11.1.1 文本基础路线图:Token、清洗、表示
文本不是天然可计算对象。在分类、抽取、总结或问答之前,需要先把原始文本变成稳定单元和特征。
为什么先从文本基础开始
Section titled “为什么先从文本基础开始”早期 NLP 很多系统依赖规则、词典和正则。它们不“过时”,因为在明确格式、低风险自动化和数据很少时仍然好用。但只靠规则会很快遇到表达变体:
| 旧问题 | 文本基础要解决什么 |
|---|---|
| 同一个意思有很多写法 | 先做规范化、分词和样例检查 |
| 文本里混有噪声、表情、拼写和特殊符号 | 判断哪些该保留,哪些该清理 |
| 模型不能直接吃原始字符串 | 把文本变成 token、id、词表或向量 |
| 下游输出不清楚 | 先定义分类、抽取、检索、生成或 QA |
所以文本基础不是“正式模型前的杂活”。它决定后面的模型到底看见什么,也决定错误能不能被复盘。
先看文本流水线
Section titled “先看文本流水线”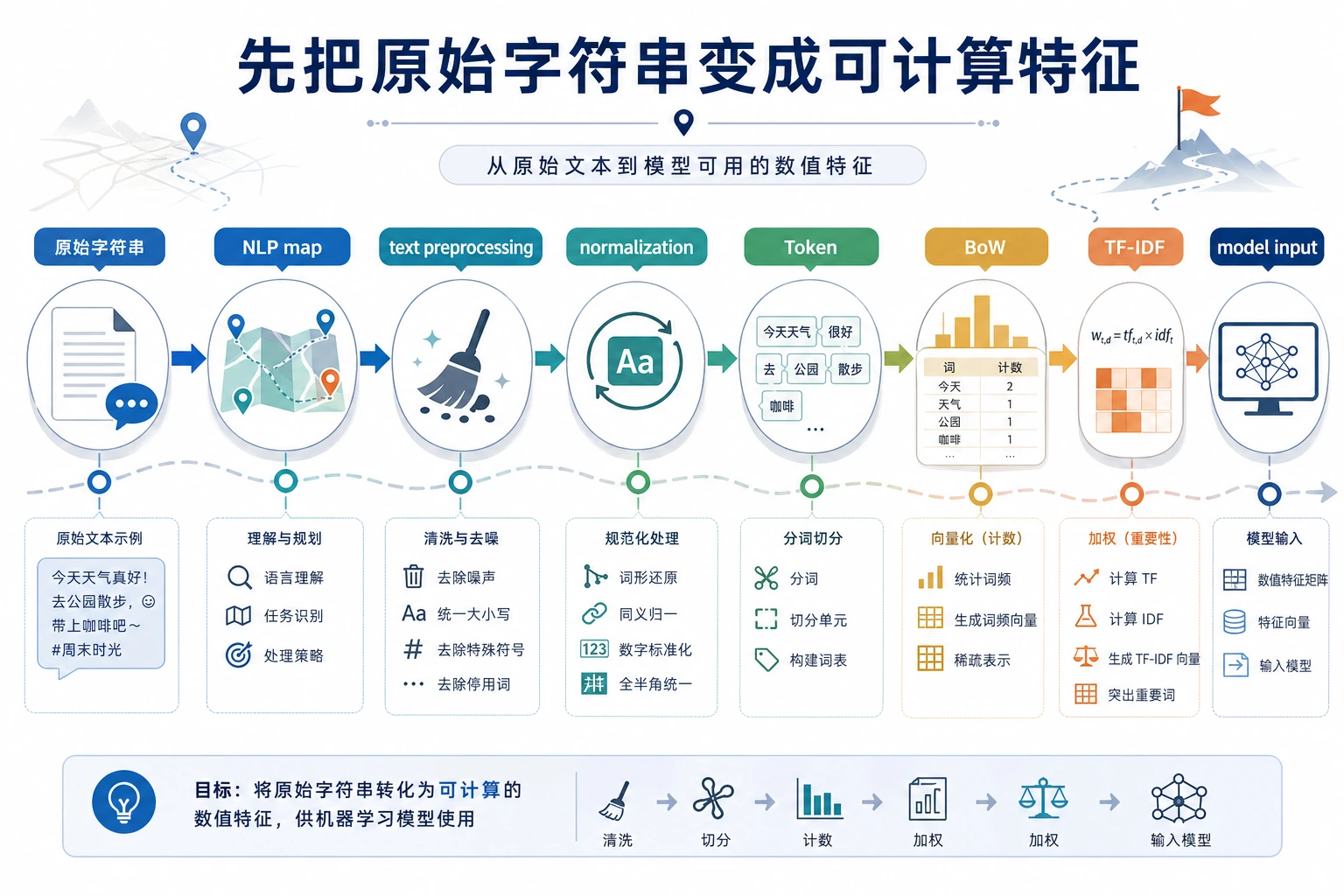


第一个习惯是先问:输入文本是什么、任务是什么、系统应该产生什么输出形态?
跑一个 Token 和词表检查
Section titled “跑一个 Token 和词表检查”text = "RAG answers need citations"tokens = text.lower().split()vocab = {token: index for index, token in enumerate(sorted(set(tokens)))}ids = [vocab[token] for token in tokens]
print("tokens:", tokens)print("ids:", ids)print("vocab_size:", len(vocab))预期输出:
tokens: ['rag', 'answers', 'need', 'citations']ids: [3, 0, 2, 1]vocab_size: 4如果分词不稳定,下游任务也会跟着不稳定。
按这个顺序学
Section titled “按这个顺序学”| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | NLP 任务地图 | 匹配分类、标注、抽取、问答、总结 |
| 2 | 预处理 | 规范化文本、切分 token、处理噪声和边界 |
| 3 | 文本表示 | 构建 tokens、ids、词表、稀疏特征或向量 |
如果你能接收原始文本、完成分词、解释任务输出形态,并在项目笔记里保存一个预处理例子,就通过了本章。
检查思路与讲解
- 合格答案要从文本单元和输出类型说起:token、span、句子标签、序列、embedding 或生成文本。
- 证据应包含小样本、模型或 pipeline 选择、评价指标,以及至少一个被检查过的错误案例。
- 自检时要能区分预处理问题和模型问题,例如分词错误、标签歧义、数据不平衡或生成幻觉。
学完这一页,至少保留这张证据卡:
- 原始文本
- 清洗或分词前的原始示例
- 处理后文本
- 清理后的文本、tokens、归一化说明和已移除项
- 任务边界
- 分类、抽取、检索、生成或 QA 输出
- 失败检查
- 含义丢失、分词不佳、语言问题或标签歧义
- 期望产出
- 前后对比文本样本,以及 token 或表示输出