8.3.9 模板化文档生成(Word / PPT)
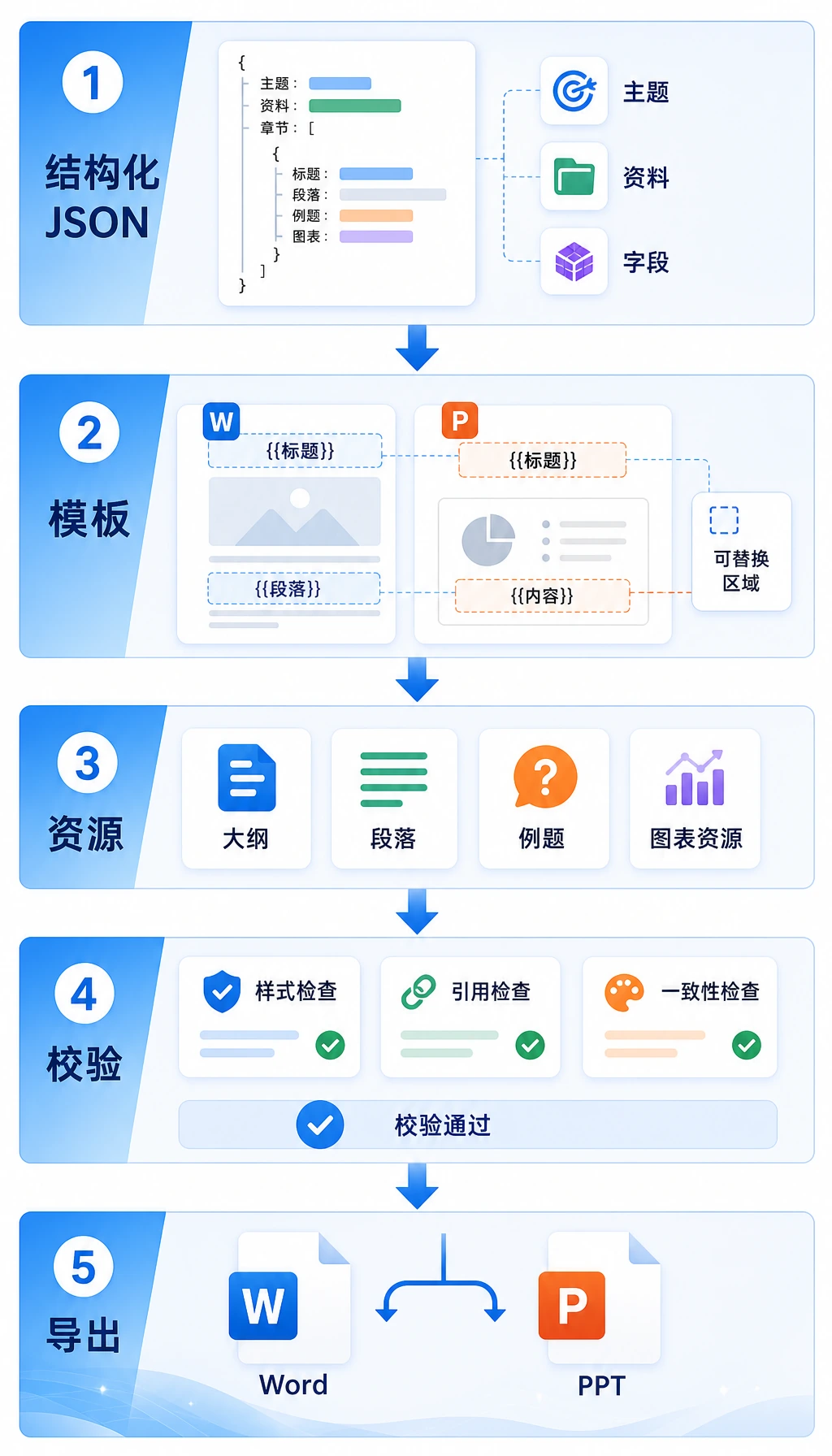
- 理解为什么文档生成最好走“结构 -> 模板 -> 导出”路线
- 理解 Word / PPT 生成和普通聊天输出的差别
- 看懂一个最小模板填充流程
- 建立“结构化输出先于文档排版”的工程直觉
先建立一张地图
Section titled “先建立一张地图”模板化文档生成更适合按“主题 -> 大纲 -> 内容块 -> 模板导出”来理解:
flowchart LR A["用户给主题"] --> B["生成结构化大纲"] B --> C["填入政策要点、案例、清单"] C --> D["套 Word / PPT 模板"] D --> E["导出文档"]所以这节真正想解决的是:
- 为什么不要让模型直接“自由写一整份 Word”
- 为什么固定模板会让生成结果更稳
为什么模板化这么重要?
Section titled “为什么模板化这么重要?”因为你的目标不是普通问答, 而是要交付:
- 像运营 SOP 或交接包的文档
这意味着系统不只要回答对, 还要满足:
- 结构稳定
- 栏目固定
- 标题级别固定
- 案例和复核步骤位置合理
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把文档生成理解成:
- 先写提纲,再填内容,最后排版
如果一上来直接写整篇正文, 很容易发生:
- 结构乱
- 内容重复
- 复核步骤跑到不该去的位置
所以更稳的方式通常是:
- 先定骨架
- 再填血肉
一个最小结构化文档对象示例
Section titled “一个最小结构化文档对象示例”doc_spec = { "title": "退款升级 SOP", "target_audience": "支持运营团队", "sections": [ { "heading": "一、政策摘要", "content_type": "policy", "items": ["当退款资格或支付状态不明确时,升级给专人复核"], }, { "heading": "二、案例处理", "content_type": "case", "items": ["客户使用银行卡支付且订单超过 7 天,承诺退款前先转交计费复核"], }, { "heading": "三、复核清单", "content_type": "checklist", "items": ["检查订单时间、支付状态、使用证据和历史工单记录"], }, ],}
print(doc_spec)预期输出:
{'title': '退款升级 SOP', 'target_audience': '支持运营团队', 'sections': [{'heading': '一、政策摘要', 'content_type': 'policy', 'items': ['当退款资格或支付状态不明确时,升级给专人复核']}, {'heading': '二、案例处理', 'content_type': 'case', 'items': ['客户使用银行卡支付且订单超过 7 天,承诺退款前先转交计费复核']}, {'heading': '三、复核清单', 'content_type': 'checklist', 'items': ['检查订单时间、支付状态、使用证据和历史工单记录']}]}这个例子最重要的价值是:
- 先把“要生成什么结构”说清楚
也就是说,模型不应该直接输出最终 .docx,
而应该先输出一份结构化内容对象。
一个更适合真实项目的文档结构约束
Section titled “一个更适合真实项目的文档结构约束”如果你的目标是“生成符合固定格式的 Word SOP 或交接文档”, 建议在最小对象上再多补两层:
- 页面级或章节级顺序
- 模板字段级映射
一个更稳的文档 schema 往往至少包含:
| 字段 | 用途 |
|---|---|
title | 文档标题 |
audience | 适用对象 |
document_goal | 文档目标 |
sections | 正文结构 |
source_refs | 引用来源 |
template_version | 用的是哪个模板 |
这张表特别适合新人,因为它会提醒你:
- 你不是在生成“长文本”
- 你是在生成“可被模板稳定消费的数据对象”
一个最小模板填充示例
Section titled “一个最小模板填充示例”下面这个例子不用真实 python-docx,
先用最简单的字符串模板讲清楚工作流。
template = """# {title}
适用对象:{target_audience}
{body}"""
def render_body(sections): blocks = [] for section in sections: blocks.append(section["heading"]) for item in section["items"]: blocks.append(f"- {item}") blocks.append("") return "\n".join(blocks)
result = template.format( title=doc_spec["title"], target_audience=doc_spec["target_audience"], body=render_body(doc_spec["sections"]),)
print(result)预期输出:
# 退款升级 SOP
适用对象:支持运营团队
一、政策摘要- 当退款资格或支付状态不明确时,升级给专人复核
二、案例处理- 客户使用银行卡支付且订单超过 7 天,承诺退款前先转交计费复核
三、复核清单- 检查订单时间、支付状态、使用证据和历史工单记录这个例子特别适合初学者,因为它会帮助你先看到:
- 模板化的核心不是库
- 而是“先有结构,再套模板”
模板字段应该怎么设计?
Section titled “模板字段应该怎么设计?”第一次做这类系统时,特别推荐先把模板字段明写出来。
| 模板字段 | 对应内容 |
|---|---|
{title} | 文档标题 |
{target_audience} | 适用对象 |
{document_goal} | 文档目标 |
{policy_block} | 政策摘要 |
{case_block} | 案例处理 |
{checklist_block} | 复核清单 |
{source_block} | 来源说明 |
它的好处是:
- 模型知道自己要产什么
- 模板渲染层知道自己要填什么
- 你后面改版时也知道是哪一层出了问题
Word / PPT 真正要额外处理什么?
Section titled “Word / PPT 真正要额外处理什么?”在真实工程里,除了正文内容,你还会处理:
- 标题样式
- 段落层级
- 编号
- 表格
- 图片位置槽
- 页眉页脚
- 幻灯片页布局
所以模板化文档生成其实是两层问题:
- 内容结构
- 文档排版
一个最小“结构对象 -> 模板字段”示例
Section titled “一个最小“结构对象 -> 模板字段”示例”def to_template_payload(doc_spec): blocks = {"policy": [], "case": [], "checklist": []} for section in doc_spec["sections"]: blocks[section["content_type"]].extend(section["items"])
return { "title": doc_spec["title"], "target_audience": doc_spec["target_audience"], "document_goal": "在导出前统一退款升级判断", "policy_block": "\n".join(f"- {x}" for x in blocks["policy"]), "case_block": "\n".join(f"- {x}" for x in blocks["case"]), "checklist_block": "\n".join(f"- {x}" for x in blocks["checklist"]), "source_block": "来源:退款政策知识库 + 计费升级 SOP", }
payload = to_template_payload(doc_spec)print(payload)预期输出:
{'title': '退款升级 SOP', 'target_audience': '支持运营团队', 'document_goal': '在导出前统一退款升级判断', 'policy_block': '- 当退款资格或支付状态不明确时,升级给专人复核', 'case_block': '- 客户使用银行卡支付且订单超过 7 天,承诺退款前先转交计费复核', 'checklist_block': '- 检查订单时间、支付状态、使用证据和历史工单记录', 'source_block': '来源:退款政策知识库 + 计费升级 SOP'}这个小例子最值得新人注意的是:
- 结构对象不一定等于模板对象
- 中间往往还会有一层“字段整理”
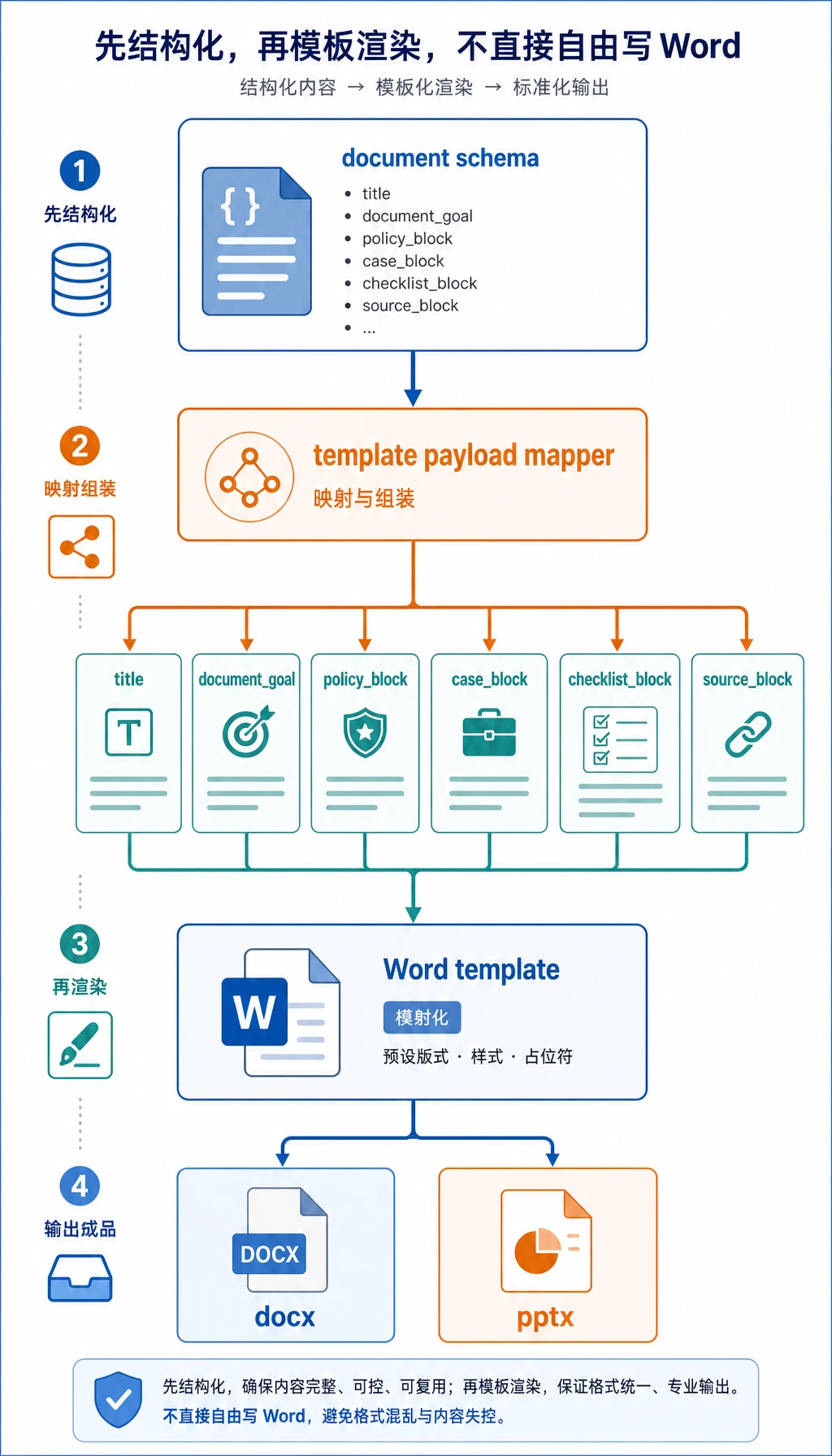
动手做:渲染前先校验模板字段
Section titled “动手做:渲染前先校验模板字段”在把数据交给 python-docx、docxtpl 或 python-pptx 之前,先检查 template payload 是否包含所有必填字段。这样可以避免导出后才发现 Word 文档有一半是空的。
REQUIRED_FIELDS = [ "title", "target_audience", "document_goal", "policy_block", "case_block", "checklist_block", "source_block",]
def validate_payload(payload): missing = [field for field in REQUIRED_FIELDS if not payload.get(field)] if missing: return False, f"缺少字段:{missing}" return True, "ok"
def render_markdown_handout(payload): ok, message = validate_payload(payload) if not ok: raise ValueError(message)
return f"""# {payload['title']}
适用对象:{payload['target_audience']}文档目标:{payload['document_goal']}
## 政策摘要{payload['policy_block']}
## 案例处理{payload['case_block']}
## 复核清单{payload['checklist_block']}
## 来源说明{payload['source_block']}"""
payload = { "title": "退款升级 SOP", "target_audience": "支持运营团队", "document_goal": "在导出前统一退款升级判断", "policy_block": "- 当退款资格或支付状态不明确时,升级给专人复核", "case_block": "- 客户使用银行卡支付且订单超过 7 天,承诺退款前先转交计费复核", "checklist_block": "- 检查订单时间、支付状态、使用证据和历史工单记录", "source_block": "来源:退款政策知识库 + 计费升级 SOP",}
print(validate_payload(payload))print(render_markdown_handout(payload))预期输出:
(True, 'ok')# 退款升级 SOP
适用对象:支持运营团队文档目标:在导出前统一退款升级判断
## 政策摘要- 当退款资格或支付状态不明确时,升级给专人复核
## 案例处理- 客户使用银行卡支付且订单超过 7 天,承诺退款前先转交计费复核
## 复核清单- 检查订单时间、支付状态、使用证据和历史工单记录
## 来源说明来源:退款政策知识库 + 计费升级 SOP
这个检查很简单,但它体现了演示和工程管线的区别:每个渲染步骤都应该在缺少必填结构字段时尽早失败。
解题思路与讲解
正确的第一层检查是:完整 payload 应该让 validate_payload(payload) 返回 (True, "ok");如果某个必填字段为空或缺失,渲染前就应该给出清晰错误,而不是生成一份半空的讲义。
一个稳的实现会拆成三层职责:
- document schema 决定有哪些政策要点、案例、清单和来源。
- template payload 把这些字段整理成模板真正需要的占位符。
- renderer 只负责格式化已经校验过的 payload。
如果你删掉 checklist_block,预期结果不应该是一份损坏的导出文档。校验层应该返回缺失字段信息,调用方应该在导出前停止。
为什么这一层和 Prompt / 结构化输出强相关?
Section titled “为什么这一层和 Prompt / 结构化输出强相关?”因为你通常会让模型先产出:
- JSON
- 大纲
- 标题列表
- 每节的政策要点 / 案例 / 清单
而不是直接产出一份“自由散文式”长文档。
这部分最相关的已有课程是:
第一次做这个模块时,最稳的范围控制
Section titled “第一次做这个模块时,最稳的范围控制”第一次做时,最稳的范围通常是:
- 先只生成
Word - 先只支持一种模板
- 先不加图片自动布局
- 先不做复杂样式切换
这样更容易先证明:
- 结构对象稳定
- 模板字段稳定
- 导出链路稳定
一个新人可直接照抄的生成顺序
Section titled “一个新人可直接照抄的生成顺序”第一次做这种系统时,更稳的顺序通常是:
- 先定义文档结构
- 先生成结构化 JSON / 大纲
- 再填政策要点和案例
- 最后再导出 Word / PPT
这样会比一上来直接生成 .docx 内容稳定很多。
实际工程里会用到哪些库?
Section titled “实际工程里会用到哪些库?”这部分当前课程里还没有展开到具体库使用层, 但你做项目时大概率会接触:
python-docxdocxtplpython-pptx
所以这节可以看成是:
- 先把思路讲顺
- 具体库再去查官方文档
如果把它做成项目,最值得展示什么?
Section titled “如果把它做成项目,最值得展示什么?”最值得展示的通常不是:
- “我们能导出 Word”
而是:
- 结构化内容对象长什么样
- 模板长什么样
- 最终 Word / PPT 和结构之间是怎么对应的
- 哪些格式要求是稳定可控的
这样别人会更容易看出:
- 你理解的是模板化生成
- 不只是“让模型写长文”
模板生成失败样本长什么样?
Section titled “模板生成失败样本长什么样?”模板化生成最怕的是“导出了文件,但内容和结构已经不可信”。建议至少保存这些失败样本:
| 失败样本 | 现象 | 优先修复 |
|---|---|---|
| 字段缺失 | Word 里出现空章节或 {policy_block} 未替换 | 渲染前做 required fields 校验 |
| 顺序错位 | 案例内容跑到政策摘要下面 | 固定 section schema 和模板映射 |
| 来源丢失 | 文档有结论,但没有 source refs | 要求结构对象携带引用字段 |
| 内容过长 | 一页 PPT 被模型塞成大段文字 | 给每个字段设长度或条目数限制 |
| 风格漂移 | 同类文档每次标题和栏目都不同 | 固定 template_version 和栏目名 |
这些失败样本能把问题拆开:是模型生成结构错了,还是模板字段映射错了,或者渲染层缺少校验。
学完这一页,至少保留这张证据卡:
- 请求
- 输入、状态、工具/上下文,以及期望输出契约
- 已验证输出
- parser / schema 或业务规则检查的结果
- 追踪记录
- 模型调用、tool/function 调用、文档解析或对话状态
- 失败检查
- 格式无效、字段缺失、状态过时或工具错误
- 下一步动作
- Prompt、schema、状态、API 或解析改进
- 模板化文档生成最关键的是先定义稳定 结构约束,再定义模板字段
- “结构对象 -> 字段整理 -> 模板渲染” 这三层分开后,系统会稳很多
- 第一次做时,先把单模板 Word 导出跑顺,比同时做 Word 和 PPT 更稳
这节最该带走什么
Section titled “这节最该带走什么”- 文档生成最稳的路线通常是“结构化输出 -> 模板渲染 -> 文档导出”
- 先定结构,再填内容,比直接让模型自由写整份交接文档稳得多
- 如果你的目标是生成 Word / 运营文档,这一层是项目成败的关键环节