9.3.7 高级工具模式【选修】
- 理解缓存、重试、批量、复合工具等高级模式分别解决什么问题
- 理解“工具包装层”为什么重要
- 通过可运行示例看懂一个可组合工具执行器
- 建立工具层从“函数集合”走向“系统组件”的意识
为什么工具层也需要模式?
Section titled “为什么工具层也需要模式?”因为很多问题会重复出现
Section titled “因为很多问题会重复出现”例如:
- 每次调用都要记录日志
- 某些接口老超时,需要重试
- 同一查询一会儿就被问一次,适合缓存
- 某些任务总是“先搜再总结”
如果这些逻辑每个工具里都手写一遍, 系统会很快失控。
模式的价值不是“显得高级”
Section titled “模式的价值不是“显得高级””而是:
- 复用
- 一致性
- 降低重复工程
这和后端服务里的中间件思想很像。
一个类比:工具本体像电器,模式像插线板和稳压器
Section titled “一个类比:工具本体像电器,模式像插线板和稳压器”你买回来的电器当然能单独用, 但当设备越来越多, 你会自然加上:
- 插线板
- 稳压器
- 定时器
工具模式对 Agent 来说,也是在做类似的事情。
四种最常见的高级工具模式
Section titled “四种最常见的高级工具模式”适合:
- 临时性失败
- 上游接口偶发抖动
适合:
- 短时间内高频重复查询
- 只读类工具
适合:
- 一次问多个类似问题
- 一组相似请求合并处理
适合:
- 多个工具经常固定搭配使用
例如:
- 搜索文档 -> rerank -> 总结
这时与其每次都让 Agent 即兴组织, 不如封成一个更高层的复合工具。
先跑一个“可组合工具包装器”示例
Section titled “先跑一个“可组合工具包装器”示例”下面这个例子会做三件事:
- 给底层工具套上缓存
- 给工具套上重试
- 再组合成一个复合工具
from functools import wraps
def cache_tool(fn): cache = {}
@wraps(fn) def wrapper(*args): if args in cache: return {"source": "cache", "value": cache[args]} value = fn(*args) cache[args] = value return {"source": "tool", "value": value}
return wrapper
def retry_tool(fn, retries=2): @wraps(fn) def wrapper(*args): last_error = None for _ in range(retries + 1): try: return fn(*args) except Exception as e: last_error = str(e) return {"error": f"retry_failed:{last_error}"}
return wrapper
@cache_tooldef search_docs(keyword): docs = { "退款": "退款需满足 7 天内且学习进度低于 20%。", "证书": "完成所有必修项目并通过测试后可获得证书。", } return docs.get(keyword, "未找到相关文档")
def summarize(text): return f"总结:{text[:18]}..."
def search_and_summarize(keyword): doc = search_docs(keyword) if "error" in doc: return doc return { "keyword": keyword, "raw": doc, "summary": summarize(doc["value"]), }
print(search_and_summarize("退款"))print(search_and_summarize("退款"))预期输出:
{'keyword': '退款', 'raw': {'source': 'tool', 'value': '退款需满足 7 天内且学习进度低于 20%。'}, 'summary': '总结:退款需满足 7 天内且学习进度低于 ...'}{'keyword': '退款', 'raw': {'source': 'cache', 'value': '退款需满足 7 天内且学习进度低于 20%。'}, 'summary': '总结:退款需满足 7 天内且学习进度低于 ...'}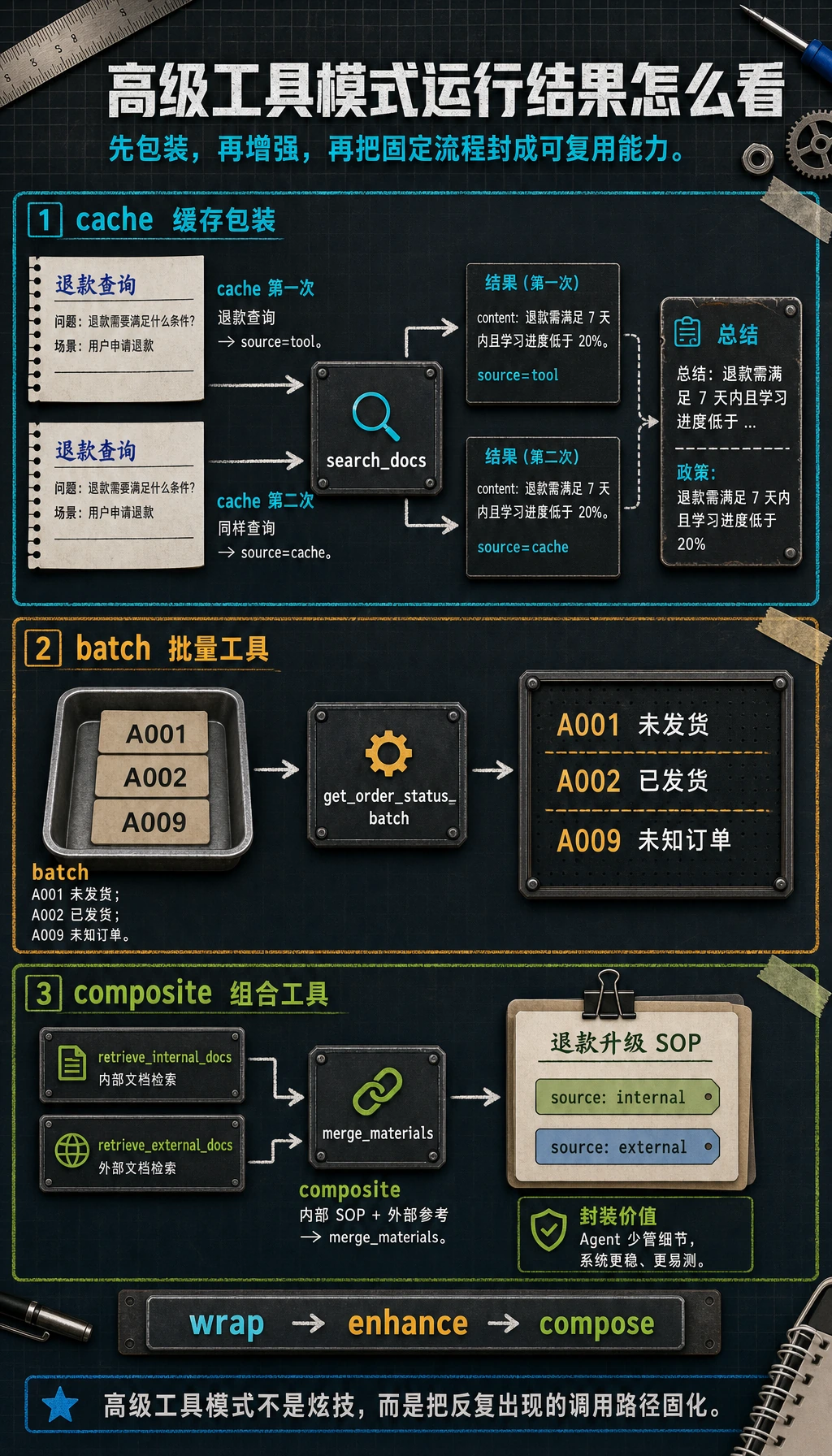
这段代码最值得学的是什么?
Section titled “这段代码最值得学的是什么?”它说明工具层不是只有“工具本体”。 实际系统里,你经常会先做:
- 包装
- 增强
- 组合
最终被 Agent 调用的, 常常是增强后的能力,而不只是原始函数。
为什么缓存适合只读工具?
Section titled “为什么缓存适合只读工具?”因为只读工具在短时间内重复调用时, 返回值往往不会立刻变。
例如:
- 查询退款政策
- 查询产品说明
这种工具做短时缓存,很容易显著降成本。
为什么“搜索 + 总结”适合封成复合工具?
Section titled “为什么“搜索 + 总结”适合封成复合工具?”因为它是高度固定的组合。 如果每次都让 Agent 自己想:
- 先搜
- 再总结
既慢又容易多一步少一步。
封装成复合工具后, 系统会更稳。
批量工具为什么重要?
Section titled “批量工具为什么重要?”因为很多请求本质上可以一起做
Section titled “因为很多请求本质上可以一起做”例如:
- 一次查 10 个订单状态
- 一次算一批价格
- 一次取一组文档摘要
如果逐条调用, 会浪费很多:
- 网络往返
- 模型步数
- 调度开销
一个最小批量工具示例
Section titled “一个最小批量工具示例”def get_order_status_batch(order_ids): mock_db = { "A001": "未发货", "A002": "已发货", "A003": "已签收", } return {order_id: mock_db.get(order_id, "未知订单") for order_id in order_ids}
print(get_order_status_batch(["A001", "A002", "A009"]))预期输出:
{'A001': '未发货', 'A002': '已发货', 'A009': '未知订单'}这类模式特别适合:
- 后端本身支持批量接口
- 单次调用成本不低
什么时候该把一串工具封成“高级工具”?
Section titled “什么时候该把一串工具封成“高级工具”?”当组合足够固定
Section titled “当组合足够固定”如果流程总是:
search -> rerank -> summarize
那就很适合做复合工具。
当你希望 Agent 少想一点细节
Section titled “当你希望 Agent 少想一点细节”Agent 的工作不应该永远停留在低级操作。 如果基础动作已经稳定, 封装成高层工具后,Agent 可以把注意力放在:
- 更高层决策
当你希望系统更稳、更快、更易测
Section titled “当你希望系统更稳、更快、更易测”复合工具通常更容易:
- 单元测试
- 观测
- 限流
因为边界更明确了。
如果你的目标是“知识库驱动的 SOP 文档助手”,哪些组合最值得先封装?
Section titled “如果你的目标是“知识库驱动的 SOP 文档助手”,哪些组合最值得先封装?”这类项目里,工具很容易自然长成下面这几类:
- 查内部资料
- 查外部资料
- 去重和重排
- 生成 SOP 结构约束
- 导出 Word
如果每一步都让 Agent 临场决定, 系统通常会出现:
- 顺序不稳定
- 一会儿漏查内部资料
- 一会儿先导出、后补内容
所以第一次做时,更值得先封装的,往往是这些高频固定流程:
| 复合工具 | 它在替你固定什么 |
|---|---|
retrieve_sop_materials | 先查内部 SOP,再补外部参考,再合并去重 |
build_sop_schema | 先抽政策规则、已处理案例和检查清单,再整理结构约束 |
export_sop_doc | 先校验 SOP 结构约束,再套模板导出 Word |
你可以先把它理解成:
把经常一起出现的动作,提前捆成一个稳定步骤。
一个更像真实项目的最小复合工具示例
Section titled “一个更像真实项目的最小复合工具示例”def retrieve_internal_docs(topic): return [{"source": "internal", "text": f"内部 SOP 证据:{topic} 的政策规则和已处理案例"}]
def retrieve_external_docs(topic): return [{"source": "external", "text": f"外部参考:{topic} 的补充最佳实践"}]
def merge_materials(internal_docs, external_docs): return internal_docs + external_docs
def retrieve_sop_materials(topic): internal_docs = retrieve_internal_docs(topic) external_docs = retrieve_external_docs(topic) return merge_materials(internal_docs, external_docs)
print(retrieve_sop_materials("退款升级 SOP"))预期输出:
[{'source': 'internal', 'text': '内部 SOP 证据:退款升级 SOP 的政策规则和已处理案例'}, {'source': 'external', 'text': '外部参考:退款升级 SOP 的补充最佳实践'}]这个示例最重要的价值不是代码多复杂, 而是让新人先看到:
- 高级工具模式不是“玄学设计”
- 而是在把项目里反复出现的流程固化下来
最常见的误区
Section titled “最常见的误区”误区一:高级模式就是“多写点装饰器”
Section titled “误区一:高级模式就是“多写点装饰器””不是。 关键不是写法炫, 而是它是否真的减少了重复问题。
误区二:有了缓存就一定更好
Section titled “误区二:有了缓存就一定更好”如果数据变化快, 缓存可能反而带来陈旧结果风险。
误区三:组合越多越说明系统强
Section titled “误区三:组合越多越说明系统强”过度封装也会让系统变僵硬。 关键看组合是否稳定、是否高频。
学完这一页,至少保留这张证据卡:
- 工具契约
- 名称、描述、输入 schema、输出 schema
- 权限
- 工具允许读取或修改的内容
- 调用轨迹
- 参数、结果、错误、重试或回退
- 失败检查
- 错误的工具、参数不当、不安全操作,或缺少观察结果
- 安全动作
- 验证、确认、沙箱、限流,或回滚
这节最重要的,不是记住几个模式名字, 而是建立一个更工程化的判断:
当工具越来越多、问题越来越重复时,工具层需要通过缓存、重试、批量和复合封装,从“函数集合”升级成一套可组合的能力系统。
这层意识建立起来后, 你后面做代码 Agent 和多工具系统时, 就不会只想着“再加一个函数”了。
- 给示例再加一个
timeout_tool包装器,思考它该放在哪一层。 - 为什么缓存更适合只读工具,而不适合高频变化的写操作?
- 想一个你做过的 Agent 任务,找出其中一个适合封成复合工具的固定流程。
- 如果一个工具组合不稳定、经常改顺序,你还会把它封成高级工具吗?为什么?
参考实现与讲解
timeout_toolwrapper 通常属于 executor 或 tool middleware 层,这样所有工具都能复用同一套超时行为。- cache 更适合只读工具,因为相同输入应得到相同且安全的答案。写操作会改变状态,缓存结果可能变危险。
- 退款检查流程、报告生成流程、文档入库流程,如果顺序稳定且可复现,就适合包装成 composite tool。
- 如果组合顺序经常变化,不应急着封装成 advanced tool。先保持步骤可见,等模式稳定、可测试后再封装。