9.10.2 项目:智能研究助手
- 学会把研究助手项目范围定得清楚
- 学会把“检索 -> 阅读 -> 总结 -> 引用”串成闭环
- 学会定义这个项目最关键的评估标准
- 学会把它包装成一个有说服力的作品集项目
先把项目范围定窄
Section titled “先把项目范围定窄”一个适合练手的研究助手项目,建议先做成:
- 给定主题
- 检索若干文档
- 输出结构化摘要
- 每条摘要带来源
而不是一上来就做:
- 自动写论文
- 自动做综述
因为对研究助手来说,“可信”比“花哨”更重要。
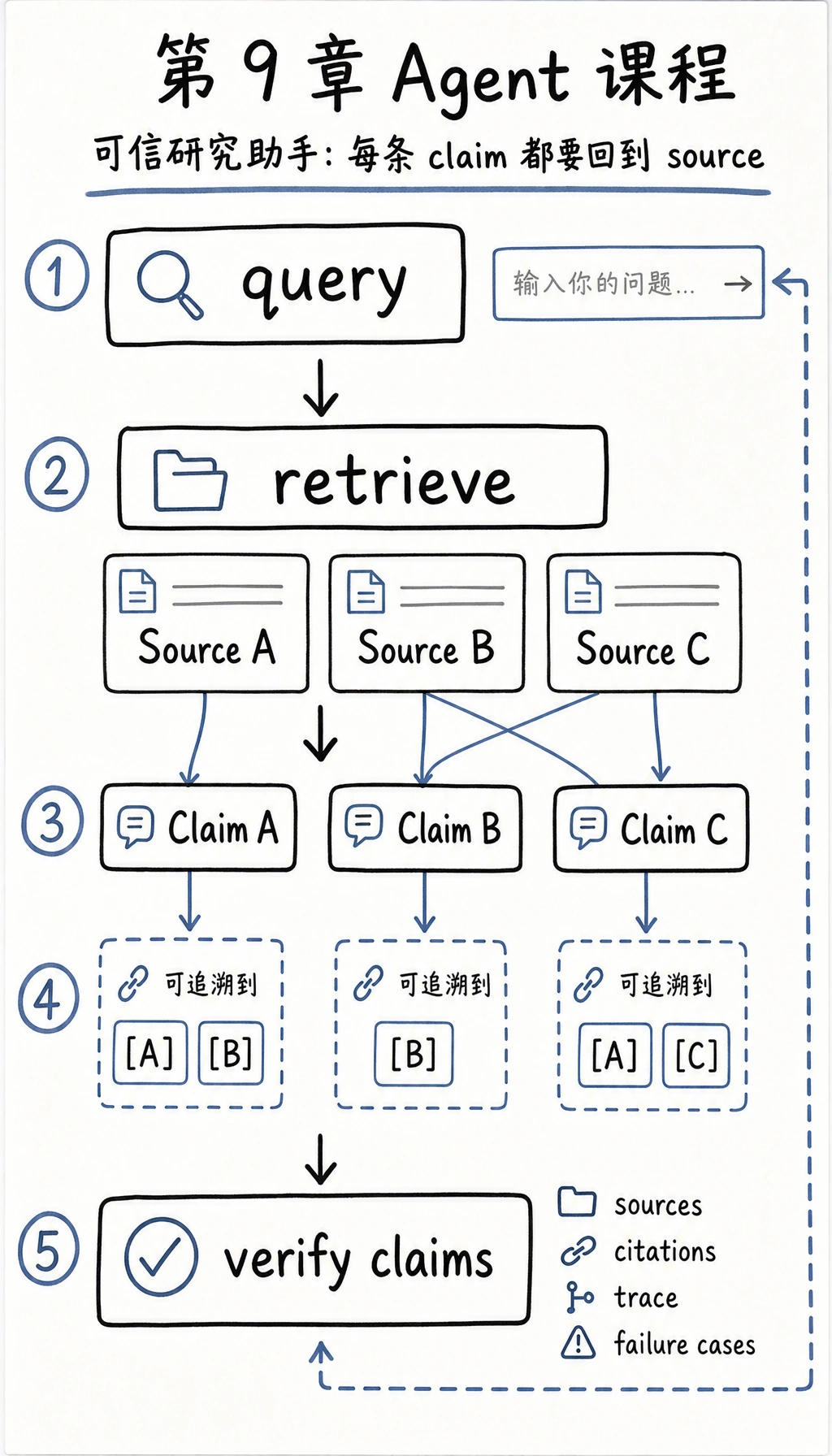
作品级研究助手最小闭环长什么样?
Section titled “作品级研究助手最小闭环长什么样?”- 输入主题或问题
- 检索候选资料
- 选出最相关资料
- 生成结构化摘要
- 给出每条摘要来源
- 做错误分析和回归集
只要这 6 步清楚,这个项目就很有作品集价值。
推荐推进顺序
Section titled “推荐推进顺序”对新人来说,更稳的顺序通常是:
- 先把主题范围收窄
- 再做最简单检索 基线
- 再补结构化总结
- 最后再补引用校验和失败案例展示
这样你才更容易把“可信研究助手”做成一个清楚闭环。
先看一个最小研究助手示例
Section titled “先看一个最小研究助手示例”下面这个例子会做三件事:
- 用关键词匹配模拟检索
- 生成结构化总结
- 给每条总结附来源
docs = [ { "id": "d1", "title": "RAG improves factual grounding", "text": "RAG can improve factual grounding by retrieving external evidence.", "keywords": {"rag", "retrieval", "grounding", "evidence"}, }, { "id": "d2", "title": "Long context still struggles with precision", "text": "Long context models may still miss key details without retrieval or re-ranking.", "keywords": {"long", "context", "retrieval", "ranking"}, }, { "id": "d3", "title": "Citations increase user trust", "text": "Users trust generated summaries more when each claim is tied to an explicit source.", "keywords": {"citation", "trust", "summary", "source"}, },]
def retrieve(query, top_k=2): query_terms = set(query.lower().split()) scored = [] for doc in docs: score = len(query_terms & doc["keywords"]) scored.append((score, doc)) scored.sort(key=lambda x: x[0], reverse=True) return [doc for score, doc in scored[:top_k] if score > 0]
def summarize_with_citations(query): hits = retrieve(query, top_k=2) bullets = [] for doc in hits: bullets.append( { "claim": doc["text"], "source_id": doc["id"], "source_title": doc["title"], } ) return bullets
query = "rag retrieval citation trust"result = summarize_with_citations(query)for item in result: print(item)预期输出:
{'claim': 'RAG can improve factual grounding by retrieving external evidence.', 'source_id': 'd1', 'source_title': 'RAG improves factual grounding'}{'claim': 'Users trust generated summaries more when each claim is tied to an explicit source.', 'source_id': 'd3', 'source_title': 'Citations increase user trust'}这个例子为什么比“项目骨架 dataclass”更有价值?
Section titled “这个例子为什么比“项目骨架 dataclass”更有价值?”因为它已经体现出研究助手最关键的产品特征:
- 结果不是一段黑盒总结
- 每条结论都能回到来源
为什么引用是这类项目的命门?
Section titled “为什么引用是这类项目的命门?”因为没有来源,用户很难区分:
- 这是系统真的从文档里读出来的
- 还是模型自己编的
这个项目最该怎么评估?
Section titled “这个项目最该怎么评估?”例如:
- 命中的文档是否真的相关
例如:
- 是否覆盖关键点
- 是否过度概括
这是研究助手特别重要的一层:
- 每条 claim 是否真的能在引用来源里找到支持
一个最小评估数据结构
Section titled “一个最小评估数据结构”继续在同一个文件或 Python 会话里运行,因为下面这段会复用 summarize_with_citations()。
eval_cases = [ { "query": "rag retrieval grounding", "expected_source_ids": {"d1", "d2"}, }, { "query": "citation trust summary", "expected_source_ids": {"d3"}, },]
for case in eval_cases: hit_ids = sorted(item["source_id"] for item in summarize_with_citations(case["query"])) overlap = sorted(set(hit_ids) & case["expected_source_ids"]) print({ "query": case["query"], "hit_ids": hit_ids, "overlap": overlap, })预期输出:
{'query': 'rag retrieval grounding', 'hit_ids': ['d1', 'd2'], 'overlap': ['d1', 'd2']}{'query': 'citation trust summary', 'hit_ids': ['d3'], 'overlap': ['d3']}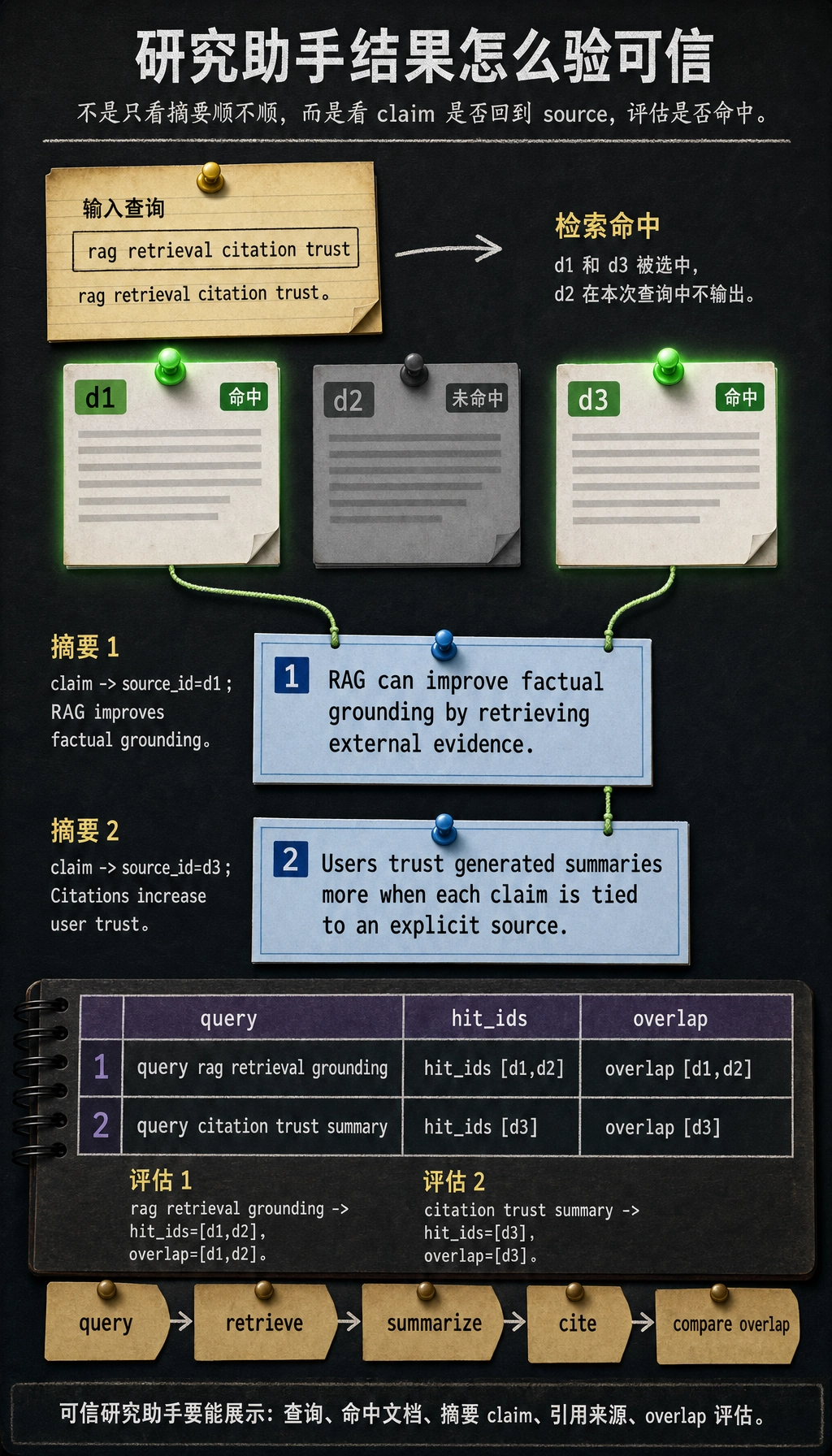
用这张图检查检索命中、引用和最终评估是否互相对得上。
最容易踩的坑
Section titled “最容易踩的坑”检索对了,但总结丢了关键点
Section titled “检索对了,但总结丢了关键点”总结看起来通顺,但来源对不上
Section titled “总结看起来通顺,但来源对不上”项目只展示一段“看起来很聪明”的回答
Section titled “项目只展示一段“看起来很聪明”的回答”研究助手最值得展示的其实是:
- 查询词
- 检索结果
- 摘要条目
- 引用来源
这条完整 trace。
怎么把它打磨成作品级项目?
Section titled “怎么把它打磨成作品级项目?”页面上分四栏展示
Section titled “页面上分四栏展示”- 查询
- 检索来源
- 结构化总结
- 引用
准备 5~10 个固定评估问题
Section titled “准备 5~10 个固定评估问题”这样你可以稳定展示:
- 前后对比
- 检索策略变更
- 总结策略改进
单独列失败案例
Section titled “单独列失败案例”例如:
- 检索到不相关文档
- 正确文档被漏掉
- 总结 claim 与引用不一致
项目交付时最好补上的内容
Section titled “项目交付时最好补上的内容”- 一张查询到引用的流程图
- 一组检索结果与最终总结并排展示
- 一组引用对不上或总结漏点的失败案例
- 一段你对“可信输出”怎么定义的说明
作品集级 Agent 交付标准
Section titled “作品集级 Agent 交付标准”如果把研究助手作为 Agent 作品集,建议不要只展示最终摘要,而是展示“目标、工具、执行、引用、评估、安全边界”的完整闭环。
| 交付项 | 最低要求 | 作品集级要求 |
|---|---|---|
| 目标定义 | 能输入研究主题 | 明确适用范围、资料来源和不支持的任务 |
| 工具清单 | 至少有检索或读取工具 | 写清工具用途、参数、返回值和权限边界 |
| 执行 追踪 | 打印检索和总结过程 | 保存每一步 action、arguments、observation、next_decision |
| 引用检查 | 每条摘要带来源 | 每个关键 claim 都能回到具体来源片段 |
| 失败恢复 | 工具失败时给出错误 | 区分空结果、超时、引用不支持、总结漏点 |
| 评估记录 | 准备少量测试问题 | 有固定评估集、基线、失败样本和改进记录 |
| 安全边界 | 不自动执行高风险动作 | 明确只读工具、人工确认、最大步数和成本限制 |
这张表会让项目从“能总结资料”升级成“可信、可追踪、可复盘的 Agent 系统”。
推荐 README 结构
Section titled “推荐 README 结构”研究助手项目的 README 可以按下面顺序写:
# 研究助手 Agent(Research Assistant Agent)
## 1. 项目目标说明它解决什么研究场景,以及不解决什么。
## 2. 系统流程展示 query -> retrieval -> reading -> summary -> citation -> evaluation。
## 3. 工具清单列出 search_docs、read_source、summarize、check_citation 等工具。
## 4. 运行方式给出安装依赖、准备数据、运行示例和评估命令。
## 5. 示例追踪展示一次完整执行过程,而不只是最终答案。
## 6. 评估结果展示检索命中、引用准确性、失败样本和改进记录。
## 7. 安全与限制说明资料来源限制、引用风险、最大步数、人工确认边界。README 最好让别人不用读源码,也能看懂系统做了什么、怎么验证、哪里还不可靠。
一个最小 Agent 追踪 示例
Section titled “一个最小 Agent 追踪 示例”goal: 总结 RAG 和长上下文模型的差异step 1: action=retrieve, arguments={query: "rag long context retrieval"}observation: 命中 d1, d2step 2: action=read_sources, arguments={source_ids: ["d1", "d2"]}observation: 读取到 grounding、precision、ranking 相关内容step 3: action=summarize_with_citationsobservation: 生成 3 条摘要,每条都有 source_idstep 4: action=check_citationsobservation: 2 条通过,1 条引用证据不足final: 返回 2 条可信摘要,并标记 1 条需要人工复核这个 trace 的价值在于:如果最终结果有问题,你可以回放到底是哪一步出错,而不是只盯着最终回答猜原因。
研究助手最常见的失败不是“完全不能回答”,而是“看起来合理但不可信”。建议至少记录下面几类失败。
-
检索漏召回 关键资料没有进入候选。检查查询是否太窄、关键词是否不匹配、
top_k是否太小。可以用查询改写、混合检索、扩大候选后 rerank 来改进。 -
阅读不完整 命中文档是对的,但漏掉关键段落。检查 chunk 大小和上下文组装。可以用 parent-child retrieval 或重新调整上下文拼装。
-
总结过度概括 摘要听起来对,但丢了限制条件。改进 prompt,要求每条输出都保留 claim、condition 和 source。
-
引用不支持 claim 和 source 对不上。增加 citation check,并逐条验证 claim。
-
循环调用 Agent 一直检索不停止。增加最大步数,并在没有新增信息时停止。
把这些失败样本放进项目,会比只展示成功案例更能体现工程能力。
学完这一页,至少保留这张证据卡:
- 项目目标
- 智能体应完成什么,以及必须不做什么
- 基线
- 在加入高级功能前的单智能体循环
- 追踪包
- 目标、计划、tool 调用、观察、记忆、评估
- 失败日志
- 一次失败或不安全的运行及其根因
- 交付物
- README、运行命令、trace 截图/日志、下一步
这节最重要的是建立一个作品级判断:
研究助手项目真正的亮点,不是“会总结”,而是“能把检索、总结和引用组织成可信、可追踪、可复核的输出”。
只要这点立住,这个项目就会很像一个成熟的 Agent 作品。
版本路线建议
Section titled “版本路线建议”| 版本 | 目标 | 交付重点 |
|---|---|---|
| 基础版 | 跑通最小闭环 | 能输入、能处理、能输出,并保留一组示例 |
| 标准版 | 形成可展示项目 | 增加配置、日志、错误处理、README 和截图 |
| 挑战版 | 接近作品集质量 | 增加评估、对比实验、失败样本分析和下一步路线 |
建议先完成基础版,不要一开始就追求大而全。每提升一个版本,都要把“新增了什么能力、怎么验证、还有什么问题”写进 README。
- 给示例再加一篇文档,让某个 查询 出现“相关文档竞争”。
- 想一想:为什么研究助手里“引用准确性”比普通问答更关键?
- 如果某条总结很好看但来源对不上,你会算它成功吗?为什么?
- 如果你把这个项目做成作品集,首页最该展示哪 4 块?
项目交付参考与讲解
- 可以新增第二篇与第一篇部分重叠、但某个细节不同或覆盖另一个子主题的文档。期望结果是 retrieval 能排序两篇文档,并让答案为每个 claim 引用正确来源。
- citation accuracy 对 research assistant 很关键,因为它的价值来自可追溯证据,而不只是流畅摘要。错误引用会让看似正确的答案失去使用价值。
- 如果摘要很好但来源不匹配,不应算成功。正确做法是标记 mismatch、修改摘要,或说明 evidence insufficient。
- 作品集首页最先展示 问题、证据/引用流程、演示轨迹、评估结果。这四块能证明它不只是普通聊天机器人。