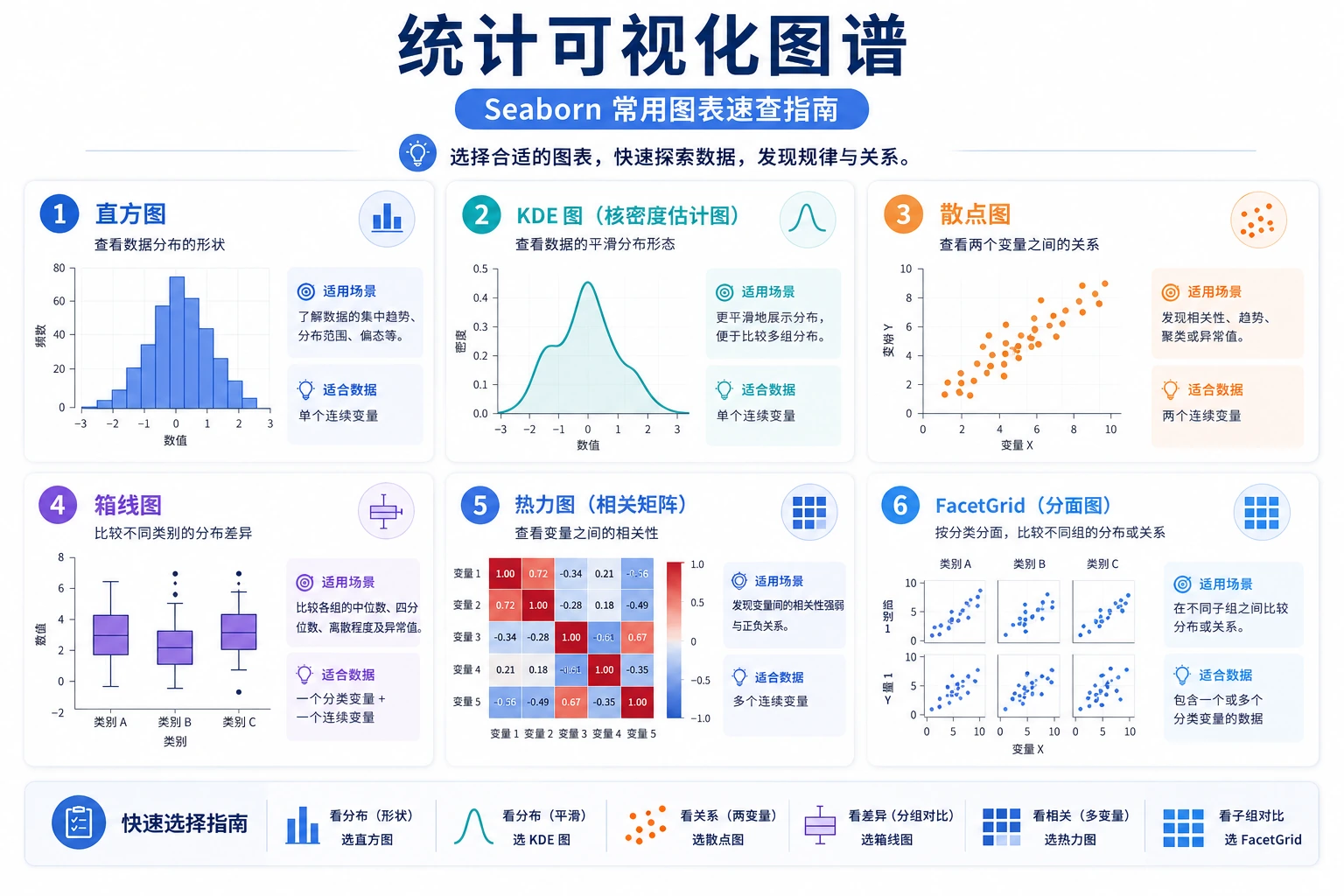
3.4.3 Seaborn 统计可视化
- 理解 Seaborn 与 Matplotlib 的关系
- 掌握分布图、关系图、分类图
- 学会绘制热力图与相关性矩阵
- 使用 FacetGrid 进行分面绑图
先建立一张地图
Section titled “先建立一张地图”Seaborn 最适合新人的理解顺序不是“函数表”,而是先看清它最擅长的 4 类问题:
flowchart LR A["分布"] --> B["histplot / kdeplot"] C["关系"] --> D["scatterplot / lineplot / pairplot"] E["分类比较"] --> F["boxplot / violinplot / barplot / countplot"] G["矩阵关系"] --> H["heatmap"]所以这节真正想解决的是:
- 当你在做 EDA 时,哪种图最适合先拿出来
- 为什么
Seaborn会比纯Matplotlib更适合快速探索
Seaborn 是什么?
Section titled “Seaborn 是什么?”如果把 Matplotlib 比作画笔和颜料,那 Seaborn 就是画笔套装 + 调色板 + 模板。
flowchart LR A["Matplotlib<br/>基础画笔"] -->|"Seaborn 封装"| B["Seaborn<br/>美观统计图表"] B -->|"底层仍是"| A C["Pandas<br/>DataFrame"] -->|"直接传入"| B
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style B fill:#e8f5e9,stroke:#2e7d32,color:#333 style C fill:#fff3e0,stroke:#e65100,color:#333| 对比 | Matplotlib | Seaborn |
|---|---|---|
| 定位 | 底层绑图库 | 高级统计绘图库 |
| 代码量 | 多,需要手动设置 | 少,开箱即用 |
| 默认美观度 | 一般 | 非常美观 |
| 数据格式 | 数组、列表 | 直接用 DataFrame |
| 统计功能 | 需要手动计算 | 自动计算均值、置信区间等 |
| 定制能力 | 极强 | 中等(可借助 Matplotlib 补充) |
一句话总结: Seaborn 让你用 1 行代码画出 Matplotlib 需要 10 行才能完成的美观统计图。
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把 Seaborn 理解成:
- 已经帮你摆好盘的数据可视化工具
Matplotlib 像你自己从锅碗瓢盆开始摆,
Seaborn 则像已经帮你配好餐具和默认风格,
你更容易把注意力放在:
- 这张图到底想看什么统计现象
# 安装# python -m pip install --upgrade seaborn
import seaborn as snsimport matplotlib.pyplot as pltimport pandas as pdimport numpy as np
# Seaborn 自带的示例数据集tips = sns.load_dataset("tips") # 餐厅小费数据iris = sns.load_dataset("iris") # 鸢尾花数据titanic = sns.load_dataset("titanic") # 泰坦尼克号数据
# 设置全局风格sns.set_theme(style="whitegrid") # 白底网格,清爽好看常用风格一览
Section titled “常用风格一览”| 风格 | 说明 | 适合场景 |
|---|---|---|
"whitegrid" | 白底 + 网格 | 数值对比(推荐默认) |
"darkgrid" | 灰底 + 网格 | 强调数据点 |
"white" | 纯白底 | 论文、报告 |
"dark" | 灰底 | 艺术风格 |
"ticks" | 白底 + 刻度线 | 简洁专业 |
分布图:数据长什么样?
Section titled “分布图:数据长什么样?”分布图帮你回答:这组数据的值集中在哪里?分散程度如何?是否有偏斜?
第一次做 EDA 时,最稳的默认顺序
Section titled “第一次做 EDA 时,最稳的默认顺序”更稳的顺序通常是:
- 先看分布图 先知道数据集中在哪、偏不偏。
- 再看关系图 看变量之间有没有明显关系。
- 再看分类图 看不同组之间差别大不大。
- 最后再看热力图 把整体相关性快速扫一遍。
这个顺序特别适合新人,因为它会让探索过程更有主线。
histplot:直方图
Section titled “histplot:直方图”fig, axes = plt.subplots(1, 3, figsize=(15, 4))
# 基本直方图sns.histplot(data=tips, x="total_bill", ax=axes[0])axes[0].set_title("基本直方图")
# 添加密度曲线sns.histplot(data=tips, x="total_bill", kde=True, ax=axes[1])axes[1].set_title("直方图 + 密度曲线")
# 按类别分颜色sns.histplot(data=tips, x="total_bill", hue="time", kde=True, ax=axes[2])axes[2].set_title("按用餐时间分组")
plt.tight_layout()plt.show()kdeplot:核密度估计
Section titled “kdeplot:核密度估计”fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# 一维密度sns.kdeplot(data=tips, x="total_bill", hue="sex", fill=True, ax=axes[0])axes[0].set_title("消费金额密度分布")
# 二维密度(等高线)sns.kdeplot(data=tips, x="total_bill", y="tip", fill=True, cmap="Blues", ax=axes[1])axes[1].set_title("消费 vs 小费 联合密度")
plt.tight_layout()plt.show()rugplot:地毯图
Section titled “rugplot:地毯图”fig, ax = plt.subplots(figsize=(8, 4))sns.kdeplot(data=tips, x="total_bill", fill=True, ax=ax)sns.rugplot(data=tips, x="total_bill", ax=ax, alpha=0.5)ax.set_title("密度曲线 + 地毯图(每条线代表一个数据点)")plt.show()关系图:变量之间有什么关系?
Section titled “关系图:变量之间有什么关系?”scatterplot:散点图
Section titled “scatterplot:散点图”fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 基本散点图,用颜色区分类别sns.scatterplot(data=tips, x="total_bill", y="tip", hue="time", ax=axes[0])axes[0].set_title("消费 vs 小费")
# 用大小和颜色同时表示信息sns.scatterplot(data=tips, x="total_bill", y="tip", hue="day", size="size", sizes=(20, 200), ax=axes[1])axes[1].set_title("多维度散点图")
plt.tight_layout()plt.show()lineplot:折线图(带置信区间)
Section titled “lineplot:折线图(带置信区间)”# 模拟实验数据:每个 x 有多个 y 值rng = np.random.default_rng(seed=42)data = pd.DataFrame({ "step": np.tile(np.arange(1, 51), 10), "accuracy": np.tile(np.linspace(0.5, 0.95, 50), 10) + rng.normal(0, 0.03, 500), "model": np.repeat(["模型 A", "模型 B"], 250)})
fig, ax = plt.subplots(figsize=(10, 5))sns.lineplot(data=data, x="step", y="accuracy", hue="model", ax=ax)ax.set_title("模型训练准确率变化(阴影 = 95% 置信区间)")plt.show()pairplot:变量两两关系一览
Section titled “pairplot:变量两两关系一览”# 鸢尾花数据集的所有变量关系sns.pairplot(iris, hue="species", diag_kind="kde", corner=True)plt.suptitle("鸢尾花数据集特征关系", y=1.02)plt.show()pairplot 一行代码就能展示所有变量之间的关系,是数据探索阶段的利器。
分类图:不同组有何差异?
Section titled “分类图:不同组有何差异?”分类图是 Seaborn 的强项,帮你比较不同类别之间的数据分布和统计量。
一个很适合初学者先记的选图表
Section titled “一个很适合初学者先记的选图表”| 你最想回答的问题 | 更稳的第一选择 |
|---|---|
| 这一列值大概怎么分布? | histplot |
| 两个变量有没有关系? | scatterplot |
| 两组或多组分布差很多吗? | boxplot / violinplot |
| 哪个类别样本更多? | countplot |
| 多个数值变量相关吗? | heatmap |
这张表会让新人少走很多弯路,因为你不用一开始就被函数名压住。
boxplot:箱线图
Section titled “boxplot:箱线图”fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# 基本箱线图sns.boxplot(data=tips, x="day", y="total_bill", ax=axes[0])axes[0].set_title("各日消费分布")
# 用颜色区分子类sns.boxplot(data=tips, x="day", y="total_bill", hue="sex", ax=axes[1])axes[1].set_title("各日消费分布(按性别)")
plt.tight_layout()plt.show()violinplot:小提琴图
Section titled “violinplot:小提琴图”fig, ax = plt.subplots(figsize=(10, 5))
sns.violinplot(data=tips, x="day", y="total_bill", hue="sex", split=True, inner="quart", ax=ax)ax.set_title("各日消费分布(小提琴图,左女右男)")
plt.show()小提琴图 = 箱线图 + 密度分布,比箱线图能看到更多分布形状。
barplot:均值柱状图(带误差线)
Section titled “barplot:均值柱状图(带误差线)”fig, ax = plt.subplots(figsize=(8, 5))
sns.barplot(data=tips, x="day", y="total_bill", hue="sex", ci=95, ax=ax) # ci=95 表示 95% 置信区间ax.set_title("各日平均消费(误差线 = 95% 置信区间)")
plt.show()countplot:计数图
Section titled “countplot:计数图”fig, axes = plt.subplots(1, 2, figsize=(12, 4))
# 简单计数sns.countplot(data=tips, x="day", order=["Thur", "Fri", "Sat", "Sun"], ax=axes[0])axes[0].set_title("各天就餐人次")
# 分组计数sns.countplot(data=titanic, x="class", hue="survived", ax=axes[1])axes[1].set_title("各舱位生存情况")
plt.tight_layout()plt.show()热力图(Heatmap)
Section titled “热力图(Heatmap)”热力图用颜色深浅表示数值大小,最常用于相关性矩阵。
绘制相关性矩阵
Section titled “绘制相关性矩阵”# 计算数值列的相关系数# 选取 tips 中的数值列numeric_cols = tips.select_dtypes(include="number")corr = numeric_cols.corr()
fig, ax = plt.subplots(figsize=(8, 6))sns.heatmap(corr, annot=True, fmt=".2f", cmap="RdBu_r", center=0, vmin=-1, vmax=1, square=True, linewidths=0.5, ax=ax)ax.set_title("小费数据集相关性矩阵")plt.tight_layout()plt.show()关键参数:
| 参数 | 作用 | 常用值 |
|---|---|---|
annot | 显示数值 | True |
fmt | 数值格式 | ".2f" 两位小数 |
cmap | 颜色映射 | "RdBu_r" 红蓝反转 |
center | 颜色中心值 | 0(相关系数) |
square | 正方形格子 | True |
自定义热力图
Section titled “自定义热力图”# 交叉表热力图(比如各天各时段的平均消费)pivot = tips.pivot_table(values="total_bill", index="day", columns="time", aggfunc="mean")
fig, ax = plt.subplots(figsize=(6, 4))sns.heatmap(pivot, annot=True, fmt=".1f", cmap="YlOrRd", linewidths=1, ax=ax)ax.set_title("各天各时段平均消费")plt.show()FacetGrid:分面绑图
Section titled “FacetGrid:分面绑图”当你想按某个变量把图表拆成多个子图时,用 FacetGrid。
# 按用餐时间分面,展示消费与小费的关系g = sns.FacetGrid(tips, col="time", row="sex", hue="smoker", height=4, aspect=1.2)g.map_dataframe(sns.scatterplot, x="total_bill", y="tip")g.add_legend()g.fig.suptitle("按时间和性别分面的消费-小费关系", y=1.02)plt.show()更多分面示例
Section titled “更多分面示例”# 按星期分面的直方图g = sns.FacetGrid(tips, col="day", col_wrap=2, height=3)g.map_dataframe(sns.histplot, x="total_bill", kde=True)g.set_titles("星期: {col_name}")g.fig.suptitle("各日消费分布", y=1.02)plt.show()| 参数 | 作用 |
|---|---|
col | 按此变量分列 |
row | 按此变量分行 |
hue | 按此变量分颜色 |
col_wrap | 每行最多几列(自动换行) |
height | 每个子图高度 |
aspect | 宽高比 |
为什么分面特别适合做探索?
Section titled “为什么分面特别适合做探索?”因为它能帮你把:
- “整体看起来还行”
拆成:
- 在不同类别、不同分组下到底哪里不一样
这对新人很重要,因为很多数据问题并不是整体分布能看出来的,而是:
- 一旦分组,就会暴露得很明显
Seaborn 常用图表速查
Section titled “Seaborn 常用图表速查” root(("Seaborn<br/>图表类型")) 分布图 histplot 直方图 kdeplot 密度曲线 rugplot 地毯图 关系图 scatterplot 散点图 lineplot 折线图 pairplot 变量矩阵 分类图 boxplot 箱线图 violinplot 小提琴图 barplot 均值柱状图 countplot 计数图 矩阵图 heatmap 热力图 多面板 FacetGrid 分面 pairplot 配对学完这一页,至少保留这张证据卡:
- 问题
- 这张图表回答的是比较、分布、趋势,还是关系
- 图表选择
- 折线图、柱状图、散点图、直方图、箱线图、热力图或交互式仪表板
- 工件
- 保存的图表图片/html 以及所用的数据切片
- 失败检查
- 尺度误导、图表过载、聚合错误或缺少标签
- 期望产出
- 带有一句说明洞察的图表成果
| 需求 | 函数 | 说明 |
|---|---|---|
| 查看分布 | histplot / kdeplot | 直方图 / 密度曲线 |
| 两变量关系 | scatterplot / lineplot | 散点图 / 折线图 |
| 所有变量关系 | pairplot | 一键矩阵图 |
| 类别间对比 | boxplot / violinplot / barplot | 分布 / 均值 |
| 类别计数 | countplot | 柱状图 |
| 数值矩阵 | heatmap | 热力图 |
| 分面展示 | FacetGrid | 多子图 |
核心优势: 一行代码就能画出美观且含统计信息的图表,直接传入 DataFrame 即可。
这节最该带走什么
Section titled “这节最该带走什么”Seaborn最重要的价值,不是更花哨,而是更适合快速做统计探索- 第一次做 EDA,先看分布,再看关系,再看分类比较,通常最稳
- 选图时先问“我想看什么统计现象”,比先背函数更重要
练习 1:探索数据分布
Section titled “练习 1:探索数据分布”# 加载 tips 数据集# 1. 用 histplot 画出 tip(小费)的分布,按 time 分颜色# 2. 用 kdeplot 画出 total_bill 的密度曲线,按 sex 分组练习 2:分类比较
Section titled “练习 2:分类比较”# 加载 titanic 数据集# 1. 用 boxplot 比较各舱位 (class) 的年龄 (age) 分布# 2. 用 countplot 展示各舱位的生存人数练习 3:相关性分析
Section titled “练习 3:相关性分析”# 加载 iris 数据集# 1. 计算数值列的相关系数矩阵# 2. 用 heatmap 可视化,添加数值标注# 3. 用 pairplot 查看所有变量关系练习 4:分面绑图
Section titled “练习 4:分面绑图”# 使用 tips 数据集# 用 FacetGrid 按 day 分面,画出 total_bill 和 tip 的散点图# 用颜色区分 sex参考实现与讲解
- 分布图可用
histplot或kdeplot,并说明偏态、异常值和大致中心。只有漂亮曲线、没有解释是不完整的。 - 类别比较中,箱线图和计数图回答的问题不同:一个看分布范围,一个看频数。先选符合问题的图,再做样式调整。
- 热力图和 pair plot 要解释一两个重要关系,并写一个限制。相关性或视觉聚类只是调查线索,本身不是证明。