8.3.1 应用开发路线图:API、工具、状态
大模型应用开发不是“一个输入框加一个模型 API”。真实功能需要校验输入、调用模型、使用工具、保存状态、解析输出、记录错误,并让用户有可恢复的体验。
先看应用闭环
Section titled “先看应用闭环”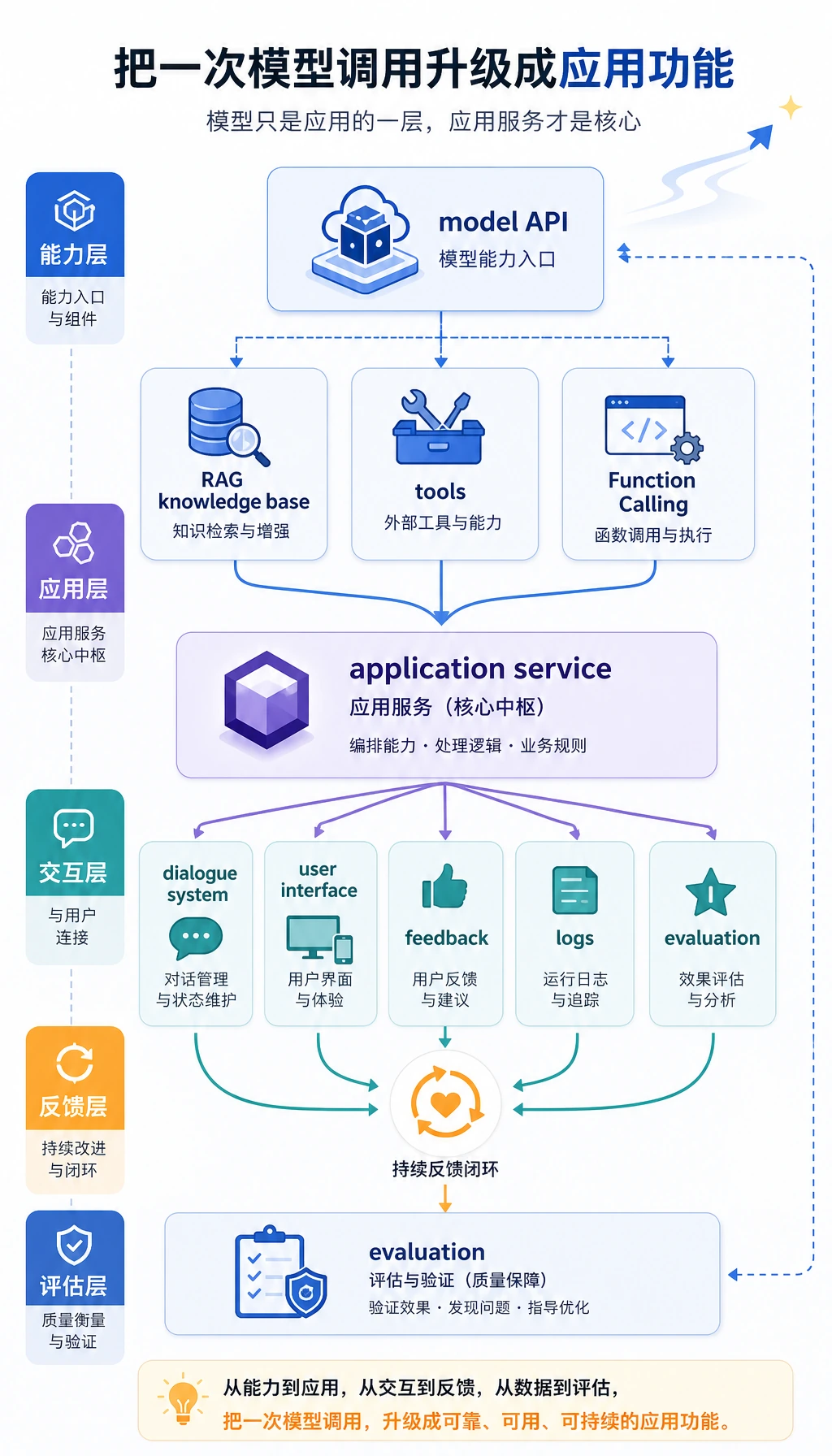
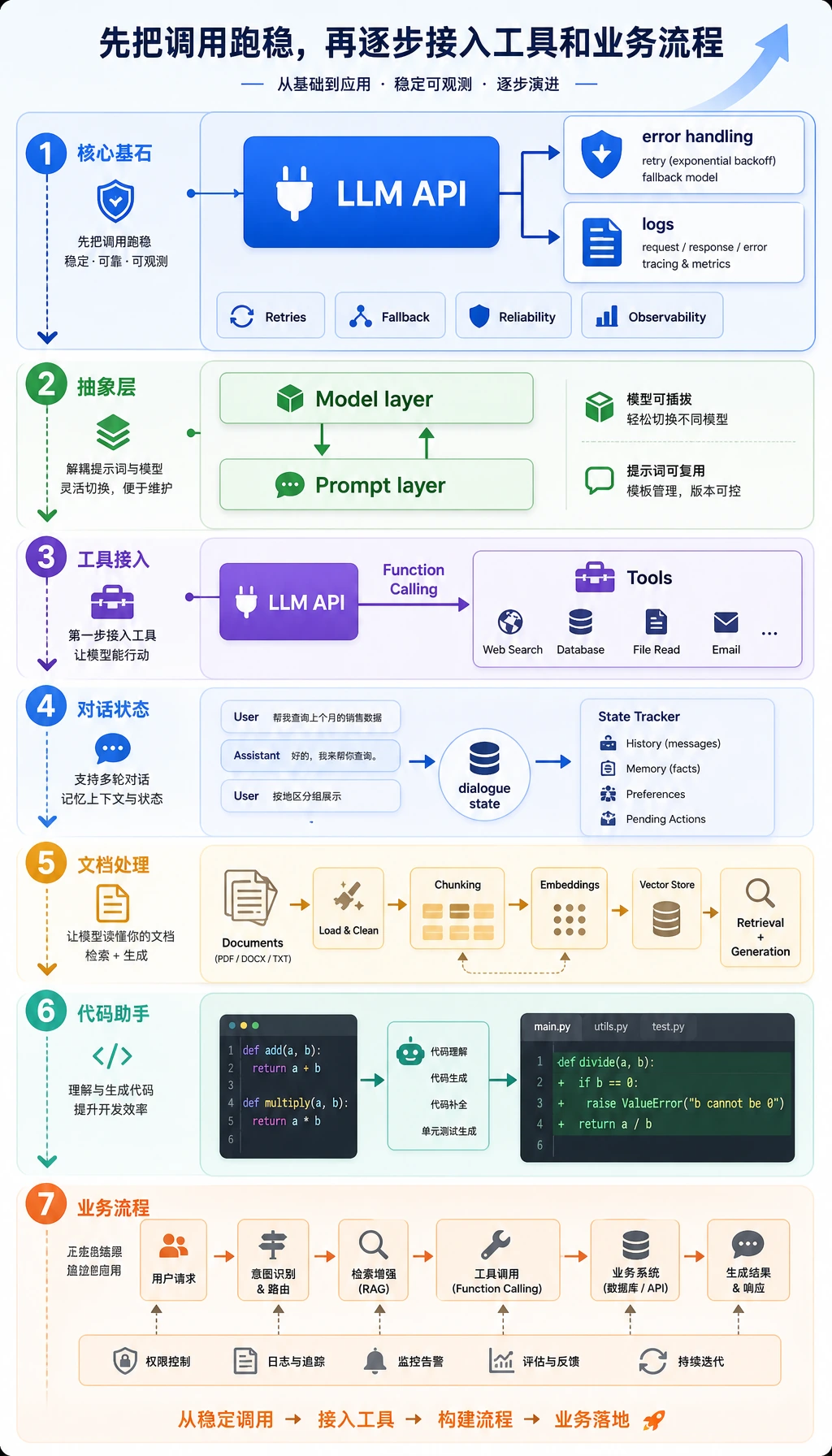
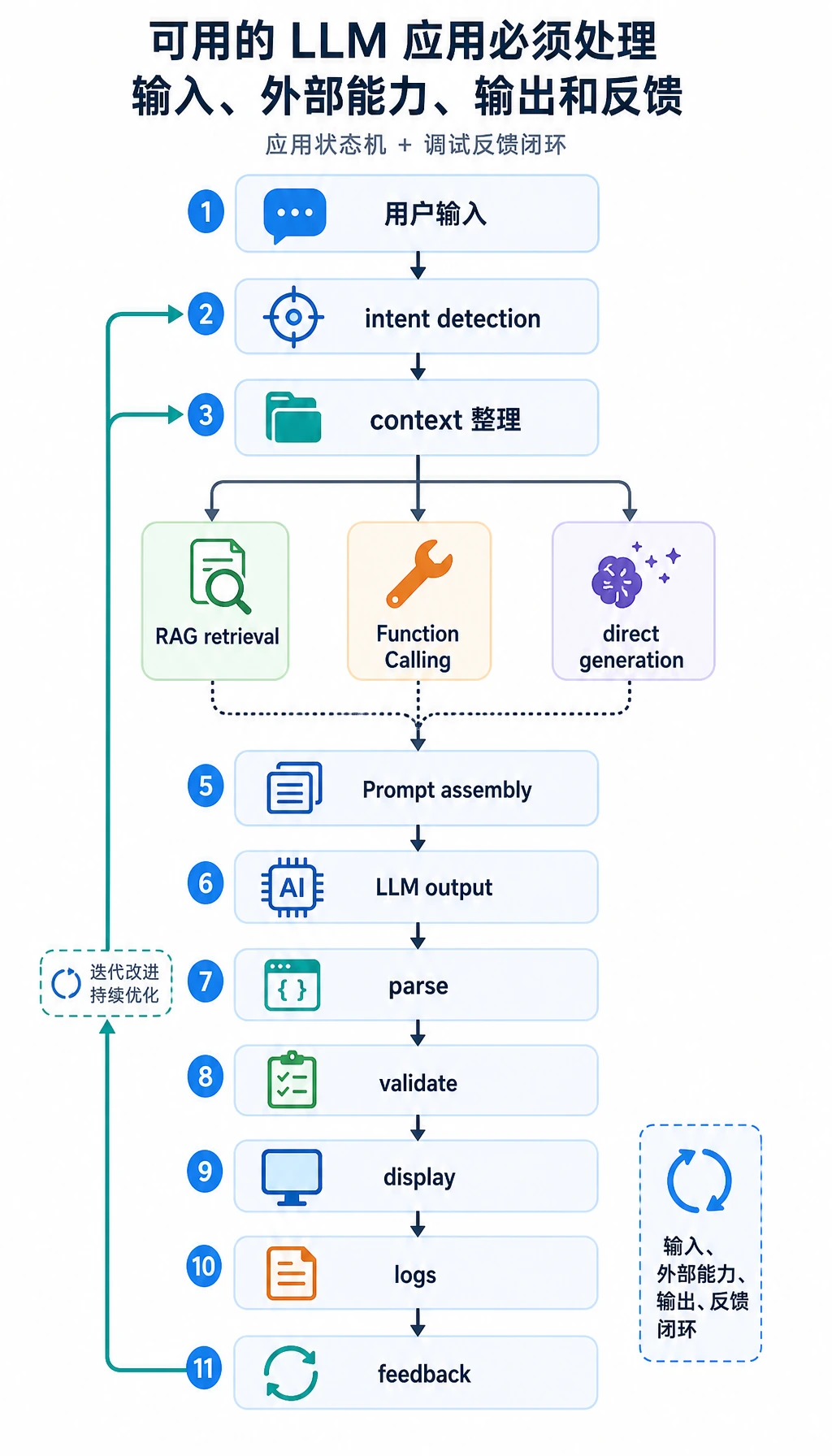
本章把一次模型调用升级成可维护的应用闭环:输入、Prompt/上下文、模型、可选工具、校验、输出、反馈。
跑一个工具分发检查
Section titled “跑一个工具分发检查”Function Calling 的意思是模型提出结构化动作参数,但应用必须负责校验和分发。
model_output = { "tool": "search_docs", "arguments": {"query": "RAG citations"},}
allowed_tools = { "search_docs": {"required": ["query"]}, "create_ticket": {"required": ["title", "priority"]},}
tool = model_output["tool"]required = allowed_tools[tool]["required"]validation_ok = all(name in model_output["arguments"] for name in required)
print("validation_ok:", validation_ok)print("dispatch:", tool if validation_ok else "block")预期输出:
validation_ok: Truedispatch: search_docs不要直接执行模型文本里的工具调用。要校验工具名、参数 schema、权限和失败路径。
按这个顺序学
Section titled “按这个顺序学”| 步骤 | 阅读 | 实操产出 |
|---|---|---|
| 1 | LLM API 实战 | 写一个带超时和错误处理的稳定调用封装 |
| 2 | 框架基础 | 拆分 Prompt、模型、工具、记忆、检索和解析器职责 |
| 3 | 函数调用 | 在分发前校验结构化工具参数 |
| 4 | Hugging Face 生态 | 判断托管、本地或浏览器端模型适合哪里 |
| 5 | 对话系统 | 保存会话状态、槽位、记忆和用户反馈 |
| 6 | 文档与模板应用 | 把解析、抽取和生成拆成模块 |
学完这一页,至少保留这张证据卡:
- 请求
- 输入、状态、工具/上下文,以及期望输出契约
- 已验证输出
- parser / schema 或业务规则检查的结果
- 追踪记录
- 模型调用、tool/function 调用、文档解析或对话状态
- 失败检查
- 格式无效、字段缺失、状态过时或工具错误
- 下一步动作
- Prompt、schema、状态、API 或解析改进
如果你能构建一个小助手闭环,包含一次 API 调用、一个可选工具调用、一个结构化输出和一条错误路径,就通过了本章。
本章出口小项目是课程问答与学习规划助手:分类用户请求,必要时检索知识,返回结构化建议,并记录反馈。
检查思路与讲解
- 合格答案要能追踪 query、chunks、检索分数、引用证据、最终回答和兜底行为。
- 证据应包含检索片段、source metadata、带引用的回答,以及至少一个空检索或误检索案例。
- 自检时要能判断失败来自 chunking、检索、排序、prompt 拼装、资料缺失,还是无依据生成。