6 深度学习与 Transformer 基础

第 6 章只解决一件事:理解模型怎样通过损失、梯度和反复训练步骤学会东西。
你在主线中的位置
Section titled “你在主线中的位置”你已经训练过 sklearn 模型,并用指标和错误样本判断过结果。这一章会打开训练循环:tensor 承载数据,模型产生预测,loss 衡量错误,反向传播计算梯度,优化器更新参数。
这是进入大模型前最后一个模型基础章节。目标不是先掌握所有架构再继续,而是把训练、shape、Attention 和 Transformer block 理解到足够程度,让第 7 章不再像魔法。
先看训练闭环
Section titled “先看训练闭环”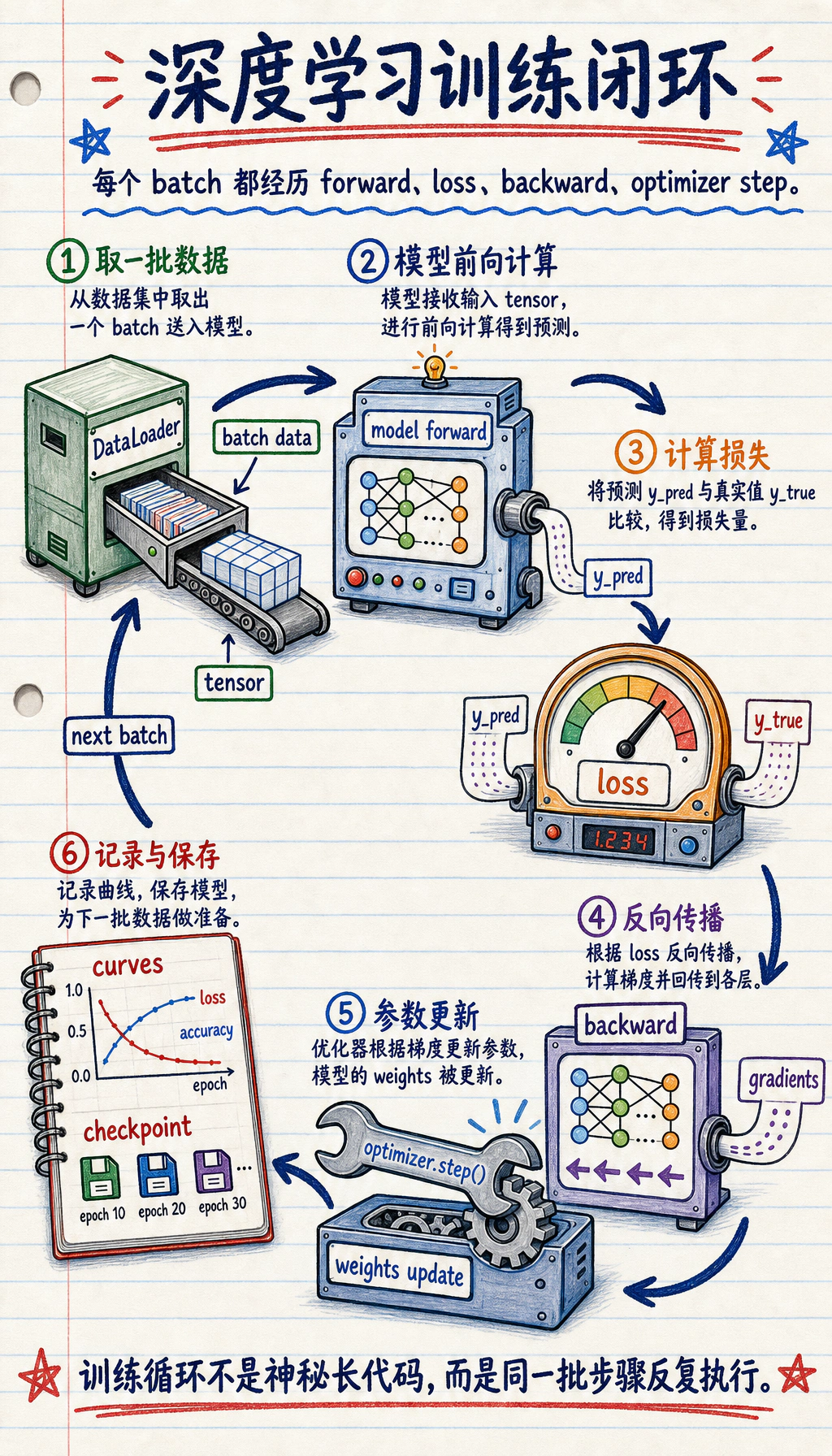
先看图。大多数深度学习训练代码都是这个闭环:
不要一开始追大模型。先让一个小模型跑起来,记录发生了什么,并解释它为什么变好或失败。
学习顺序与任务表
Section titled “学习顺序与任务表”这份清单同时作为本章学习指南和任务单。优先走核心路径:6.1 -> 6.2 -> 6.5 -> 6.8。CNN、RNN、生成模型和训练技巧作为扩展,在项目需要时再回来。
-
6.1 神经网络基础 跟着做:理解神经元、激活函数、前向/反向传播、优化器、正则化和初始化。 留下证据:一份手写训练闭环说明。
-
6.2 PyTorch 跟着做:练习 tensor、autograd、
nn.Module、Dataset、DataLoader 和最小训练循环。 留下证据:一个可运行 PyTorch 脚本。 -
6.5 Transformer 跟着做:学 Query、Key、Value、自注意力、位置编码和 Transformer block。 留下证据:一张 attention 输入/输出图。
-
6.8 项目 和 6.8.5 工作坊 跟着做:在图像、情感或生成项目之前,先做 PyTorch 证据包。 留下证据:日志、曲线、checkpoint、shape trace、README。
-
6.3 CNN 跟着做:用图像分类理解数据形状、卷积、池化和迁移学习。 留下证据:shape 记录和一次图像分类运行。
-
6.4 RNN 跟着做:理解序列数据为什么需要记忆,以及 LSTM/GRU 在 Transformer 前解决了什么。 留下证据:一条序列模型说明。
-
6.1.8 可选深度学习历史 跟着做:学完主训练闭环后,再浏览 backprop、CNN、RNN、Attention、Transformer 为什么出现。 留下证据:一条“这个架构为什么存在”的说明。
必修主线、扩展和深度挑战
Section titled “必修主线、扩展和深度挑战”| 层级 | 现在学什么 | 怎么使用 |
|---|---|---|
| 必修核心 | Tensor shape、autograd、nn.Module、Dataset/DataLoader、训练循环、验证曲线、Attention、Transformer | 这些会成为第 7 章理解 token、上下文和大模型行为的心智模型 |
| 可选扩展 | CNN、RNN、GAN/VAE、模型压缩、进阶调参 | 遇到图像、序列、生成或部署项目需要时再回来 |
| 深度挑战 | 故意过拟合一个极小 batch,再解释它证明了什么、不能证明什么 | 让后续训练失败更容易定位 |
本章常见术语:
| 术语 | 含义 |
|---|---|
tensor | PyTorch 使用的多维数组 |
forward | 数据经过模型得到预测 |
loss | 衡量预测错误的数字 |
backward | 从损失计算梯度 |
optimizer | 使用梯度更新参数 |
epoch | 完整看完一遍训练数据 |
batch | 一次一起处理的一小组样本 |
实验边界读法
Section titled “实验边界读法”本章有很多小实验。读实验时不要只问“输出对不对”,还要问它到底证明了什么、没有证明什么:
| 实验类型 | 它通常证明什么 | 它通常不能证明什么 |
|---|---|---|
| 单个数值或手算实验 | 机制方向是怎样流动的,例如梯度、gate、attention 权重 | 真实任务效果一定好 |
| shape 实验 | 输入、输出和中间 tensor contract 是否清楚 | 模型已经学到有用规律 |
| 玩具训练实验 | 训练闭环、loss、optimizer 和验证代码能跑通 | 方法一定适合真实数据 |
| baseline 对照实验 | 新模型是否至少超过简单规则 | 模型已经达到生产质量 |
| 诊断实验 | 某个失败信号如何被观察和定位 | 一次修改能解决所有问题 |
所以每次实验后都建议留一句:
这个实验想证明:这个实验还不能证明:下一步需要补的证据:第一个可运行闭环
Section titled “第一个可运行闭环”如果还没有 PyTorch,请先用官方选择器安装。PyTorch 可用后,运行下面这个极小训练循环:
import torchfrom torch import nn
torch.manual_seed(42)x = torch.tensor([[0.0], [1.0], [2.0], [3.0]])y = torch.tensor([[0.0], [2.0], [4.0], [6.0]])
model = nn.Linear(1, 1)loss_fn = nn.MSELoss()optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
for epoch in range(20): pred = model(x) loss = loss_fn(pred, y) optimizer.zero_grad() loss.backward() optimizer.step() if epoch in {0, 1, 5, 19}: print(epoch, round(loss.item(), 4))预期形态:
0 ...1 ...5 ...19 ...具体数字可能不同,但 loss 应该整体下降。只要下降,你就看到了训练闭环在工作。
进入后续内容前,先保留一条小的起点记录:
- 首次循环已运行
- 这个小型 PyTorch 循环打印了四行损失值
- loss 方向
- loss 总体下降
- 核心路径
- 6.1 → 6.2 → 6.5 → 6.8
- 下一步调试
- 如果 loss 不变化,检查形状、loss、梯度和优化器步进
这会把第一个例子变成检查点。你现在不是要立刻掌握所有架构,而是先证明训练循环已经不再是黑盒。
通往第 7 章的桥
Section titled “通往第 7 章的桥”进入大模型前,先确认下面这些连接是清楚的:
- 第 4 章的向量会变成 token embedding 和检索 embedding。
- 第 5 章的指标和错误样本会变成 Prompt 评估和 RAG 评估。
- 本章的 Attention 和 Transformer block 会变成从 token 到答案的路径。
- 训练会更新参数,而推理会使用训练好的参数生成输出。
| 层级 | 你能证明什么 |
|---|---|
| 最低通过 | 能按顺序说清 forward、loss、backward 和 optimizer step。 |
| 项目可用 | 能运行一个小 PyTorch 模型,观察 loss 变化,并解释 tensor shape。 |
| 深度检查 | 能故意把一个很小的 batch 过拟合,再解释为什么在训练更大模型前这个测试有用。 |
失败样本练习
Section titled “失败样本练习”离开本章前,保存一次失败或可疑的训练运行。用这个格式写:
run_id:symptom: shape mismatch、loss 不动、过拟合、OOM 或 attention 输出看不懂first_check:likely_cause:fix_attempt:result_after_fix:这样训练失败就变成可恢复的工程记录。目标不是避免所有错误,而是知道出错时先打印哪些证据。
| 现象 | 先检查什么 | 常见修复 |
|---|---|---|
| shape 不匹配 | 输入形状、batch 维度、输出类别数 | 在每层打印 tensor shape |
| loss 不下降 | 学习率、标签、归一化、损失函数 | 先尝试过拟合一个小 batch |
| 训练好、验证差 | 过拟合或数据划分问题 | 加验证曲线、数据增强、正则化、early stopping |
| 显存不足 | batch 大小、图像尺寸、模型规模 | 降低 batch/分辨率,或用更小模型 |
| Transformer 抽象 | Q/K/V 和序列长度 | 写代码前先画一张 attention 表 |
能回答下面五个问题,就可以进入第 7 章:
forward、loss.backward()、optimizer.step()分别做什么?- Dataset 和 DataLoader 分别解决什么问题?
- 训练曲线和验证曲线怎样暴露过拟合?
- Attention 为什么能建模上下文?
- Transformer 和后面的大模型有什么关系?
需要打印式清单时,打开 6.0 学习指南与任务单。后面的大模型、RAG 和多模态模型都会建立在这些表示学习概念上。