9.5.7 MCP、A2A 与 Agent 协议层
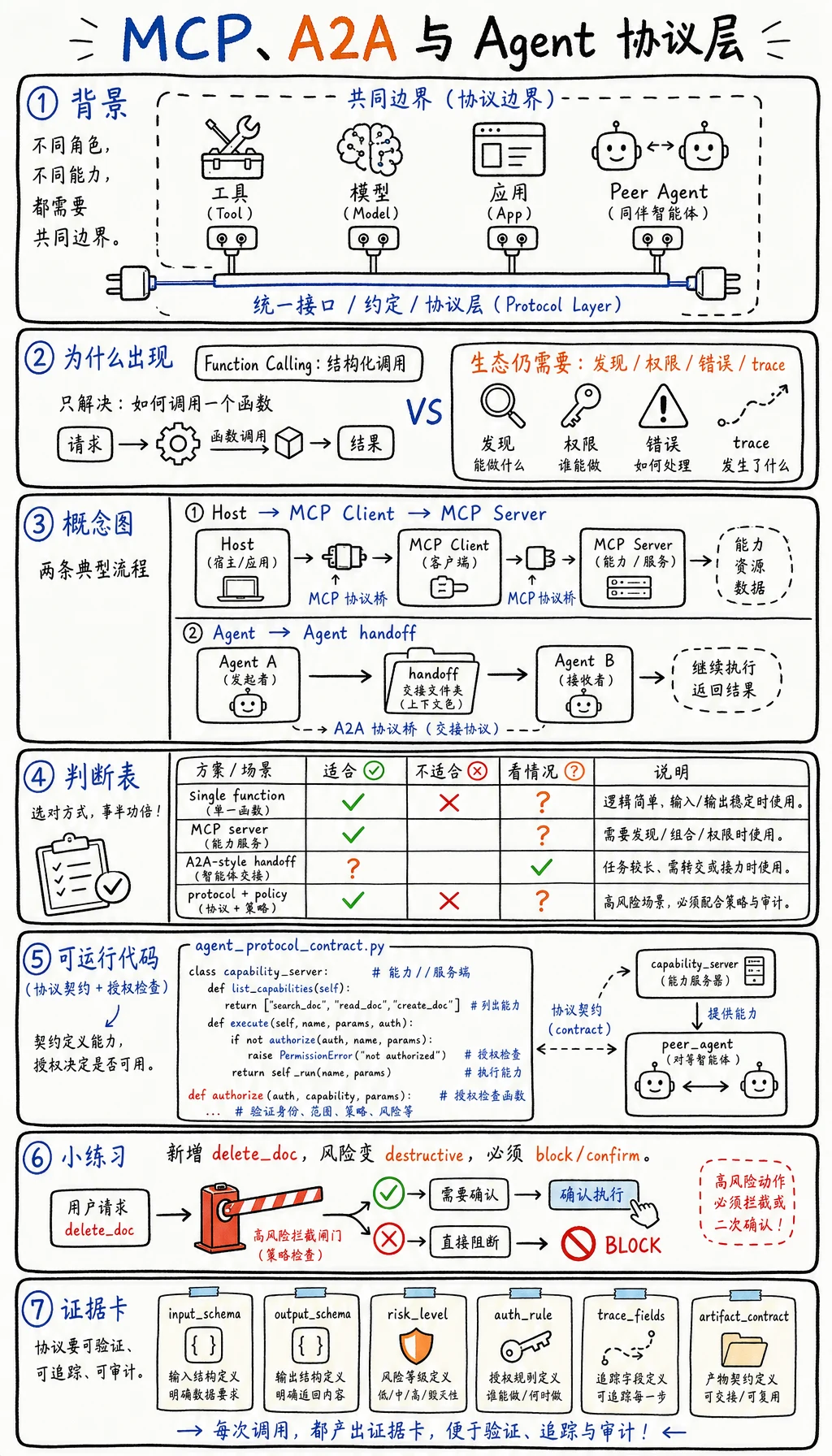
当每个工具、模型、应用和 Agent 都有自己的集成方式时,Agent 系统会迅速变乱。协议层的意义,是让能力发现、调用、权限和错误处理更可预测。
Model Context Protocol 主要用于把工具、资源和 prompt 模板暴露给模型应用。Agent-to-Agent 式协作解决的是邻近问题:一个 Agent 如何描述自己、接收任务、返回状态,并把产物交给另一个 Agent 或 Host。
不要先背产品名,先看边界:
MCP 式边界:应用或 Host 连接能力服务器A2A 式边界:一个 Agent 或 Host 与另一个 Agent 协商任务为什么这项技术会出现
Section titled “为什么这项技术会出现”Function Calling 让工具调用变得结构化,但没有解决生态系统问题。每个应用仍然要自己处理工具注册、鉴权、传输、错误形状和发现机制。
协议层出现,是因为团队需要回答:
- 有哪些工具或资源可用?
- 每个能力接受什么 schema?
- 谁有权调用?
- 调用失败时怎么表示?
- 另一个 Agent 能否理解同一个契约?
没有协议层,Agent 系统会变成大量一次性胶水代码。
| 层 | 核心问题 | 典型对象 | 需要防范的失败 |
|---|---|---|---|
| 工具 schema | 能调用什么? | JSON schema、输入/输出类型 | 参数含糊 |
| MCP server | 暴露哪些能力? | tools、resources、prompts | server 权限过大 |
| Agent card | 这个 Agent 会做什么? | skills、限制、交接格式 | 能力描述虚高或模糊 |
| Policy layer | 谁能调用什么? | allow/deny/confirm 规则 | 隐形提权 |
| Trace layer | 发生了什么? | 调用日志、产物 id、错误 | 无法调试交接 |
| 需求 | 使用模式 | 原因 |
|---|---|---|
| 把本地文件、数据库搜索或浏览器动作暴露给模型应用 | MCP server | 能力发现和稳定的 Host-Client-Server 形状 |
| 让一个专门 Agent 把工作交给另一个 | Agent-to-Agent 契约 | 接收方需要身份、任务形状、状态和产物 |
| 在一个应用内部调用单个函数 | Function calling | 更简单,足够本地工具使用 |
| 接入很多工具且有安全要求 | 协议 + policy layer | 只有发现能力,没有权限控制是不安全的 |
| 调试失败的多 Agent 运行 | Trace 和 artifact 契约 | 不能只看最终答案 |
可运行实验:构造能力契约
Section titled “可运行实验:构造能力契约”创建 agent_protocol_contract.py,用 Python 3.10 或更高版本运行。
import jsonfrom pathlib import Path
capability_server = { "name": "course-search-server", "protocol": "MCP-style", "tools": { "search_docs": { "input": ["query", "language"], "output": ["title", "url", "snippet"], "risk": "read", } }, "resources": ["course://chapter/{id}"],}
peer_agent = { "name": "qa-review-agent", "protocol": "A2A-style", "accepts_tasks": ["review_lesson", "check_links"], "artifact_contract": ["findings", "commands_run", "risk_notes"],}
request = {"caller": "course-builder", "action": "search_docs", "risk": "read"}
def authorize(requested_action, server): tool = server["tools"].get(requested_action) if not tool: return {"allowed": False, "reason": "unknown action"} if tool["risk"] != "read": return {"allowed": False, "reason": "requires human confirmation"} return {"allowed": True, "reason": "read-only capability"}
contract = { "server": capability_server["name"], "peer_agent": peer_agent["name"], "authorization": authorize(request["action"], capability_server), "handoff_required_fields": peer_agent["artifact_contract"],}
Path("agent_protocol_contract.json").write_text(json.dumps(contract, indent=2), encoding="utf-8")print(json.dumps(contract, indent=2))预期输出:
{ "server": "course-search-server", "peer_agent": "qa-review-agent", "authorization": { "allowed": true, "reason": "read-only capability" }, "handoff_required_fields": [ "findings", "commands_run", "risk_notes" ]}capability_server 描述 Host 可以发现和调用什么。重点是输入形状、输出形状和风险。
peer_agent 描述一个类似工作者的 Agent。它不只是工具,它接收任务并返回产物。
authorize() 是安全门。协议可以描述能力,但应用仍然需要自己的策略。
contract 把能力发现、授权和交接证据连接起来。
新增一个工具:
capability_server["tools"]["delete_doc"] = { "input": ["doc_id"], "output": ["deleted"], "risk": "destructive",}request["action"] = "delete_doc"然后把 request["action"] 改成 "delete_doc"。授权结果应该阻止或要求确认。如果没有阻止,说明 policy 太弱。
接入任何外部工具或 Agent 前,先写这张卡:
- Capability Name
- tool、resource、prompt 或 peer agent
- Input Schema
- 必填字段
- Output Schema
- 返回字段
- Risk Level
- read、write、external、destructive
- Auth Rule
- allow、deny 或 confirm
- Trace Fields
- request id、caller、target、result、error
- Artifact Contract
- 接收方必须返回什么
MCP 和 Agent-to-Agent 契约不是魔法,而是让能力边界变得可检查。用它们避免隐藏胶水代码,但一定要配合 policy 和 trace 证据。
检查理解
能解释工具 schema、MCP server 和 Agent 交接契约的区别,并指出授权应该放在哪里,就算通过本节。