8.5.1 项目路线图:构建带引用的知识助手
这个综合项目证明你能把知识、模型调用、应用流程和工程证据连接成一个可复现的大模型应用。
先看项目证据闭环
Section titled “先看项目证据闭环”
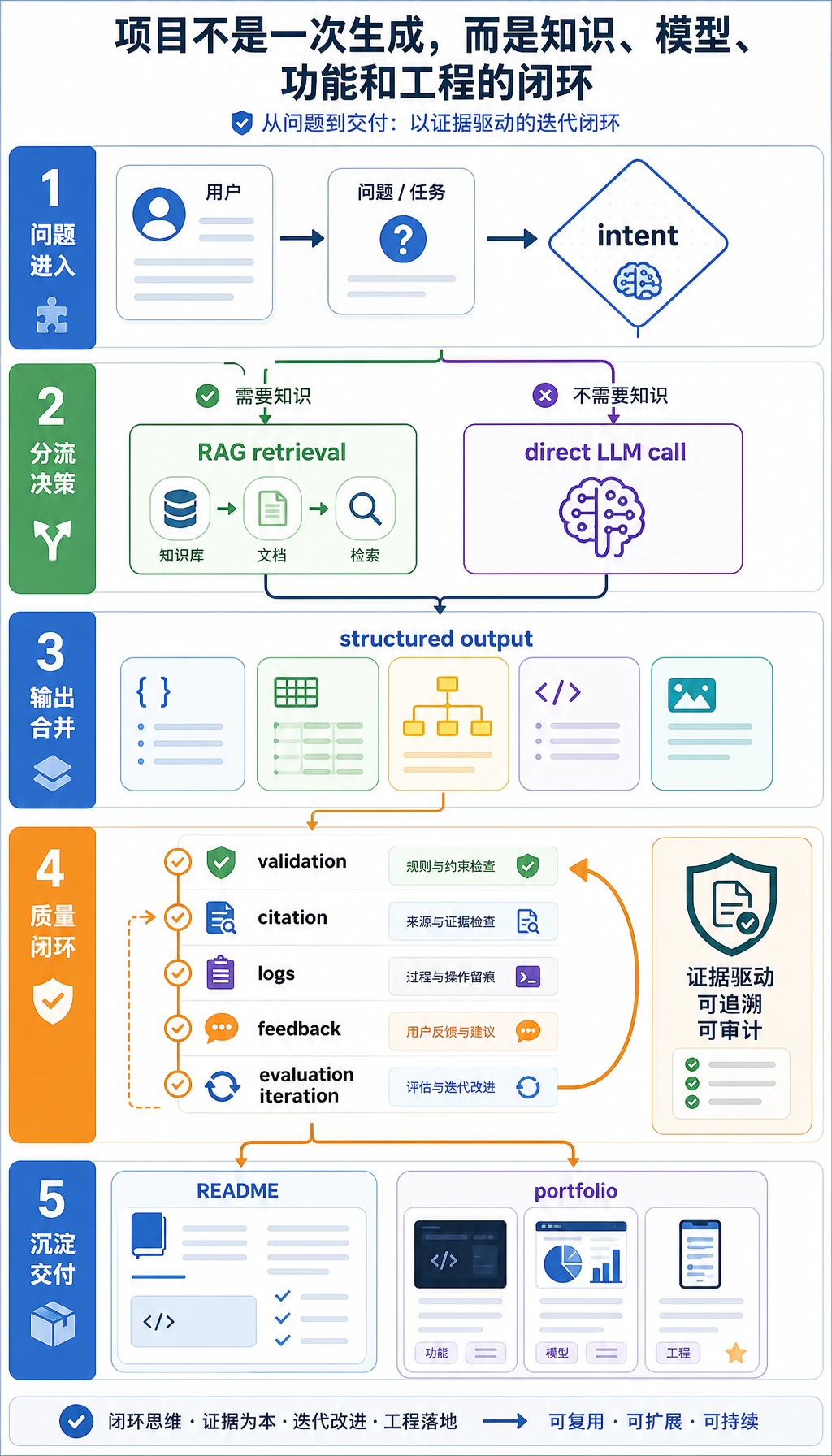
项目不是“连上向量数据库”。它是一个可追踪闭环:文档、分块、检索、上下文、回答、引用、日志、评估和改进。
跑一个项目就绪检查
Section titled “跑一个项目就绪检查”提交项目前先用这张检查表。
project = { "project_type": "knowledge-base assistant", "documents": 5, "eval_questions": 10, "citations": True, "empty_retrieval_handled": True, "failure_cases": 3,}
ready = ( project["documents"] >= 3 and project["eval_questions"] >= 10 and project["citations"] and project["empty_retrieval_handled"] and project["failure_cases"] >= 1)
print("ready:", ready)print("project_type:", project["project_type"])print("evidence:", "docs, eval, citations, failures")预期输出:
ready: Trueproject_type: knowledge-base assistantevidence: docs, eval, citations, failures如果 ready 是 False,先不要继续加功能。先补完证据闭环。
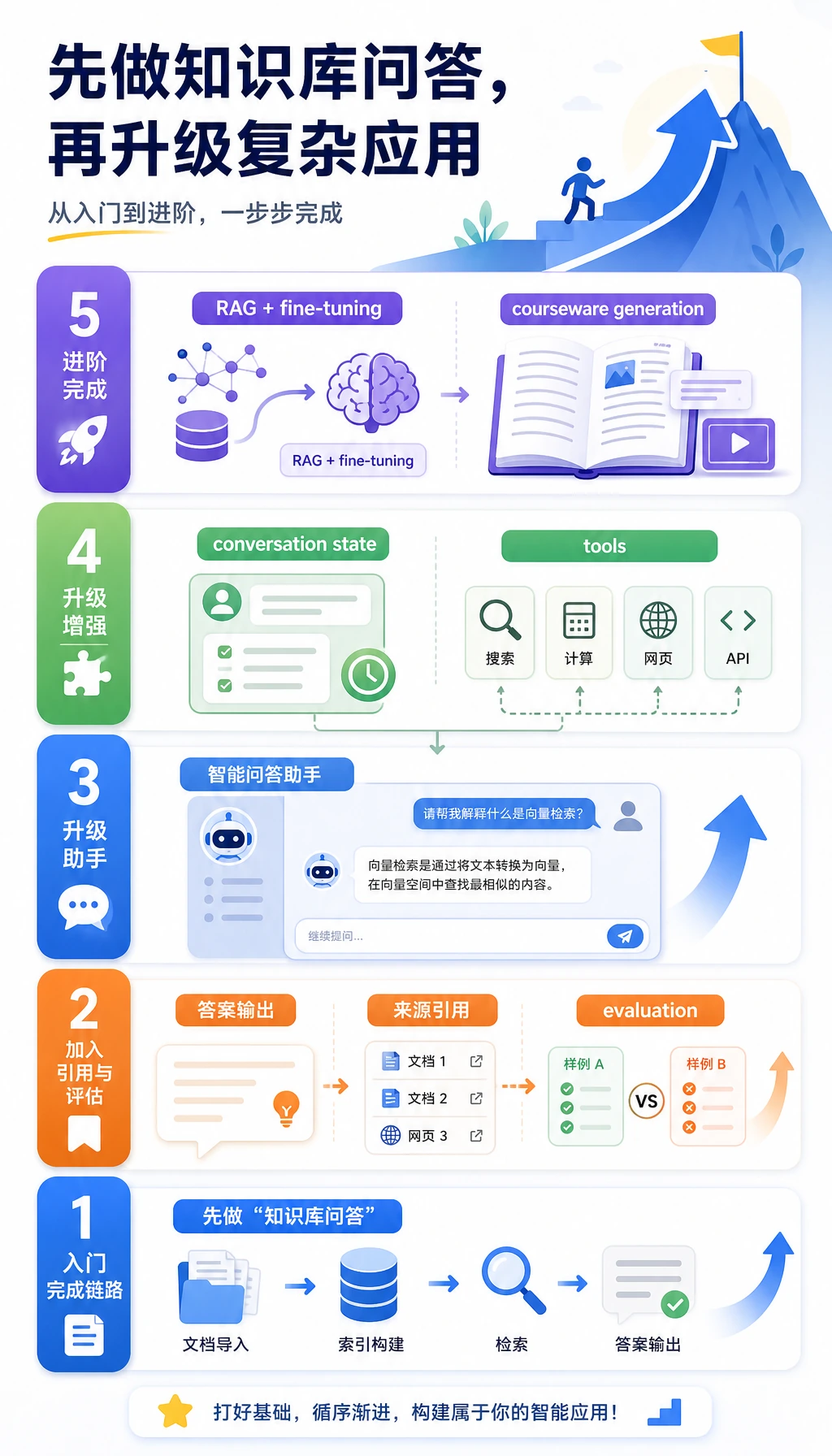
按这个顺序学
Section titled “按这个顺序学”| 步骤 | 项目 | 真正训练的能力 |
|---|---|---|
| 1 | 企业或课程知识库 | 检索、权限、引用和可追踪回答 |
| 2 | 智能助手 | 把检索、会话状态和工具调用做成产品功能 |
| 3 | RAG + 微调系统 | 区分知识缺失和行为不稳定 |
| 4 | SOP 文档助手 | 文档解析、结构化输出和模板渲染 |
| 5 | 完整实操工作坊 | 在真实 API 或数据库前先跑最小可复现闭环 |
如果需要带着做的基线,从 8.5.6 实操:完整第 8 章 RAG 应用工作坊 开始。
项目交付物标准
Section titled “项目交付物标准”| 交付物 | 最低要求 | 更强的作品集版本 |
|---|---|---|
| README | 目标、运行命令、依赖和示例 | 增加架构图、设计取舍、成本和复盘 |
| 知识库样本 | 原始文档、chunks、metadata 和 source 字段 | 增加权限规则、文档版本和更新说明 |
| 检索日志 | 匹配片段、分数和排序 | 增加失败类型统计和前后对比 |
| 回答引用 | 最终回答显示支撑来源 | 增加引用忠实度检查 |
| 失败案例 | 至少 1 个记录下来的失败 | 增加 3 个以上案例,包含原因、修复和回归检查 |
| 评估 | 固定问题和通过/失败规则 | 增加基线、指标和回归测试 |
| 部署说明 | 如何运行和需要哪些环境变量 | 增加 Docker、监控和降级说明 |
学完这一页,至少保留这张证据卡:
- 项目目标
- 用户任务和业务边界
- 基线
- 最简单的提示/RAG/应用版本优先
- 评估
- 固定案例、检索证据、答案质量和引用检查
- 失败日志
- 至少一个失败案例及其可能原因
- 交付物
- README、运行命令、截图/日志、下一步
如果项目能带引用回答、展示检索日志、处理空检索、保留评估案例,并解释至少一个失败,就通过了本章。
最强作品集版本不一定最大。更重要的是,另一个开发者能复现运行、查看证据,并理解你下一轮会怎样改进。
检查思路与讲解
- 合格答案要能追踪 query、chunks、检索分数、引用证据、最终回答和兜底行为。
- 证据应包含检索片段、source metadata、带引用的回答,以及至少一个空检索或误检索案例。
- 自检时要能判断失败来自 chunking、检索、排序、prompt 拼装、资料缺失,还是无依据生成。