8.2.2 本地模型运行
- 理解为什么很多场景会优先考虑本地模型
- 理解模型大小、量化和硬件条件之间的关系
- 分清 CPU 跑、GPU 跑和量化跑的基本差别
- 看懂一个最小本地推理流程
- 建立“什么时候该本地跑、什么时候更适合 API”的判断
先建立一张地图
Section titled “先建立一张地图”本地模型这节最适合新人的理解顺序不是“先选模型名”,而是先看清:
flowchart LR A["业务需求"] --> B["隐私 / 成本 / 延迟 / 离线要求"] B --> C["决定是否考虑本地模型"] C --> D["再看资源是否匹配"] D --> E["再决定 CPU / GPU / 量化路线"]所以这节真正想解决的是:
- 为什么会有人放着现成 API 不用,反而去本地跑
- 本地跑到底是在换什么
一个更适合新人的总类比
Section titled “一个更适合新人的总类比”你可以把云 API 和本地模型理解成:
- 打车
- 和自己买车
打车的好处是:
- 省心
- 随叫随到
自己买车的好处是:
- 更可控
- 长期可能更省
- 某些情况下更安全
但你也要自己承担:
- 保养
- 停车
- 故障处理
本地模型和云 API 的关系,很像这种权衡。
一、为什么要考虑本地模型?
Section titled “一、为什么要考虑本地模型?”先看云端 API 的优点
Section titled “先看云端 API 的优点”云 API 的优势很明显:
- 开箱即用
- 模型通常更强
- 运维压力更小
所以很多项目起步时,云 API 往往是最省心的选择。
但为什么还是会有人坚持本地跑?
Section titled “但为什么还是会有人坚持本地跑?”常见原因通常是:
- 数据不能离开本地或企业内网
- API 成本累积太快
- 需要离线可用
- 想更强地控制模型和推理链路
也就是说,本地模型的核心价值不是“更高级”,而是:
在质量、成本、隐私和可控性之间重新做一套权衡。
二、先建立一个最重要的现实直觉:模型大小不是抽象数字
Section titled “二、先建立一个最重要的现实直觉:模型大小不是抽象数字”参数量直接影响资源占用
Section titled “参数量直接影响资源占用”当你看到一个模型是:
- 7B
- 13B
- 70B
这些不只是宣传标签,它们通常意味着:
- 内存 / 显存占用差很多
- 加载时间差很多
- 推理速度也会差很多
一个粗略的资源示意
Section titled “一个粗略的资源示意”runtime_options = [ {"name": "small_quantized_model", "memory_gb": 4, "quality": "basic"}, {"name": "medium_quantized_model", "memory_gb": 8, "quality": "good"}, {"name": "larger_model", "memory_gb": 16, "quality": "better"}]
for item in runtime_options: print(item)预期输出:
{'name': 'small_quantized_model', 'memory_gb': 4, 'quality': 'basic'}{'name': 'medium_quantized_model', 'memory_gb': 8, 'quality': 'good'}{'name': 'larger_model', 'memory_gb': 16, 'quality': 'better'}这段代码真正想提醒你什么?
Section titled “这段代码真正想提醒你什么?”不是让你记住数字,而是让你先建立一个非常实用的判断:
模型能不能本地跑,第一层往往先是资源匹配问题。
不是“想不想跑”,而是“机器扛不扛得住”。
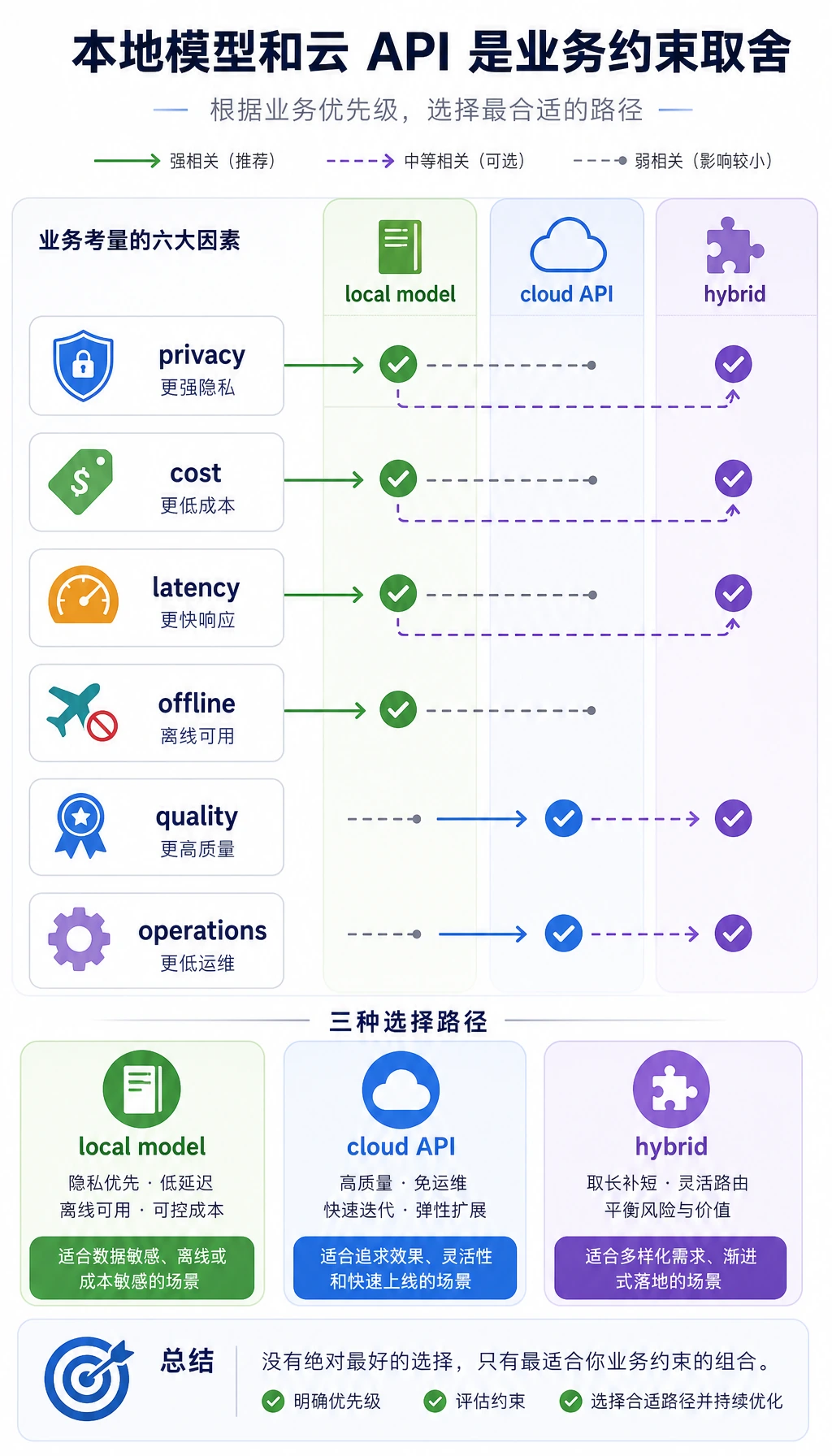
一个很适合初学者先记的决策表
Section titled “一个很适合初学者先记的决策表”| 优先目标 | 先试路线 |
|---|---|
| 快速原型 | 云 API |
| 隐私和内网 | 本地模型 |
| 长期成本 | 本地模型或混合方案 |
| 最强效果 | 往往先试云 API |
这个表不是绝对规则,但很适合新人先建立一个现实判断:
- 部署路线首先是业务决策,不只是技术偏好
三、量化为什么总是和本地模型绑定出现?
Section titled “三、量化为什么总是和本地模型绑定出现?”因为大家都想把模型塞进更小的机器
Section titled “因为大家都想把模型塞进更小的机器”量化最粗糙但最好懂的理解方式是:
用更低精度表示模型参数,换更低的内存占用。
一个最小示意
Section titled “一个最小示意”params = 7_000_000_000 # 70亿参数,示意
precisions = { "fp16": 2.0, "int8": 1.0, "int4": 0.5}
for name, bytes_per_param in precisions.items(): memory_gb = params * bytes_per_param / (1024 ** 3) print(name, "rough memory GB =", round(memory_gb, 2))预期输出:
fp16 rough memory GB = 13.04int8 rough memory GB = 6.52int4 rough memory GB = 3.26这只是非常粗略的参数内存估算。真实运行时还会有 KV cache、临时 buffer、tokenizer/runtime 开销和服务队列等额外占用。
量化的好处和代价
Section titled “量化的好处和代价”好处:
- 更容易本地跑
- 更容易压到端侧或弱机器
代价:
- 精度可能会掉一点
- 某些任务上更敏感
所以量化也是典型的工程权衡,而不是无代价魔法。
再看一个最小“资源不够时怎么办”示例
Section titled “再看一个最小“资源不够时怎么办”示例”constraints = { "memory_gb": 8, "need_low_latency": False, "privacy_sensitive": True,}
def suggest_runtime(constraints): if constraints["privacy_sensitive"] and constraints["memory_gb"] <= 8: return "优先考虑小型量化本地模型。" if constraints["need_low_latency"] and constraints["memory_gb"] >= 16: return "优先考虑 GPU 本地推理。" return "先用云 API 做原型,再评估是否迁移到本地。"
print(suggest_runtime(constraints))预期输出:
优先考虑小型量化本地模型。这个示例很适合初学者,因为它会提醒你:
- 本地部署很多时候不是先选模型
- 而是先看约束
四、CPU 跑和 GPU 跑到底差在哪?
Section titled “四、CPU 跑和 GPU 跑到底差在哪?”CPU 跑的特点
Section titled “CPU 跑的特点”优点:
- 普通机器都有
- 部署门槛低
缺点:
- 慢
GPU 跑的特点
Section titled “GPU 跑的特点”优点:
- 更快
- 更适合较大模型
缺点:
- 成本高
- 部署环境要求高
一个实用判断
Section titled “一个实用判断”如果你的场景是:
- 个人工具
- 小流量实验
- 离线助手
那 CPU 跑小模型可能就够。
如果你的场景是:
- 多轮交互
- 用户等待敏感
- 模型稍大
那 GPU 或更专业 runtime 会更现实。
五、一个最小本地推理流程示意
Section titled “五、一个最小本地推理流程示意”为什么先用模拟运行时?
Section titled “为什么先用模拟运行时?”这里我们先不用真实大模型,而是写一个模拟运行时(mock runtime),目的是把“加载 -> 推理 -> 返回”的运行逻辑看清楚。
class LocalModelRuntime: def __init__(self, model_name): self.model_name = model_name self.loaded = False
def load(self): self.loaded = True print(f"loaded {self.model_name}")
def generate(self, prompt): if not self.loaded: raise RuntimeError("model not loaded") return f"[{self.model_name}] local reply to: {prompt}"
runtime = LocalModelRuntime("small-local-model")runtime.load()print(runtime.generate("退款政策是什么?"))预期输出:
loaded small-local-model[small-local-model] local reply to: 退款政策是什么?这段代码在教什么?
Section titled “这段代码在教什么?”它在教你本地模型运行最基础的三件事:
- 模型要先加载
- 推理请求要走到 runtime
- 结果再交给上层系统
这看起来很简单,但它已经非常接近真实推理系统的最小骨架。
新人第一次做项目时,怎么决定要不要本地跑?
Section titled “新人第一次做项目时,怎么决定要不要本地跑?”一个更稳的顺序通常是:
- 先问自己是否真的有隐私 / 离线 / 成本约束
- 再问当前机器是否真的扛得住
- 如果只是做原型,优先考虑云 API
- 如果要控制链路或长期压成本,再认真考虑本地模型
这样通常比一开始就追“本地部署很酷”更现实。
如果把它做成项目或方案,最值得展示什么
Section titled “如果把它做成项目或方案,最值得展示什么”最值得展示的通常不是:
- “模型跑起来了”
而是:
- 为什么选本地而不是 API
- 硬件和模型大小如何匹配
- 是否用了量化
- 冷启动、延迟、成本的权衡
- 这套方案适合什么场景,不适合什么场景
这样别人会更容易看出:
- 你理解的是部署决策
- 不只是跑通了一次推理
6、真正难的不是“生成成功”,而是“长期稳定运行”
Section titled “6、真正难的不是“生成成功”,而是“长期稳定运行””一旦走到真实系统,你会遇到这些更现实的问题:
- 冷启动要多久
- 模型常驻会占多少资源
- 一台机器能扛多少并发
- 切模型要不要重载
第一次加载模型通常很慢。 这对服务型系统是大问题。
常驻进程问题
Section titled “常驻进程问题”为了减少冷启动,你常常会让模型常驻内存。 但这又带来:
- 更高资源长期占用
所以你会发现:
本地模型运行真正难的地方,不在“调一次成功”,而在“怎样让它像服务一样活着”。
7、什么时候本地模型特别值得?
Section titled “7、什么时候本地模型特别值得?”- 企业内网
- 隐私敏感内容
- API 成本压力大
- 弱网络 / 离线场景
- 需要更强控制链路
- 团队没运维能力
- 任务强依赖最前沿大模型质量
- 用户量很小、API 已经足够省事
这时云端模型可能反而更合适。
8、一个很实用的决策问题清单
Section titled “8、一个很实用的决策问题清单”在决定本地跑之前,你可以先问:
- 我最在意的是成本、隐私,还是模型质量?
- 我有没有足够的硬件?
- 我愿不愿意承担部署和维护复杂度?
- API 方案是不是已经够好?
如果这些问题答清楚了,本地模型方案通常就不会太盲目。
9、初学者最常踩的坑
Section titled “9、初学者最常踩的坑”只看模型参数,不看 runtime
Section titled “只看模型参数,不看 runtime”同一个模型,换个 runtime 体验可能差很多。
一开始就追大模型
Section titled “一开始就追大模型”很多本地场景,其实小模型已经够用。
以为“跑起来”就等于“适合上线”
Section titled “以为“跑起来”就等于“适合上线””上线后还要看:
- 稳定性
- 监控
- 并发
- 成本
学完这一页,至少保留这张证据卡:
- 运行时选择
- 本地模型、推理服务器,或统一 API
- 请求契约
- 端点、负载、输出格式,以及错误形状
- 延迟或成本
- 一个测量值或估计值
- 失败检查
- 超时、内存压力、模型不匹配或版本漂移
- 回滚方案
- 备用模型、重试策略,或流量切换
这一节最重要的不是记住几个模型名,而是建立一个稳定直觉:
本地模型运行的核心,是在“质量、成本、隐私、硬件、维护复杂度”之间做现实权衡。
它不是云 API 的简单替代,而是一整套不同的部署选择。
- 用你当前机器条件,写出一个你认为合理的本地模型运行方案。
- 用自己的话解释:为什么量化会在本地模型运行里频繁出现?
- 为什么说“模型文件能加载”不等于“模型服务能上线”?
- 如果你的系统很重隐私但团队运维能力弱,你会怎么取舍?
解题思路与讲解
- 合理方案应写清模型规模、量化等级、运行框架、内存/显存预算、预期延迟和 fallback。对普通笔记本来说,用小型量化模型做验证,再保留云端/API fallback,通常比假装本地能承载前沿大模型更现实。
- 量化用更少 bit 存储权重,能降低内存占用和带宽压力。本地运行时,VRAM/RAM 和内存带宽经常是瓶颈。
- 上线还需要延迟目标、并发上限、监控、错误处理、模型预热、安全、回滚和成本规划。
- 隐私要求高但运维弱的团队,可以把敏感检索和数据留在本地,把非敏感生成交给托管模型,并加上脱敏、审计和边界控制。全量自托管不一定更安全,前提是团队得真的运维得住。