5.4.1 评估路线图:调参之前先相信分数
模型评估回答一个问题:模型真的好,还是分数只是碰巧好看?
先看评估地图
Section titled “先看评估地图”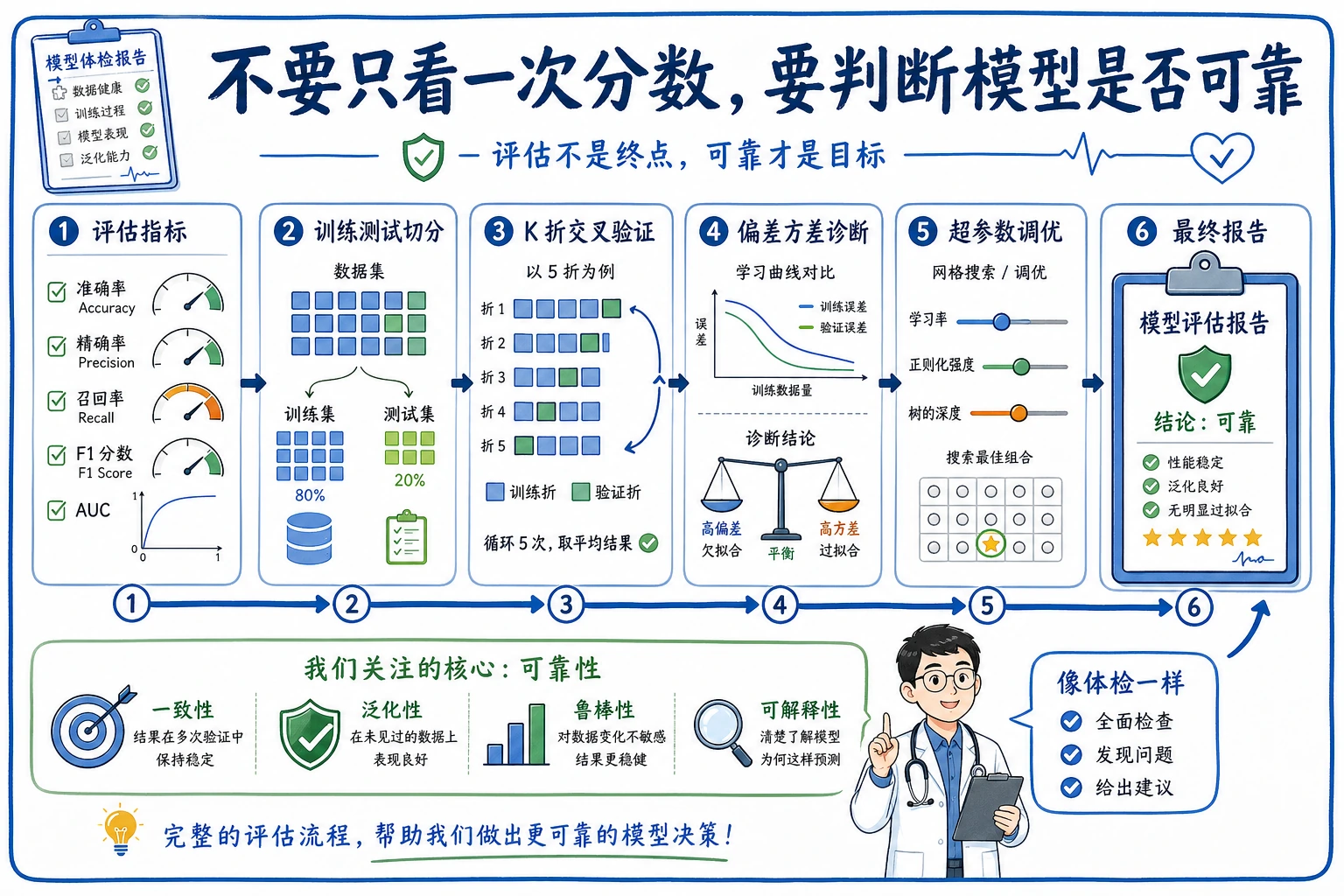
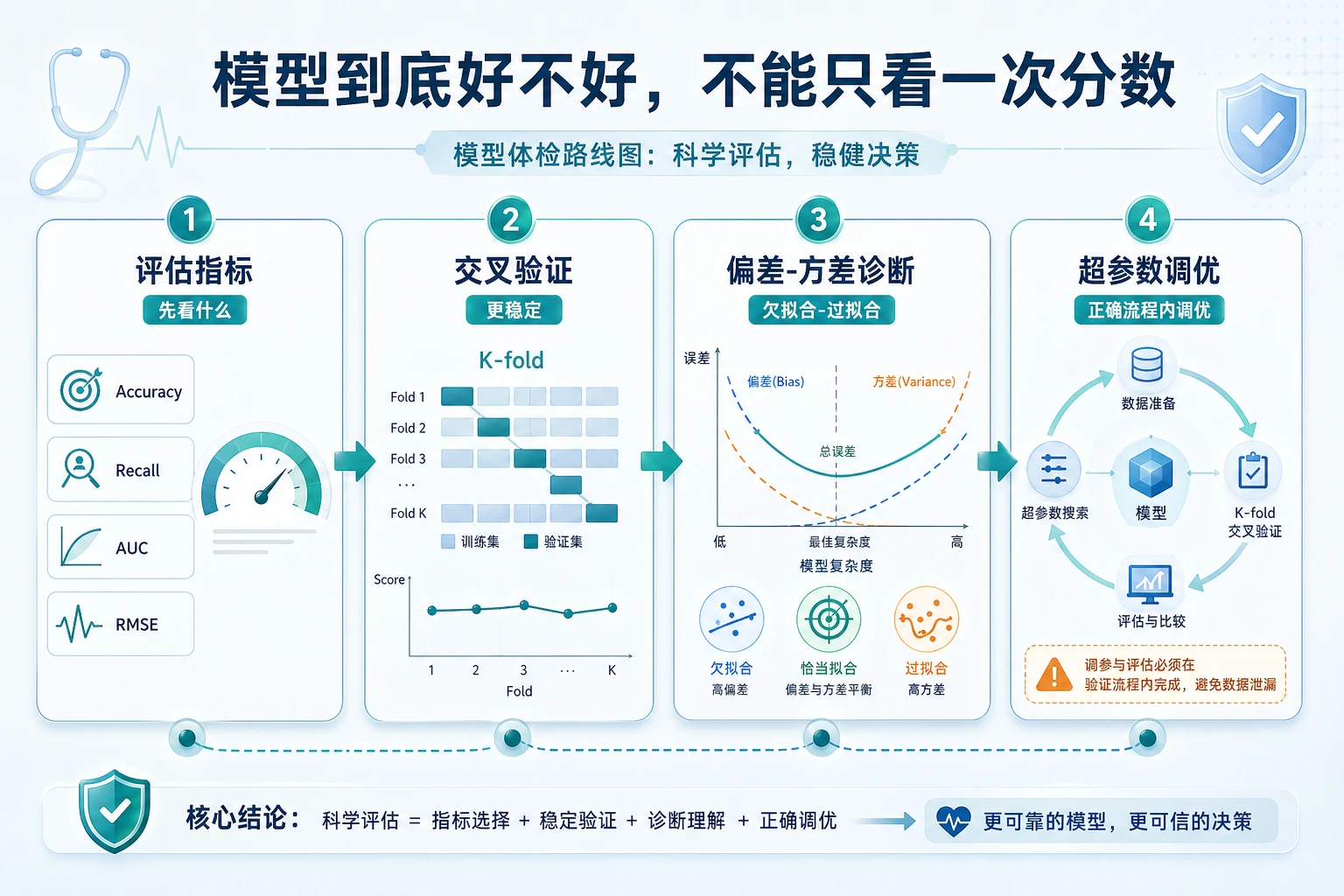
| 主题 | 先问的问题 |
|---|---|
| 指标 | 哪个分数匹配这个任务? |
| 交叉验证 | 分数在不同划分下稳定吗? |
| 偏差方差 | 模型太简单还是太灵活? |
| 调参 | 哪个参数变化真的更好? |
跑一次交叉验证检查
Section titled “跑一次交叉验证检查”创建 evaluation_first_loop.py,安装 scikit-learn 后运行。
from sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_scorefrom sklearn.tree import DecisionTreeClassifier
X, y = load_iris(return_X_y=True)model = DecisionTreeClassifier(max_depth=2, random_state=42)scores = cross_val_score(model, X, y, cv=5)
print("fold_scores:", [float(round(score, 3)) for score in scores])print("mean_accuracy:", round(scores.mean(), 3))预期输出:
fold_scores: [0.933, 0.967, 0.9, 0.867, 1.0]mean_accuracy: 0.933一个分数只是快照,多折结果能告诉你这个结果是否稳定到值得相信。
按这个顺序学
Section titled “按这个顺序学”| 顺序 | 阅读 | 练什么 |
|---|---|---|
| 1 | 5.4.2 评估指标 | accuracy、precision、recall、F1、R2、RMSE |
| 2 | 5.4.3 交叉验证 | 稳定估计、数据划分风险 |
| 3 | 5.4.4 偏差与方差 | 欠拟合、过拟合、学习曲线 |
| 4 | 5.4.5 超参数调优 | 网格搜索、对比记录 |
能为任务选择指标,解释一次分数稳定性检查,并避免在评估方法不可信时急着调参,就算通过。
检查思路与讲解
- 先根据任务目标和错误代价选择指标,再开始调参。
- 交叉验证回答的是分数在不同划分下是否稳定;一次幸运划分不能当作充分证据。
- 不要在最终测试集上调参。对比记录应写清 baseline、指标、验证方式、结果和下一步决策。
学完这一页,至少保留这张证据卡:
- 评估设置
- 划分、交叉验证、指标、基线和对比目标
- 结果
- 分数表、曲线、混淆矩阵、验证结果,或搜索结果
- 决策
- 是否更改数据、特征、模型、阈值或超参数
- 失败检查
- 泄漏、验证不稳定、指标错误或在测试集上调参
- 期望产出
- 支持下一步建模决策的评估记录