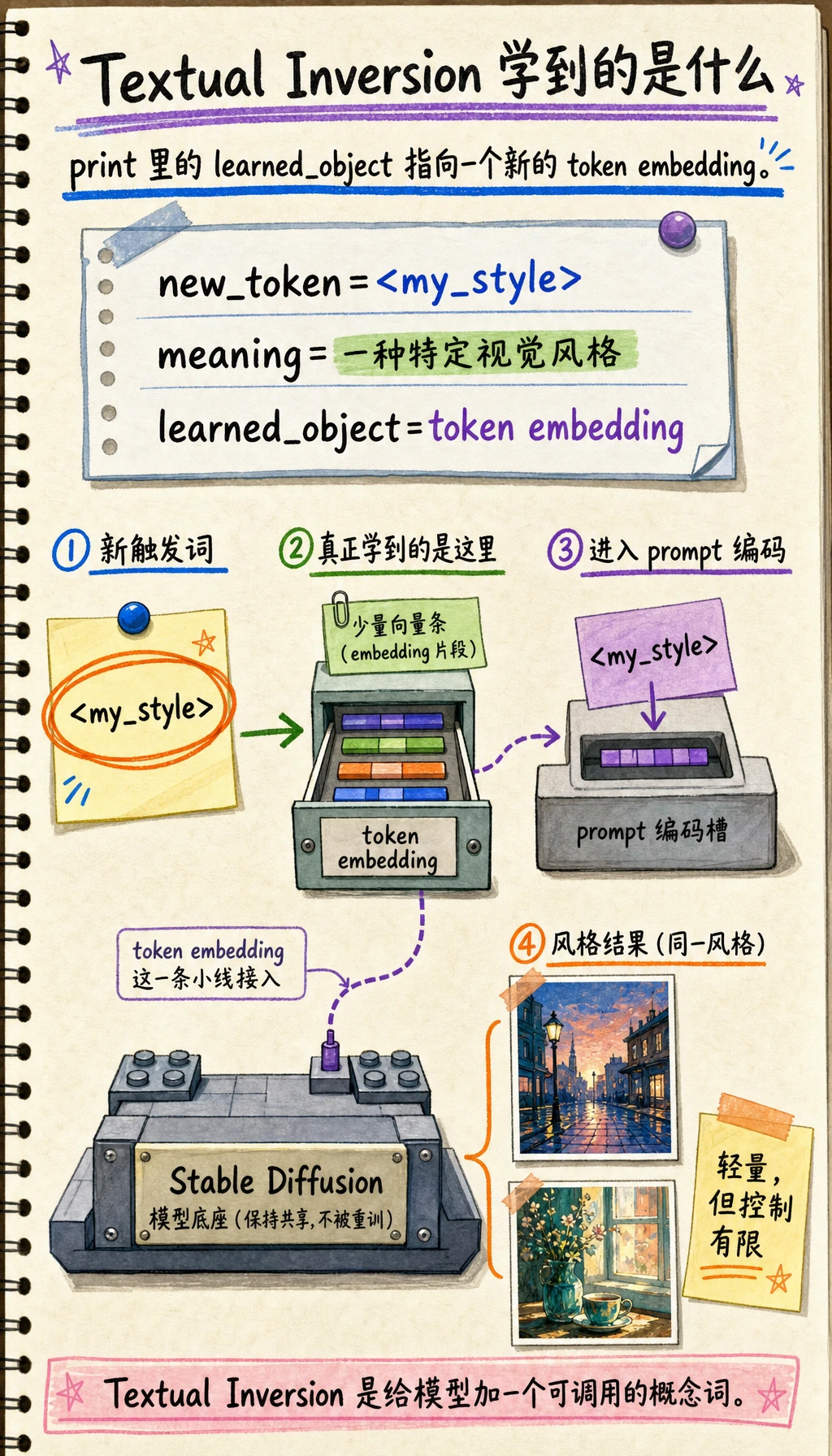
关键看 learned_object:Textual Inversion 主要学习一个新 token 的 embedding,所以它轻量,但控制能力也有限。
它适合什么?
Section titled “它适合什么?”- 风格 trigger word
- 某些轻量概念注入
它的优点是:
- 轻
- 快
- 改动范围小
但能力通常不如更重的方案强。
四、LoRA:为什么它会成为工程上最常见的一条路?
Section titled “四、LoRA:为什么它会成为工程上最常见的一条路?”它最核心的思想
Section titled “它最核心的思想”LoRA 不是把原模型整份都改掉,而是:
学一个低成本的增量适配器。
这让它非常适合:
- 在一个大基础模型上挂多个风格
- 切换不同适配器
- 降低训练和存储成本
一个简单示意
Section titled “一个简单示意”base_model = "stable_diffusion_base"lora_adapter = { "target": "attention blocks / U-Net blocks", "size": "small", "effect": "附加风格或主体控制能力"}
print(base_model)print(lora_adapter)预期输出:
stable_diffusion_base{'target': 'attention blocks / U-Net blocks', 'size': 'small', 'effect': '附加风格或主体控制能力'}
这就是 LoRA 流行的工程原因:基础模型保持共享,小适配器负责承载定制能力。
为什么它工程上特别实用?
Section titled “为什么它工程上特别实用?”因为它特别适合:
- 一个基础模型
- 多个不同风格或角色适配器
也就是说:
不需要每个定制版本都保存一整份完整模型。
这就是 LoRA 特别流行的重要原因。
五、DreamBooth:为什么它更常用于“专属主体”?
Section titled “五、DreamBooth:为什么它更常用于“专属主体”?”它在解决什么问题?
Section titled “它在解决什么问题?”DreamBooth 很常见的目标是:
- 让模型学会某一个具体人物
- 某一个具体物体
- 某一个专属 IP 形象
为什么它比 Textual Inversion 更“强”?
Section titled “为什么它比 Textual Inversion 更“强”?”因为它通常不是只学一个词,而是更深地让模型适应这个主体在图像空间中的表现。
代价是什么?
Section titled “代价是什么?”- 更重
- 更容易过拟合
- 更依赖数据质量
所以你可以先粗略记成:
- Textual Inversion:轻
- LoRA:平衡
- DreamBooth:更强但更重
六、怎么选?一个非常实用的判断
Section titled “六、怎么选?一个非常实用的判断”如果你想要一个轻量风格触发词
Section titled “如果你想要一个轻量风格触发词”优先考虑:
- Textual Inversion
如果你想要低成本、可插拔、可维护
Section titled “如果你想要低成本、可插拔、可维护”优先考虑:
- LoRA
如果你想强力绑定某个专属主体
Section titled “如果你想强力绑定某个专属主体”优先考虑:
- DreamBooth
所以真正好用的问题不是:
“哪个方法最强?”
而是:
“我到底在微调词、风格、还是主体?”
一个很适合初学者先记的选型表
Section titled “一个很适合初学者先记的选型表”| 你的目标 | 更稳的第一反应 |
|---|---|
| 先加一个触发词或轻概念 | Textual Inversion |
| 想低成本维护很多风格版本 | LoRA |
| 想强绑定一个具体人物 / 物体 / IP | DreamBooth |
这个表很适合新人,因为它会把方法选择重新拉回“目标到底是什么”。
七、为什么图像生成微调的评估特别难?
Section titled “七、为什么图像生成微调的评估特别难?”因为这里不像分类任务,不能只看一个准确率。
你通常还要看:
- 生成结果像不像目标风格
- 主体是否稳定一致
- 有没有过拟合训练图
- 不同 prompt 下表现是否仍然稳
也就是说:
评估更像视觉与创意质量判断,而不是单指标判断。
一个很适合初学者先记的评估表
Section titled “一个很适合初学者先记的评估表”| 评估维度 | 最值得先问什么 |
|---|---|
| 风格一致性 | 看起来像不像目标风格 |
| 主体一致性 | 是不是同一个人 / 同一个物体 |
| 泛化稳定性 | 换 prompt 后还稳不稳 |
| 过拟合 | 会不会只会复读训练图 |
这个表很适合新人,因为它会把“评估很主观”重新拆成几个更可观察的问题。
八、一个很实用的经验总结表
Section titled “八、一个很实用的经验总结表”| 方法 | 更像什么 | 优点 | 代价 |
|---|---|---|---|
| Textual Inversion | 学一个新词 | 轻量、快 | 控制能力有限 |
| LoRA | 装一个小适配器 | 成本低、可切换 | 仍需理解目标模块 |
| DreamBooth | 学专属主体 | 主体控制更强 | 更重、更容易过拟合 |
这张表不是让你死记,而是让你形成判断习惯。
九、最常见的误区
Section titled “九、最常见的误区”一上来就想全量微调
Section titled “一上来就想全量微调”很多时候完全没必要。
不清楚自己到底要微调“什么”
Section titled “不清楚自己到底要微调“什么””是风格?主体?触发词? 这个问题不清楚,方法就很容易选错。
只看几张成功图
Section titled “只看几张成功图”真正重要的是:
- 多 prompt 下稳不稳
- 多次采样下像不像
如果把它做成项目或方案,最值得展示什么
Section titled “如果把它做成项目或方案,最值得展示什么”最值得展示的通常不是:
- “我做了 SD 微调”
而是:
- 你的目标到底是概念、风格,还是主体
- 你为什么选了这条微调路线
- 评估时看了哪些维度
- 生成结果在哪些 prompt 下稳,哪些 prompt 下不稳
这样别人会更容易看出:
- 你理解的是选型与评估
- 不只是跑了一次训练脚本
学完这一页,至少保留这张证据卡:
- 提示词记录
- 提示词、负面要求、参考、seed/model,以及版本号
- 候选输出
- 生成或模拟的结果及选择原因
- 技术备注
- 扩散步、潜变量、cross-attention、LoRA 或应用模式
- 失败检查
- 提示漂移、风格不匹配、产物、版权、肖像或复核失败
- 期望产出
- 选定图片/版本记录加被拒候选说明
这一节最重要的不是背 DreamBooth、LoRA、Textual Inversion 这些名字,而是理解:
图像生成微调的核心,是用不同代价去换取对风格、主体或概念更稳定的控制。
一旦这个判断建立起来,后面看具体训练工作流时就会轻松很多。
- 用自己的话解释 Textual Inversion、LoRA、DreamBooth 分别更像在“改什么”。
- 想一想:如果你只想给模型加一个风格 trigger word,为什么不一定需要 DreamBooth?
- 如果你要长期维护很多风格版本,为什么 LoRA 特别有工程价值?
- 为什么说图像生成微调的评估,比文本分类更依赖人工感知判断?
解题思路与讲解
- Textual Inversion 更像新增一个 token embedding;LoRA 更像给模型层外挂一个小型可拆卸技能补丁;DreamBooth 更像用更直接的样例教模型记住某个具体主体或身份。
- 如果只是想增加一个风格触发词,Textual Inversion 或 LoRA 可能已经足够,因为你并不需要深度改写模型对具体主体的认识。
- 从工程角度看,LoRA 很有价值,因为不同风格版本可以作为小文件保存、组合、切换、评审和回滚,而不必维护很多完整模型副本。
- 图像生成质量包含风格一致性、构图、身份保持、瑕疵和用户偏好。这些判断高度视觉化且带主观性,所以自动指标不像文本分类那样足够可靠。