6.4.1 RNN 路线图:按顺序处理序列
RNN 面向有顺序的数据:文本、时间序列、点击流、传感器读数,以及任何前面步骤会影响后面步骤的输入。
RNN 为什么会出现
Section titled “RNN 为什么会出现”普通 MLP 或 CNN 更擅长处理固定长度、位置结构比较稳定的输入。但很多数据不是“一次看完就够”:
| 数据问题 | 为什么普通模型不够自然 | RNN 的回答 |
|---|---|---|
| 文本有先后顺序 | 同一批词换顺序,意思可能完全不同 | 按时间步读入 token |
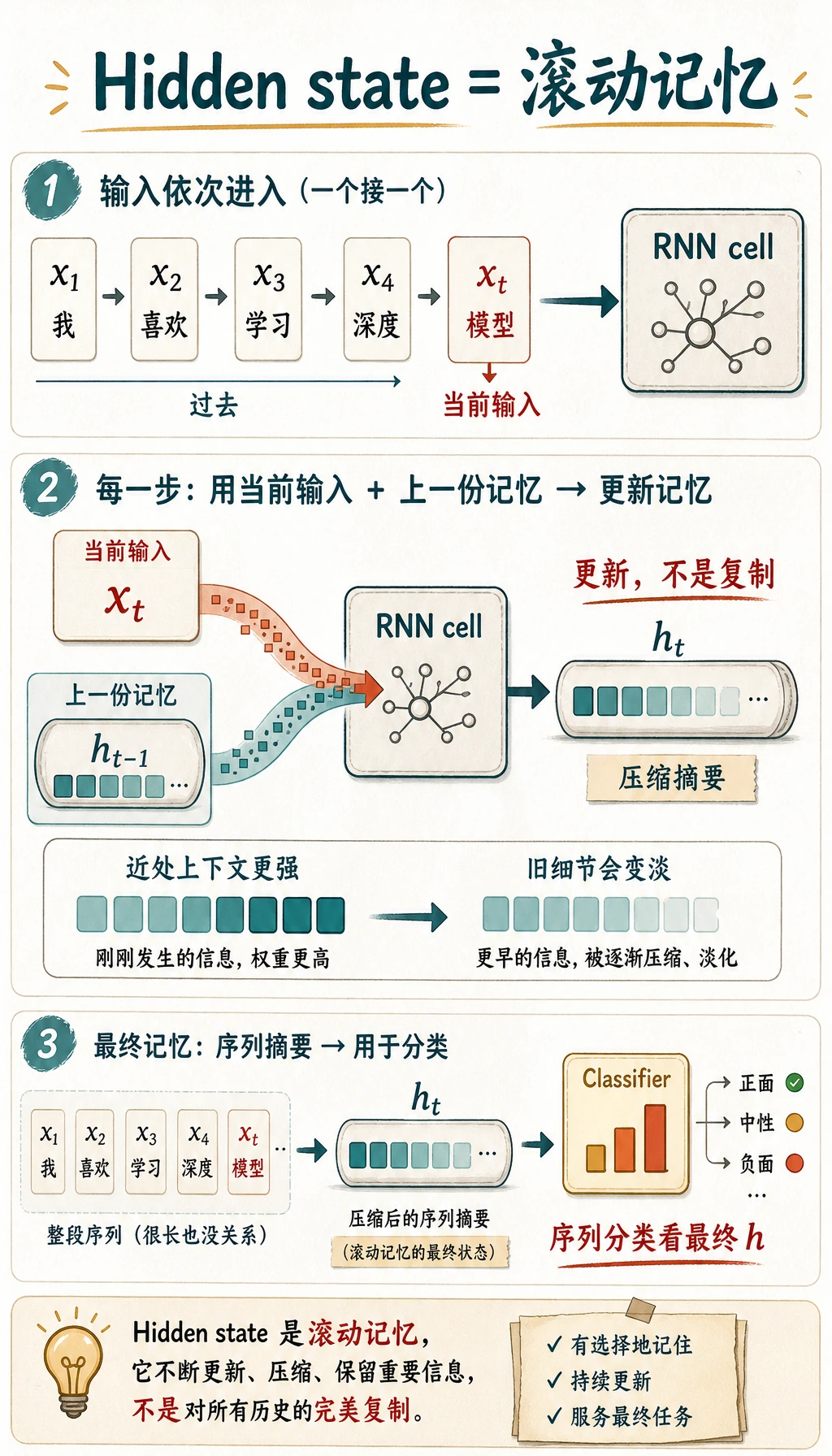
| 时间序列依赖历史 | 当前值常常受前面趋势影响 | 用 hidden state 保存滚动记忆 |
| 序列长度可能变化 | 固定维度输入不方便接收不同长度 | 同一个 RNN cell 可重复应用 |
所以 RNN 的历史作用,是把“上一步的信息会影响下一步”写进模型结构。后来 LSTM/GRU 出现,是因为普通 RNN 的记忆容易衰减,长距离信息很难稳定保留下来。
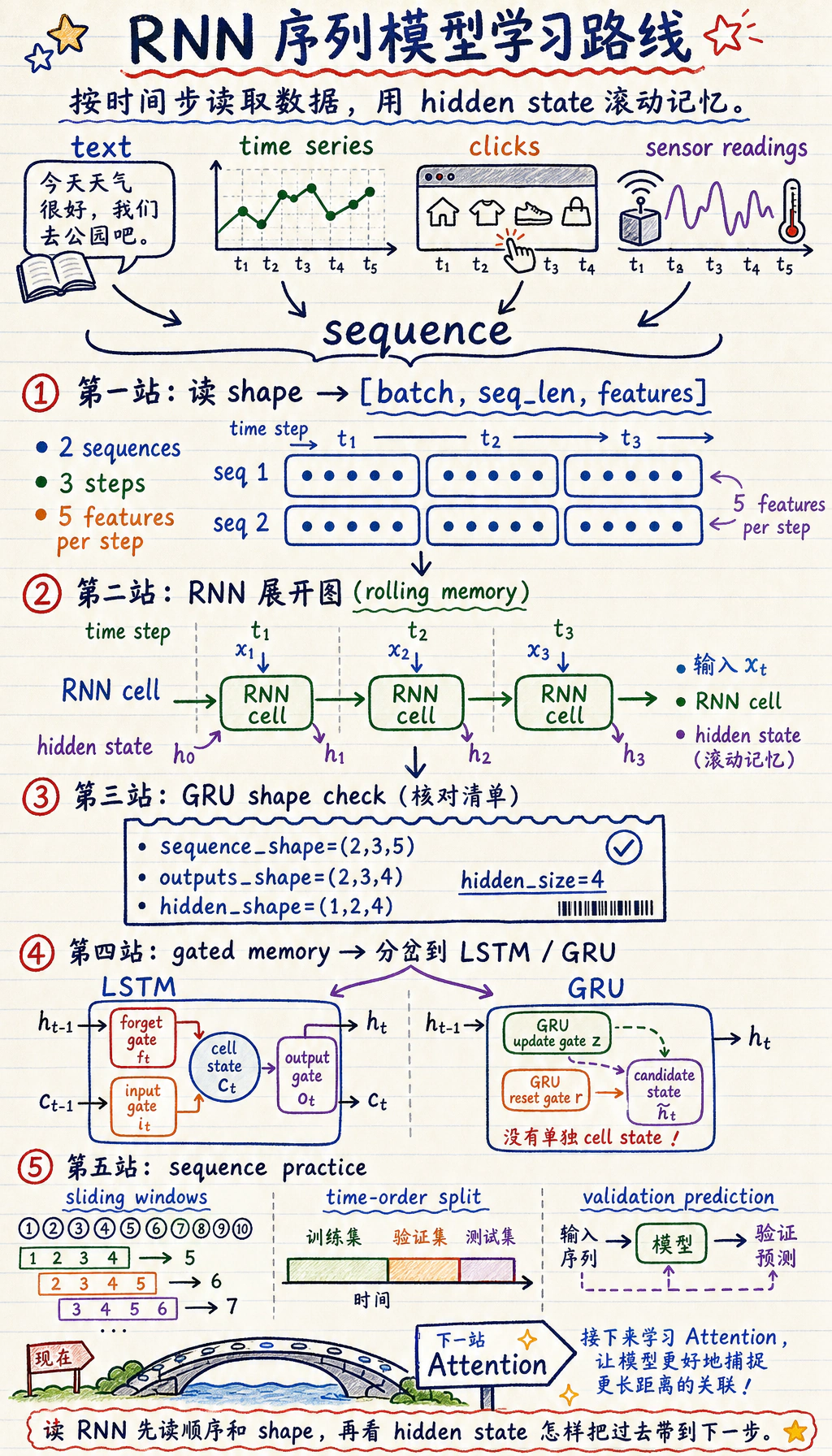
| 概念 | 第一层意思 |
|---|---|
| sequence length | 时间步数量 |
| input size | 每一步的特征数 |
| hidden state | 滚动记忆 |
| LSTM / GRU | 门控记忆控制 |
| batch first | [batch, seq_len, features] 这种形状风格 |
跑一次 GRU 形状检查
Section titled “跑一次 GRU 形状检查”创建 rnn_first_loop.py,安装 torch 后运行。
import torch
sequence = torch.randn(2, 3, 5)gru = torch.nn.GRU(input_size=5, hidden_size=4, batch_first=True)outputs, hidden = gru(sequence)
print("sequence_shape:", tuple(sequence.shape))print("outputs_shape:", tuple(outputs.shape))print("hidden_shape:", tuple(hidden.shape))预期输出:
sequence_shape: (2, 3, 5)outputs_shape: (2, 3, 4)hidden_shape: (1, 2, 4)读作:2 条序列,每条 3 步,每步 5 个特征。GRU 输出隐藏表示大小为 4。
按这个顺序学
Section titled “按这个顺序学”| 顺序 | 阅读 | 练什么 |
|---|---|---|
| 1 | 6.4.2 RNN 基础 | 序列输入、隐藏状态、形状 |
| 2 | 6.4.3 LSTM 与 GRU | 门控、长依赖、记忆控制 |
| 3 | 6.4.4 序列建模实战 | 滑动窗口、训练/评估循环 |
保留一条序列 shape 笔记:
- 输入
- [batch, seq_len, features]
- 输出
- 每一步一个隐藏表示
- 隐藏状态
- 压缩的滚动记忆
- 门控原因
- LSTM/GRU 有助于保留或丢弃信息
- 基线
- 将序列模型与一个简单的朴素规则比较
能读懂 [batch, seq_len, features],把 hidden state 解释成滚动记忆,并知道 LSTM/GRU 是为长依赖而引入,就算通过。
检查思路与讲解
- 合格答案要把 tensor、模型层、loss、
backward()和 optimizer 更新连成一个训练闭环。 - 证据应包含可运行的小实验、tensor shape 检查,以及能解释的 loss 或验证曲线。
- 自检时要能指出一个失败模式,例如 shape 不匹配、loss 不下降、过拟合、数据泄漏,或只会说 Attention/Transformer 名词却讲不出数据流。