2.2.4 函数式编程基础
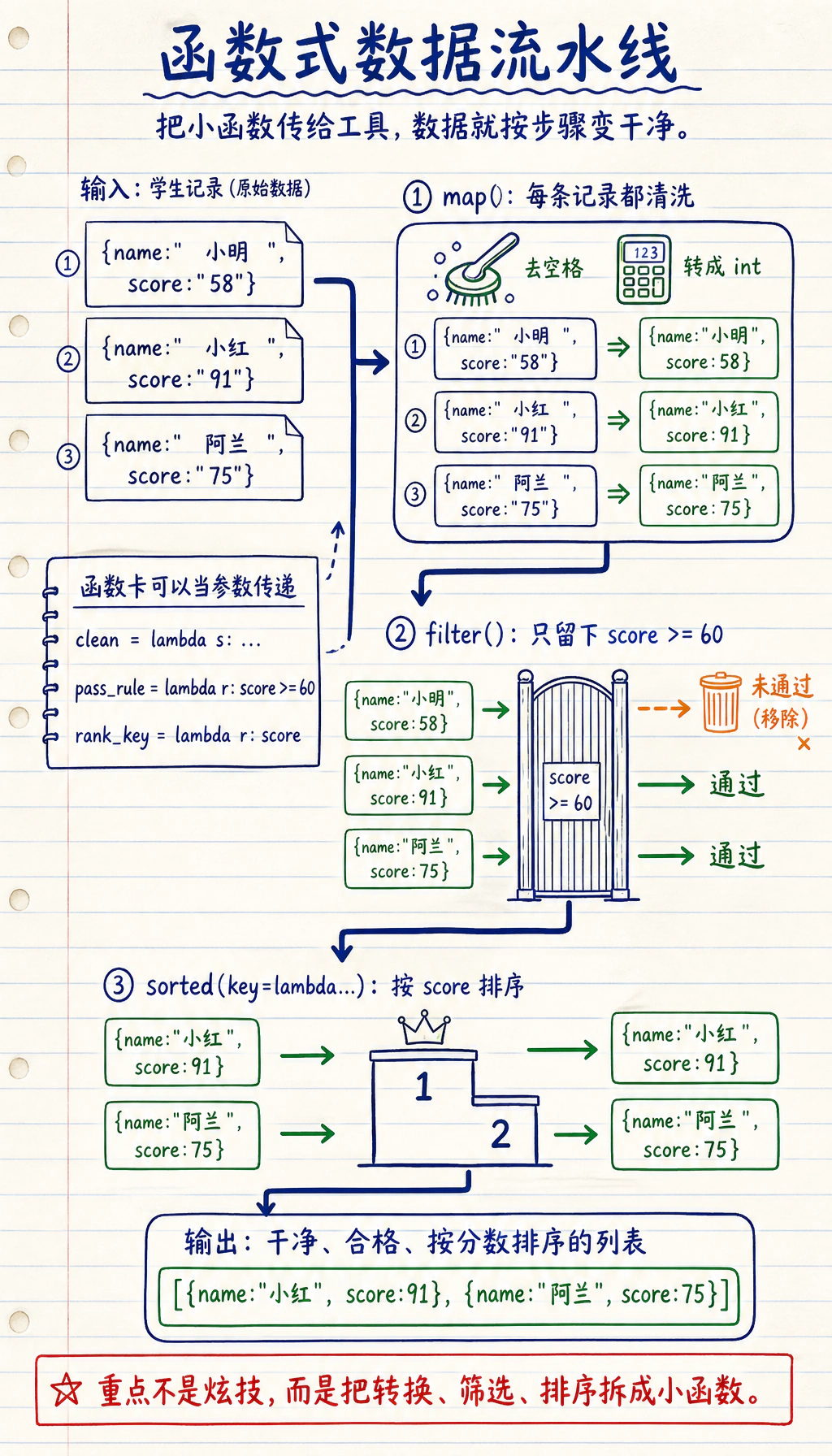
这一节补充 Python 中更灵活的函数用法。lambda、map、filter、sorted 的 key 参数和装饰器会经常出现在数据处理、框架源码和工具函数中,目标是能读懂并适度使用,而不是一开始就追求复杂技巧。
- 理解函数式编程的基本思想
- 掌握 lambda 匿名函数
- 熟练使用
map()、filter()、sorted()的 key 参数 - 理解闭包和装饰器的基本概念
第一遍不必追求“函数式很优雅”。你只需要知道它常用于批量转换、筛选、排序和给框架传入自定义逻辑。
什么是函数式编程?
Section titled “什么是函数式编程?”简单来说,函数式编程就是把函数当作数据来传递和使用。
在 Python 中,函数是一等公民——它和数字、字符串一样,可以:
- 赋值给变量
- 作为参数传给另一个函数
- 作为返回值返回
# 函数可以赋值给变量def greet(name): return f"你好,{name}!"
say_hi = greet # 把函数赋值给变量(注意没有括号)print(say_hi("小明")) # 你好,小明!
# 函数可以放进列表def add(a, b): return a + bdef sub(a, b): return a - bdef mul(a, b): return a * b
operations = [add, sub, mul]for op in operations: print(op(10, 3)) # 13, 7, 30Lambda 匿名函数
Section titled “Lambda 匿名函数”lambda 是一种一次性的小函数,不需要用 def 定义,也不需要名字。
# 普通函数def square(x): return x ** 2
# 等价的 lambdasquare = lambda x: x ** 2
print(square(5)) # 25语法:lambda 参数: 表达式
# 一个参数double = lambda x: x * 2print(double(5)) # 10
# 多个参数add = lambda a, b: a + bprint(add(3, 5)) # 8
# 带条件的size_label = lambda hours: "大型任务" if hours >= 8 else "小型任务"print(size_label(12)) # 大型任务print(size_label(3)) # 小型任务lambda 的主要用途
Section titled “lambda 的主要用途”lambda 最常见的用法是作为参数传给其他函数:
# 场景:按特定规则排序tasks = [ {"name": "登录 API", "hours": 8}, {"name": "RAG 演示", "hours": 12}, {"name": "图表视图", "hours": 5},]
# 按预估小时排序tasks.sort(key=lambda task: task["hours"])print([task["name"] for task in tasks]) # ['图表视图', '登录 API', 'RAG 演示']
# 按预估小时降序tasks.sort(key=lambda task: task["hours"], reverse=True)print([task["name"] for task in tasks]) # ['RAG 演示', '登录 API', '图表视图']map():对每个元素做同样的操作
Section titled “map():对每个元素做同样的操作”map(函数, 可迭代对象) 对序列中的每个元素应用函数,返回新的序列。
# 把列表中的每个数字平方numbers = [1, 2, 3, 4, 5]
# 方法 1:用 for 循环squares = []for n in numbers: squares.append(n ** 2)
# 方法 2:用 mapsquares = list(map(lambda x: x ** 2, numbers))print(squares) # [1, 4, 9, 16, 25]
# 方法 3:用列表推导式(通常更推荐)squares = [x ** 2 for x in numbers]print(squares) # [1, 4, 9, 16, 25]map() 实际应用
Section titled “map() 实际应用”# 批量转换数据类型str_numbers = ["10", "20", "30", "40"]numbers = list(map(int, str_numbers))print(numbers) # [10, 20, 30, 40]
# 批量处理字符串names = [" alice ", " BOB", "charlie "]clean_names = list(map(str.strip, names))print(clean_names) # ['alice', 'BOB', 'charlie']
# 使用已有函数temperatures_c = [0, 20, 37, 100]def c_to_f(c): return c * 9/5 + 32
temperatures_f = list(map(c_to_f, temperatures_c))print(temperatures_f) # [32.0, 68.0, 98.6, 212.0]filter():筛选满足条件的元素
Section titled “filter():筛选满足条件的元素”filter(函数, 可迭代对象) 保留函数返回 True 的元素。
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 筛选偶数evens = list(filter(lambda x: x % 2 == 0, numbers))print(evens) # [2, 4, 6, 8, 10]
# 等价的列表推导式evens = [x for x in numbers if x % 2 == 0]print(evens) # [2, 4, 6, 8, 10]filter() 实际应用
Section titled “filter() 实际应用”# 筛选较慢的响应latencies_ms = [45, 78, 55, 920, 880, 30, 67, 1000]slow = list(filter(lambda ms: ms >= 800, latencies_ms))print(f"较慢响应: {slow}") # [920, 880, 1000]
# 筛选非空字符串data = ["hello", "", "world", "", "python", ""]non_empty = list(filter(None, data)) # filter(None, ...) 过滤掉假值print(non_empty) # ['hello', 'world', 'python']
# 筛选特定类型的文件files = ["data.csv", "model.py", "readme.md", "train.py", "config.json"]py_files = list(filter(lambda f: f.endswith(".py"), files))print(py_files) # ['model.py', 'train.py']sorted() 的 key 参数
Section titled “sorted() 的 key 参数”sorted() 的 key 参数让你自定义排序规则:
# 按绝对值排序numbers = [-5, 3, -1, 4, -2]result = sorted(numbers, key=abs)print(result) # [-1, -2, 3, 4, -5]
# 按字符串长度排序words = ["python", "AI", "deep", "learning"]result = sorted(words, key=len)print(result) # ['AI', 'deep', 'python', 'learning']
# 按字典的某个键排序tasks = [ {"name": "登录 API", "owner_count": 2, "hours": 8}, {"name": "RAG 演示", "owner_count": 1, "hours": 12}, {"name": "图表视图", "owner_count": 1, "hours": 5},]
# 按预估小时排序by_hours = sorted(tasks, key=lambda task: task["hours"], reverse=True)for task in by_hours: print(f"{task['name']}: {task['hours']} 小时")# RAG 演示: 12 小时# 登录 API: 8 小时# 图表视图: 5 小时
# 按多个条件排序(先按优先级降序,优先级相同按预估小时升序)tasks2 = [ {"name": "A", "priority": 2, "hours": 8}, {"name": "B", "priority": 2, "hours": 5}, {"name": "C", "priority": 3, "hours": 12},]result = sorted(tasks2, key=lambda task: (-task["priority"], task["hours"]))for task in result: print(f"{task['name']}: priority={task['priority']}, hours={task['hours']}")# C: priority=3, hours=12# B: priority=2, hours=5# A: priority=2, hours=8闭包(Closure)
Section titled “闭包(Closure)”闭包是一个函数,它记住了外层函数的变量,即使外层函数已经执行完毕。
def make_multiplier(factor): """创建一个乘法器""" def multiplier(x): return x * factor # factor 来自外层函数 return multiplier
double = make_multiplier(2)triple = make_multiplier(3)
print(double(5)) # 10print(triple(5)) # 15print(double(10)) # 20闭包的实际应用
Section titled “闭包的实际应用”# 创建计数器def make_counter(start=0): count = [start] # 用列表包装,以便在内层函数中修改 def counter(): count[0] += 1 return count[0] return counter
counter = make_counter()print(counter()) # 1print(counter()) # 2print(counter()) # 3
# 创建带前缀的日志函数def make_logger(prefix): def log(message): from datetime import datetime timestamp = datetime.now().strftime("%H:%M:%S") print(f"[{prefix}] {timestamp} {message}") return log
info = make_logger("INFO")error = make_logger("ERROR")
info("程序启动") # [INFO] 14:30:01 程序启动error("文件未找到") # [ERROR] 14:30:01 文件未找到装饰器(Decorator)
Section titled “装饰器(Decorator)”装饰器是一种给函数添加额外功能的优雅方式,本质上就是闭包的应用。
假设你想给多个函数加上执行时间的统计:
import time
# 不用装饰器的做法:每个函数都要加计时代码def train_model(): start = time.time() # 这里模拟一次训练循环,真实项目里可以替换成模型训练代码 epochs = 3 for epoch in range(epochs): time.sleep(0.25) print(f"第 {epoch + 1}/{epochs} 轮:训练中...") time.sleep(1) end = time.time() print(f"train_model 耗时: {end - start:.2f}秒")
def process_data(): start = time.time() # 这里模拟一次数据预处理流程 records = ["原始1", "原始2", "原始3"] cleaned = [record.replace("原始", "清洗后") for record in records] print("清洗结果:", cleaned) time.sleep(0.5) end = time.time() print(f"process_data 耗时: {end - start:.2f}秒")每个函数都要重复写计时代码——太烦了!
装饰器解决方案
Section titled “装饰器解决方案”import time
def timer(func): """计时装饰器""" def wrapper(*args, **kwargs): start = time.time() result = func(*args, **kwargs) end = time.time() print(f"⏱ {func.__name__} 耗时: {end - start:.2f}秒") return result return wrapper
# 用 @ 语法使用装饰器@timerdef train_model(): """训练模型""" time.sleep(1) print("训练完成!")
@timerdef process_data(filename): """处理数据""" time.sleep(0.5) print(f"处理 {filename} 完成!")
train_model()# 训练完成!# ⏱ train_model 耗时: 1.00秒
process_data("data.csv")# 处理 data.csv 完成!# ⏱ process_data 耗时: 0.50秒@timer 等价于 train_model = timer(train_model)。
常用的装饰器模式
Section titled “常用的装饰器模式”# 重试装饰器def retry(max_attempts=3): def decorator(func): def wrapper(*args, **kwargs): for attempt in range(1, max_attempts + 1): try: return func(*args, **kwargs) except Exception as e: print(f"第 {attempt} 次尝试失败: {e}") if attempt == max_attempts: raise return wrapper return decorator
@retry(max_attempts=3)def risky_operation(): import random if random.random() < 0.7: raise ConnectionError("连接失败") return "成功!"map / filter vs 列表推导式
Section titled “map / filter vs 列表推导式”| 方式 | 适用场景 | 示例 |
|---|---|---|
| 列表推导式 | 大多数情况(推荐) | [x**2 for x in nums] |
map() | 已有函数可以直接用 | list(map(int, strings)) |
filter() | 配合已有判断函数 | list(filter(str.isdigit, items)) |
# 当已经有现成函数时,map 更简洁numbers = ["1", "2", "3"]list(map(int, numbers)) # 简洁[int(x) for x in numbers] # 也行,但稍长
# 当需要变换+条件时,列表推导式更清晰[x**2 for x in range(10) if x % 2 == 0]# 比 list(filter(lambda x: x%2==0, map(lambda x: x**2, range(10)))) 清晰得多练习 1:数据处理管道
Section titled “练习 1:数据处理管道”# 用 map 和 filter 处理以下数据raw_data = [" 23 ", "abc", "45.6", "", "78", "not_a_number", "90.1"]
# 1. 去除空白# 2. 过滤掉无法转换为数字的字符串# 3. 转换为浮点数# 4. 过滤掉小于 50 的数# 提示:可以结合使用 map、filter 和列表推导式练习 2:自定义排序
Section titled “练习 2:自定义排序”products = [ {"name": "笔记本", "price": 5999, "rating": 4.5}, {"name": "鼠标", "price": 199, "rating": 4.8}, {"name": "键盘", "price": 599, "rating": 4.2}, {"name": "显示器", "price": 2999, "rating": 4.7},]
# 1. 按价格从低到高排序# 2. 按评分从高到低排序# 3. 按性价比(rating/price)从高到低排序练习 3:写一个装饰器
Section titled “练习 3:写一个装饰器”写一个 @log 装饰器,在函数执行前后打印日志:
@logdef add(a, b): return a + b
add(3, 5)# 应该输出:# 调用 add,参数: (3, 5) {}# add 返回: 8参考实现与讲解
- 这个管道应该先去空白,再去掉空字符串和无法转成数字的内容,接着转换成浮点数,最后过滤掉小于 50 的值。样例里最终会留下
78和90.1。 - 排序可以分别用三次
sorted(..., key=...)完成:价格升序、评分降序、性价比(例如rating / price)降序。 - 装饰器应在函数执行前后打印消息,并原样返回函数结果。正式实现里最好加上
functools.wraps,保留原函数元数据。
学完这一页,至少保留这张证据卡:
- 模式
- 类、异常、文件 IO、函数式流水线、生成器或类型提示
- 代码产物
- 最小可运行示例和一个真实使用场景
- 输出
- 打印的对象状态、捕获的错误、保存的文件、yield 的值,或类型检查备注
- 失败检查
- 隐藏变异、吞掉异常、文件路径问题、懒迭代器混淆或误导性标注
- 期望产出
- 带调试说明的小型高级 Python 示例
| 概念 | 说明 | 示例 |
|---|---|---|
| lambda | 匿名函数 | lambda x: x * 2 |
| map() | 对每个元素应用函数 | map(int, ["1", "2"]) |
| filter() | 筛选满足条件的元素 | filter(lambda x: x>0, nums) |
| sorted(key=) | 自定义排序 | sorted(data, key=lambda x: x["hours"]) |
| 闭包 | 函数记住外层变量 | 工厂函数模式 |
| 装饰器 | 给函数添加额外功能 | @timer |