11.2.4 语言模型基础
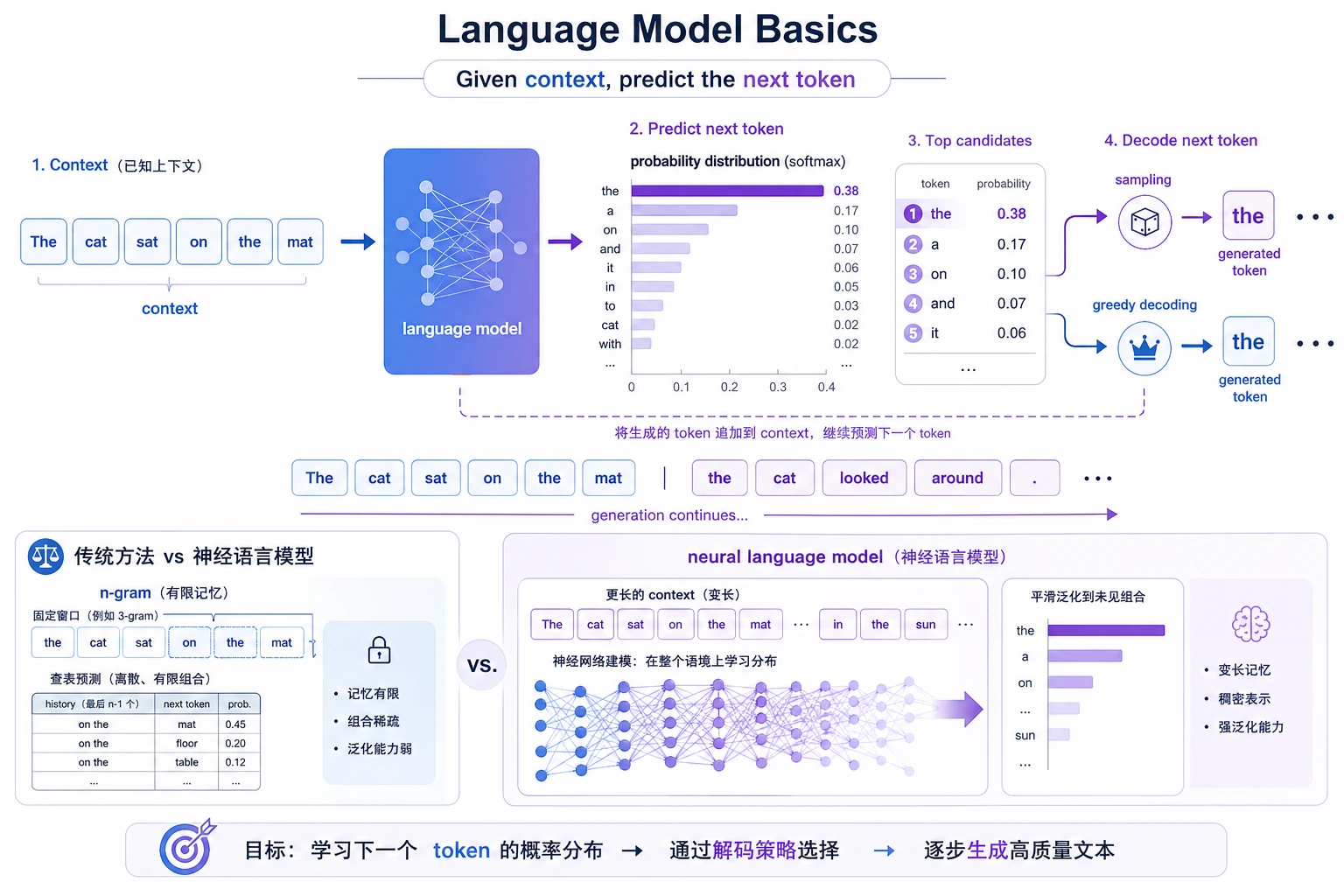
- 理解语言模型最基本的任务目标
- 理解 n-gram 语言模型和现代神经语言模型之间的连续性
- 通过可运行示例建立“预测下一个 token”的直觉
- 理解为什么语言模型会成为后面大模型的共同基础
一、语言模型到底在学什么?
Section titled “一、语言模型到底在学什么?”最基本的形式
Section titled “最基本的形式”一句话讲,就是:
- 给定前文,预测下一个 token
例如:
- “我 爱” -> 下一个词可能是
AI、你、Python
为什么这个任务看起来简单却很强?
Section titled “为什么这个任务看起来简单却很强?”因为要做好这件事,模型必须逐渐学会:
- 词法搭配
- 语法结构
- 常见语义关系
- 一些世界知识
也就是说, “预测下一个 token”虽然目标简单, 但背后会逼着模型学很多语言规律。
语言模型像在玩“接龙”, 但这不是随便接,而是要接得:
- 像人类语言
- 像当前语境
- 像合理延续
二、先从 n-gram 直觉开始
Section titled “二、先从 n-gram 直觉开始”什么是 n-gram 语言模型?
Section titled “什么是 n-gram 语言模型?”它可以先理解成:
- 只看前面很短的一小段历史
- 用统计频次预测后面会出现什么
例如 bigram:
- 只看前 1 个词
trigram:
- 只看前 2 个词
这种方法有什么好处?
Section titled “这种方法有什么好处?”- 直观
- 可解释
- 容易上手
它的局限也很明显
Section titled “它的局限也很明显”- 看不到长距离依赖
- 很容易稀疏
- 泛化能力弱
但它非常适合帮助新人建立语言模型的第一层直觉。
三、先跑一个 bigram 示例
Section titled “三、先跑一个 bigram 示例”from collections import defaultdict, Counter
corpus = [ "我 爱 AI", "我 爱 Python", "你 爱 NLP",]
stats = defaultdict(Counter)
for sent in corpus: toks = sent.split() for a, b in zip(toks[:-1], toks[1:]): stats[a][b] += 1
print(dict(stats))预期输出:
{'我': Counter({'爱': 2}), '爱': Counter({'AI': 1, 'Python': 1, 'NLP': 1}), '你': Counter({'爱': 1})}把它当成一个极小的 next-token 表:看到 我 之后,下一个 token 是 爱 出现了 2 次;看到 爱 之后,AI、Python、NLP 各出现 1 次。
这段代码最重要的价值是什么?
Section titled “这段代码最重要的价值是什么?”它把语言模型最底层的逻辑掀开来看:
- 看到一个词后
- 下一个词在训练语料里出现过多少次
为什么这已经像一个“语言模型”了?
Section titled “为什么这已经像一个“语言模型”了?”因为它已经在做:
- 条件概率估计
例如看到:
爱
后面接:
AIPythonNLP
各自概率不同。
四、怎么从统计模型走到神经语言模型?
Section titled “四、怎么从统计模型走到神经语言模型?”核心任务没变
Section titled “核心任务没变”虽然模型架构后面变得越来越复杂, 但一个重要事实是:
- 目标函数常常还是“预测下一个 token”
变的是表示和泛化方式
Section titled “变的是表示和泛化方式”神经语言模型不再只是查频次表, 而是会:
- 用向量表示 token
- 用神经网络建模上下文
这样它就能:
- 看更长的历史
- 学到更抽象的模式
- 对没见过的组合有更强泛化
一个简化的“预测分布”例子
Section titled “一个简化的“预测分布”例子”import math
scores = { "AI": 2.0, "Python": 1.5, "NLP": 0.8,}
def softmax(score_dict): exps = {k: math.exp(v) for k, v in score_dict.items()} total = sum(exps.values()) return {k: round(v / total, 4) for k, v in exps.items()}
print(softmax(scores))预期输出:
{'AI': 0.5242, 'Python': 0.3179, 'NLP': 0.1579}模型不一定立刻只输出一个词。它会先给出概率分布,后面的解码规则再选择、采样或排序候选 token。
这不是完整神经网络, 但它已经在表达一件关键事:
- 模型不是只输出一个词
- 而是在输出一个“下一词概率分布”
五、为什么语言模型会成为大模型的共同底座?
Section titled “五、为什么语言模型会成为大模型的共同底座?”因为这个目标足够通用
Section titled “因为这个目标足够通用”无论后面你是做:
- 对话
- 写作
- 代码生成
- 摘要
很多能力都能从“语言延续能力”里长出来。
因为它很适合大规模自监督学习
Section titled “因为它很适合大规模自监督学习”你不需要人工标注“下一个词是什么”, 文本本身就天然带这个标签。
这使得:
- 海量文本
- 自监督训练
可以自然结合起来。
这也是为什么后面会走向 GPT 这条线
Section titled “这也是为什么后面会走向 GPT 这条线”因为自回归语言建模:
- 简洁
- 统一
- 可扩展
这条路线后来成了大语言模型的重要主线之一。
六、最容易踩的坑
Section titled “六、最容易踩的坑”误区一:语言模型只是“会接下一个词”
Section titled “误区一:语言模型只是“会接下一个词””这个说法表面上对, 但低估了这个任务能逼模型学到的东西。
误区二:n-gram 没用,所以没必要学
Section titled “误区二:n-gram 没用,所以没必要学”n-gram 很有用, 因为它让你第一次真正看到语言模型在做什么。
误区三:只要会生成,就等于理解了语言
Section titled “误区三:只要会生成,就等于理解了语言”生成能力强不等于完全理解。 这也是后面为什么还要看推理、对齐和工具调用。
学完这一页,至少保留这张证据卡:
- 表示
- BoW、TF-IDF、静态 embedding、上下文 embedding,或语言模型分数
- 比较
- 最近文本、相似度分数或下一 token/log-prob 风格输出
- 解释
- 该表示捕捉了什么,以及遗漏了什么
- 失败检查
- 一词多义、领域不匹配、文本过短、分词问题或语义漂移
- 期望产出
- 至少有一个意外结果的小型对比表
这节最重要的是建立一个很稳定的判断:
语言模型最基础的任务,就是在给定前文时预测下一个 token;而正是这个看似简单的目标,构成了后面大模型很多能力的底座。
只要这条主线清楚了, 你后面再看 GPT、预训练和生成模型时,就会自然很多。
- 自己再加几句语料,看看
stats会怎么变。 - 为什么说 bigram 虽然简单,但已经抓到了语言模型的核心?
- 用自己的话解释:语言模型为什么天然适合大规模自监督训练?
- 想一想:为什么“会接下一个词”这件事,最后能长出对话和写作能力?
参考实现与讲解
- 增加语料句子会改变
stats里的转移计数;常见后续词概率变高,稀有后续词相对变弱。 - bigram 很简单,但已经包含语言模型核心:根据前文估计下一个 token 更可能是什么。
- 语言模型天然适合自监督训练,因为普通文本本身就提供了输入上下文和 next-token 目标。
- “续写下一个词”之所以能发展出写作和对话能力,是因为叠加了规模、表示学习、指令微调、反馈和长上下文。