7.5.4 结构化输出
- 理解为什么结构化输出对 LLM 应用非常重要
- 学会设计一个简单但清晰的 JSON 输出格式
- 理解字段设计、约束说明和校验逻辑
- 看懂一个从 Prompt 到 JSON 解析的最小闭环
- 分清“结构化输出”和“函数调用”的区别与联系
一、为什么光有自然语言不够?
Section titled “一、为什么光有自然语言不够?”一个很常见的脆弱场景
Section titled “一个很常见的脆弱场景”假设你想让模型识别用户意图:
用户输入:
“我想了解退款政策”
如果模型返回:
“这个用户大概率是想问退款相关内容,建议转到退款模块。”
人当然能看懂。 但程序会很难稳定使用这段话。
因为程序更希望拿到的是:
{ "intent": "refund_policy", "confidence": 0.92}真正的问题是什么?
Section titled “真正的问题是什么?”问题不在于模型不会回答,而在于:
自然语言输出太自由,程序很难稳定消费。
所以当模型输出要继续传给:
- 前端
- 后端
- 工作流
- 数据库
时,结构化输出几乎就变成刚需。
二、结构化输出到底是什么?
Section titled “二、结构化输出到底是什么?”结构化输出 = 让模型按预先约定的字段和格式输出结果。
最常见格式包括:
- JSON
- 列表
- 表格
- 固定字段对象
为什么 JSON 最常见?
Section titled “为什么 JSON 最常见?”因为它同时满足:
- 人能读
- 程序能解析
- 结构清楚
所以在 LLM 应用里,JSON 通常是结构化输出的第一选择。
写结构约束前先理解几个术语
Section titled “写结构约束前先理解几个术语”| 术语 | 直白解释 | 实际作用 |
|---|---|---|
| JSON | 由对象、数组、字符串、数字、布尔值和 null 组成的轻量数据格式 | 让模型输出能被程序用 json.loads() 解析 |
| 结构约束 | 输出应有的形状,包括字段名、字段类型、可选值和必填字段 | 它是 Prompt 和下游程序之间的契约 |
| 字段(Field) | 一个有名字的数据项,例如 intent 或 confidence | 字段名稳定,后端代码才能不用猜就读取结果 |
| 校验 | 程序检查输出是否可解析、字段是否完整、类型是否正确 | 在坏输出破坏后续流程前拦住它 |
| 枚举(Enum) | 固定可选值集合,例如 refund_policy / certificate / other | 防止模型发明很多相似但不一致的标签 |
三、结构化输出最核心的设计点是什么?
Section titled “三、结构化输出最核心的设计点是什么?”字段要少而清楚
Section titled “字段要少而清楚”初学者很容易犯的错是:
- 一上来设计 20 个字段
- 但每个字段含义都不稳定
更好的原则是:
先用最少字段表达最关键结果。
例如意图识别:
{ "intent": "refund_policy", "confidence": 0.92}就已经够用了。
字段命名要稳定
Section titled “字段命名要稳定”如果今天叫:
intent
明天又叫:
user_intent
后天又叫:
task_type
那程序端会越来越混乱。
所以结构化输出的第一原则之一是:
字段名要稳定。
四、一个最小可运行示例:从字符串 JSON 到程序解析
Section titled “四、一个最小可运行示例:从字符串 JSON 到程序解析”先看最小解析
Section titled “先看最小解析”import json
text = '{"intent": "refund_policy", "confidence": 0.92}'data = json.loads(text)
print(data)print("intent =", data["intent"])print("confidence =", data["confidence"])预期输出:
{'intent': 'refund_policy', 'confidence': 0.92}intent = refund_policyconfidence = 0.92这段代码虽然简单,但意义很大
Section titled “这段代码虽然简单,但意义很大”它在教你:
- 结构化输出不是“看起来像 JSON”,而是要能被真正解析
- 解析后,程序就可以稳定取字段
也就是说,结构化输出的价值不在“更好看”,而在:
后续程序真的能用。
五、一个更贴近真实任务的小例子:用户意图识别
Section titled “五、一个更贴近真实任务的小例子:用户意图识别”假设你要求模型输出这个结构
Section titled “假设你要求模型输出这个结构”{ "intent": "refund_policy", "needs_human": false, "confidence": 0.92}模拟模型输出 + 程序解析
Section titled “模拟模型输出 + 程序解析”import json
mock_model_output = """{ "intent": "refund_policy", "needs_human": false, "confidence": 0.92}"""
data = json.loads(mock_model_output)
if data["intent"] == "refund_policy" and not data["needs_human"]: print("进入退款政策自动处理流程")else: print("转人工或进入其他流程")
print(data)预期输出:
进入退款政策自动处理流程{'intent': 'refund_policy', 'needs_human': False, 'confidence': 0.92}这就已经是结构化输出在真实工作流里的典型使用方式了。
六、Prompt 要怎么写,结构化输出才更稳?
Section titled “六、Prompt 要怎么写,结构化输出才更稳?”不要只说“请输出 JSON”
Section titled “不要只说“请输出 JSON””更稳妥的写法通常包括:
- 明确字段名
- 明确字段类型
- 明确只能输出 JSON
- 明确不要附加解释
例如:
请根据用户输入进行意图识别,并严格输出 JSON。
字段要求:- intent: string,可选值为 refund_policy / certificate / other- needs_human: boolean- confidence: float,范围 0 到 1
不要输出任何额外解释,只输出 JSON。为什么这会更稳?
Section titled “为什么这会更稳?”因为你不是只在“提需求”,而是在:
给模型定义输出合同。
合同越清楚,结果越稳。
七、为什么结构化输出仍然需要校验?
Section titled “七、为什么结构化输出仍然需要校验?”因为模型不是编译器
Section titled “因为模型不是编译器”即使你 prompt 写得很好,模型也可能:
- 漏字段
- 写错类型
- 多输出解释文字
- JSON 格式不闭合
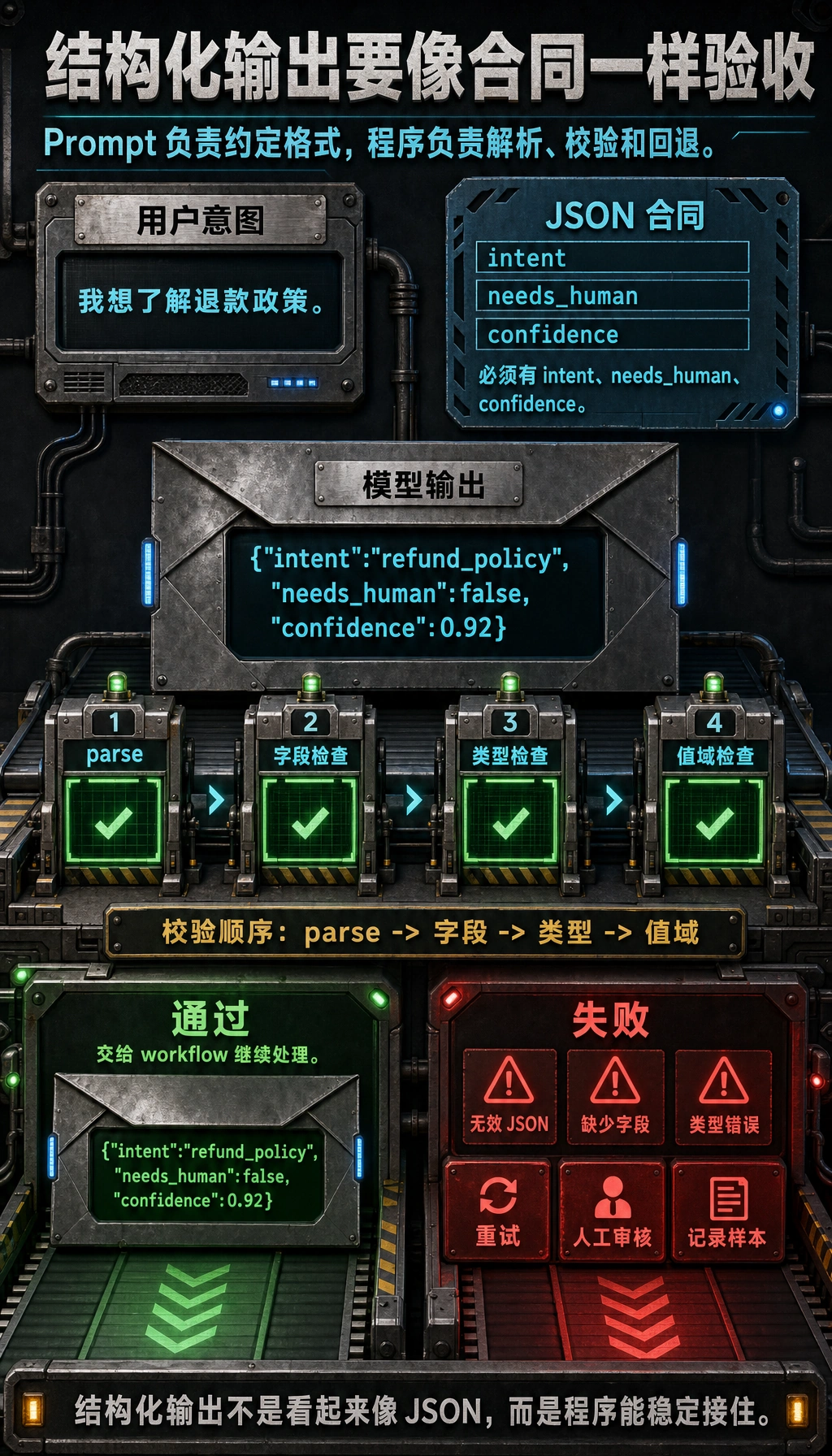
一个最小校验示例
Section titled “一个最小校验示例”import json
def validate_output(text): try: data = json.loads(text) except Exception: return False, "invalid_json"
required = ["intent", "needs_human", "confidence"] for field in required: if field not in data: return False, f"missing_{field}"
if not isinstance(data["intent"], str): return False, "intent_type_error" if not isinstance(data["needs_human"], bool): return False, "needs_human_type_error" if not isinstance(data["confidence"], (int, float)): return False, "confidence_type_error"
return True, data
good = '{"intent":"refund_policy","needs_human":false,"confidence":0.92}'bad = '{"intent":"refund_policy","confidence":"high"}'
print(validate_output(good))print(validate_output(bad))预期输出:
(True, {'intent': 'refund_policy', 'needs_human': False, 'confidence': 0.92})(False, 'missing_needs_human')
这一步特别重要,因为它让你的系统从:
- “模型大概会这么输出”
变成:
- “程序明确知道输出是否合格”
八、结构化输出和 函数调用 有什么关系?
Section titled “八、结构化输出和 函数调用 有什么关系?”它们都在做一件事:
把模型输出从自由文本,变成程序更容易接住的格式。
粗略地说:
- 结构化输出:更广泛,重点是“结果格式稳定”
- 函数调用(函数调用):更进一步,重点是“输出的是工具调用意图”
例如:
- 结构化输出:输出分类结果 JSON
- 函数调用(函数调用):输出
{name, arguments}去调工具
所以可以理解成:
函数调用 是结构化输出的一种更偏执行型形态。
九、如果你的目标是生成固定格式 Word / PPT,结构约束 应该怎么设计?
Section titled “九、如果你的目标是生成固定格式 Word / PPT,结构约束 应该怎么设计?”如果你的目标是:
- 生成支持工单复盘
- 生成发布评审报告
- 生成固定栏目文档
那结构化输出最重要的一步往往不是“叫模型输出 JSON”, 而是先把 schema 设计清楚。
一个适合事故复盘报告的最小 schema 往往会长这样:
{ "title": "密码重置事故复盘", "audience": "支持运营团队", "objective": ["定位根因", "定义后续行动"], "sections": [ {"type": "summary", "heading": "事故摘要", "items": ["09:10 到 09:40 之间用户无法收到重置邮件"]}, {"type": "evidence", "heading": "证据", "items": ["邮件队列延迟峰值达到 14 分钟"]}, {"type": "action", "heading": "后续行动", "items": ["增加队列延迟告警,并发布状态页更新模板"]} ], "source_refs": [{"doc_id": "incident_042", "page_or_slide": 3}]}这个 schema 最值得新人注意的地方是:
- 字段并不是越多越好
- 而是要刚好能驱动后面的模板渲染和来源回溯
十、真实项目里最常见的坑
Section titled “十、真实项目里最常见的坑”字段设计过多
Section titled “字段设计过多”字段越多,模型越容易错,后处理也越复杂。
字段含义不稳定
Section titled “字段含义不稳定”比如 confidence 有时写 0~1,有时写百分比,这种设计很危险。
不做解析与校验
Section titled “不做解析与校验”很多演示看起来能跑,但一接程序就崩,问题通常出在这里。
输出结构和业务流程脱节
Section titled “输出结构和业务流程脱节”如果 JSON 虽然完整,但不能直接驱动后续流程,那结构化输出就没有真正服务业务。
结构化输出验收表
Section titled “结构化输出验收表”结构化输出不是“看起来像 JSON”就算成功,而是要能被程序稳定消费。每次设计 schema 后,都可以用下面这张表验收。
| 检查项 | 合格表现 | 常见问题 |
|---|---|---|
| 可解析 | json.loads() 能直接解析 | 前后夹杂解释文字,JSON 不闭合 |
| 字段完整 | 必填字段全部存在 | 漏字段、字段名变体太多 |
| 类型正确 | string、boolean、number、array 等类型稳定 | confidence 有时是数字,有时是“高” |
| 枚举受控 | 分类字段只落在允许值内 | intent 输出一堆相近但不一致的词 |
| 业务可用 | 输出能直接驱动后续流程 | JSON 很完整,但后端不知道怎么用 |
| 失败可识别 | 程序能判断 invalid_json、missing_field、type_error | 所有失败都只显示“解析失败” |
如果这张表没过,优先修 schema 和校验逻辑,不要只反复改 Prompt 文案。
Prompt 版本管理为什么重要
Section titled “Prompt 版本管理为什么重要”当你开始优化结构化输出时,Prompt 本身也应该像代码一样有版本。否则你很难回答:到底是哪次修改让输出变好了,哪次修改引入了新问题。
| 字段 | 示例 | 作用 |
|---|---|---|
prompt_version | intent_schema_v2 | 标记当前提示词版本 |
change_reason | 增加 needs_human 字段 | 说明为什么改 |
test_inputs | 20 条固定输入 | 用同一批样本比较稳定性 |
pass_rate | 18/20 | 记录结构化输出通过率 |
failure_cases | 2 条缺字段 | 留下下一轮优化依据 |
一个简单记录可以写成:
版本:intent_schema_v2改动:增加 needs_human 字段,并要求 confidence 必须是 0 到 1 的数字评估:20 条测试输入,18 条通过解析与校验失败:2 条输出了 confidence="高"结论:保留字段,但需要在 prompt 中强调 confidence 类型这个习惯会让 Prompt 工程从“试试看”变成“有记录地迭代”。
结构化输出失败样本怎么记录
Section titled “结构化输出失败样本怎么记录”建议把失败样本按类型记录,而不是只说“模型没按格式输出”。
| 失败类型 | 示例 | 修复方向 |
|---|---|---|
invalid_json | 少了右括号 | 要求只输出 JSON,并增加解析失败重试 |
missing_field | 少了 needs_human | 在字段要求里标注必填项 |
type_error | confidence 输出成字符串 | 明确类型和范围 |
enum_error | intent 输出 refund 而不是 refund_policy | 给出可选值并禁止自造分类 |
extra_text | JSON 前后加解释 | 明确不要输出任何额外说明 |
失败样本越清楚,后续做回归测试就越容易。真实项目里,结构化输出的稳定性往往不是靠一次完美 Prompt,而是靠 schema、校验、失败记录和回归样本一起保证。
学完这一页,至少保留这张证据卡:
- 架构
- 必需字段和允许的类型
- 解析器
- 输出是被解析的,不能按视觉直读
- 有效样例
- 验证接受的一个输出
- 无效案例
- 缺少字段或类型错误被拒绝
- 修复规则
- 重试、降级处理,或请求澄清
这一节最重要的不是记住 JSON 语法,而是理解:
结构化输出的本质,是把模型回答变成程序可以稳定消费的中间结果。
当你开始把模型接进真实系统时,这往往比“回答写得更漂亮”更重要。
- 设计一个“课程问答路由”的 JSON 输出格式,至少包含
intent、confidence、needs_human三个字段。 - 故意构造一个缺字段的 JSON,看看校验器是否能拦住。
- 想一想:什么时候应该用结构化输出,什么时候直接自然语言就够了?
- 用自己的话解释:为什么说结构化输出是 Prompt 工程走向工程化的关键一步?
解题思路与讲解
- 一个合理 JSON 形状可以是
{"intent": "billing|course_help|technical_issue|other", "confidence": 0.0, "needs_human": false, "reason": "short explanation"}。 - 如果
intent、confidence或needs_human是必填字段,缺字段就应该校验失败。关键是让坏输出在进入产品逻辑前被拦住。 - 当另一个程序需要路由、存储、打分或触发动作时,应使用结构化输出。只给人阅读时,自然语言通常就够了。
- 结构化输出把 prompt 响应变成接口契约,因此 prompt 工作才可以被测试、自动化和维护。