6.7.3 训练监控与诊断
- 从曲线判断欠拟合、过拟合和训练不稳定。
- 检查 prediction distribution 和 gradient norm。
- 使用可重复的排查顺序。
- 根据证据决定下一组实验。
- 知道每次训练应该保存什么。
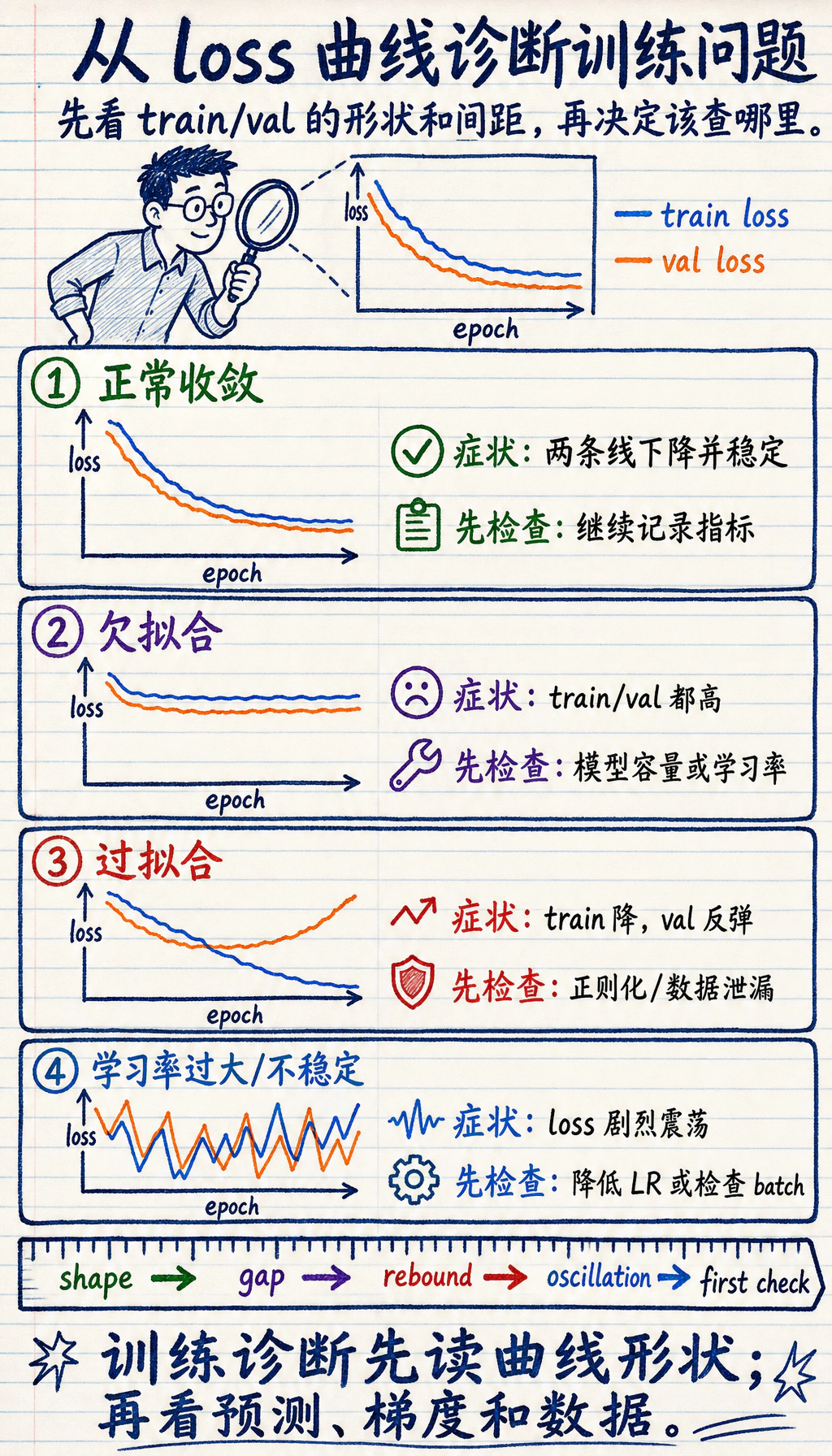
第一个问题不是“我要换成哪个模型”,而是:
训练证据里出现了什么现象?| 现象 | 可能方向 | 第一检查项 |
|---|---|---|
| train 和 val 都差 | 欠拟合 | learning rate、模型容量、数据质量 |
| train 变好但 val 变差 | 过拟合 | 正则、数据划分、augmentation |
| loss 上下跳 | 不稳定 | learning rate、batch size、梯度 |
| 预测几乎都是同一类 | collapse 或数据问题 | 标签、类别平衡、输出层 |
| 指标突然变化 | pipeline bug 或分布变化 | data loader、预处理、验证集划分 |

实验 1:分类曲线模式
Section titled “实验 1:分类曲线模式”histories = { "underfit_case": ([1.20, 1.08, 0.99, 0.94], [1.25, 1.13, 1.04, 1.02]), "overfit_case": ([0.90, 0.55, 0.31, 0.18], [0.92, 0.63, 0.68, 0.82]), "unstable_case": ([0.80, 1.65, 0.72, 1.48], [0.85, 1.70, 0.79, 1.55]),}
def diagnose(train, val): train_drop = train[0] - train[-1] val_best = min(val)
if max(train) - min(train) > 0.8: return "possible_lr_too_high_or_unstable_batches" if train[-1] > 0.8 and val[-1] > 0.8: return "possible_underfitting" if train_drop > 0.3 and val[-1] > val_best + 0.1: return "possible_overfitting" return "need_more_signals"
print("curve_diagnosis")for name, (train, val) in histories.items(): print(name, "->", diagnose(train, val))预期输出:
curve_diagnosisunderfit_case -> possible_underfittingoverfit_case -> possible_overfittingunstable_case -> possible_lr_too_high_or_unstable_batches这段代码不是为了替代人的判断。它训练的是第一步习惯:先按可见现象归类,再改系统。
实验 2:检查梯度和预测分布
Section titled “实验 2:检查梯度和预测分布”只看 loss 不够。模型可能 loss 看起来还行,却对所有样本预测同一类。
import torchfrom torch import nn
torch.manual_seed(5)
X = torch.randn(12, 3)y = torch.tensor([0, 1, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0])
model = nn.Sequential(nn.Linear(3, 4), nn.ReLU(), nn.Linear(4, 2))loss_fn = nn.CrossEntropyLoss()
logits = model(X)loss = loss_fn(logits, y)loss.backward()
grad_norm = 0.0for p in model.parameters(): if p.grad is not None: grad_norm += p.grad.pow(2).sum().item()grad_norm = grad_norm**0.5
preds = logits.argmax(dim=1)counts = torch.bincount(preds, minlength=2)confidence = torch.softmax(logits, dim=1).max(dim=1).values.mean().item()
print("training_signals")print("loss:", round(loss.item(), 3))print("grad_norm:", round(grad_norm, 3))print("pred_counts:", counts.tolist())print("avg_confidence:", round(confidence, 3))预期输出:
training_signalsloss: 0.687grad_norm: 0.445pred_counts: [0, 12]avg_confidence: 0.69
最重要的信号是 pred_counts: [0, 12]。这个初始模型把所有样本都预测成 class 1。真实训练中如果这个模式持续存在,就要检查类别不平衡、标签、输出层 shape 和 loss 设置。
改模型结构前,先按这个顺序查:
- 曲线:train/val loss 和指标。
- 预测:类别计数、置信度、最好和最坏样本。
- 梯度:norm、NaN/Inf、爆炸或接近 0 的更新。
- 数据:标签、泄漏、划分、预处理、augmentation。
- 超参数:learning rate、batch size、正则。
- 模型:容量、架构、初始化。
这个顺序故意很朴素,也正因为朴素,所以可靠。
训练时要保存什么
Section titled “训练时要保存什么”| 产物 | 为什么保存 |
|---|---|
| train/val 曲线 | 诊断趋势和过拟合 |
| config 和 seed | 复现训练 |
| best checkpoint | 不重训也能比较 |
| 预测样本 | 直接观察失败 |
| 梯度统计 | 早发现不稳定 |
| 数据划分版本 | 查泄漏或漂移 |
每次诊断都留下一条“症状到动作”笔记:
- 曲线模式
- 欠拟合、过拟合、不稳定、崩溃或不清楚
- 预测信号
- 类别计数和置信度
- 梯度信号
- 范数加上 NaN/Inf 检查
- 数据检查
- 标签、划分、泄漏、预处理
- 选择动作
- 一个有针对性的下一轮实验
- 成功规则
- 什么指标或工件能证明修复有效
从诊断到动作
Section titled “从诊断到动作”| 诊断 | 第一动作 |
|---|---|
| 可能欠拟合 | 合理提高 LR,训练更久,增大容量,检查标签 |
| 可能过拟合 | early stopping,更强正则,更多数据,augmentation |
| 训练不稳定 | 降低 LR,增大 batch,加 gradient clipping |
| 预测塌缩 | 检查类别平衡、target encoding、输出 shape、loss function |
| 数据 pipeline 问题 | 打印 sample batch,验证预处理和划分 |
| 错误 | 修复 |
|---|---|
| 只看最终准确率 | 保存完整曲线和 best epoch |
| 查数据前就换模型 | 先检查 sample batch 和标签 |
| 忽略预测分布 | 打印类别计数或输出摘要 |
| 以为 train loss 低就成功 | 对比 validation 和失败样本 |
| 一次修很多东西 | 选一个动作并验证结果 |
- 增加一个 train 和 val 都改善的
good_casehistory。 - 把实验 2 改成 3 个类别。
torch.bincount要怎么变? - 增加一个
has_nan_grad检查。 - 为实验 1 的每种诊断写一个下一步动作。
- 保存一个 CSV 风格日志:
epoch,train_loss,val_loss,val_acc。
参考实现与讲解
good_case应该表现为 train loss 下降、val loss 下降或持平、val acc 上升,说明训练和泛化同步改善。- 三分类时可使用
torch.bincount(labels, minlength=3),确保没有出现的类别也有计数位置。 has_nan_grad可以遍历参数的p.grad,检查torch.isnan(p.grad).any(),发现后立刻停止训练并记录 batch。- 过拟合时优先加数据、正则或早停;欠拟合时增大模型或训练更久;不稳定时先查学习率和数值问题。
- CSV 日志能让训练过程可追踪,也方便画曲线和比较不同实验。
- 现象不是根因。
- 曲线是第一诊断界面。
- 预测和梯度能暴露 loss 隐藏的问题。
- 查数据要早于改架构。
- 好诊断最后应该落到一个有针对性的下一轮实验。