9.7.4 任务分配与协调
- 理解多 Agent 中任务分配为什么是核心问题
- 分清静态分配、动态分配、能力路由这几种常见方式
- 理解协调里最常见的冲突和解决方式
- 看懂一个小型任务调度示例
为什么多 Agent 最难的不只是“多”
Section titled “为什么多 Agent 最难的不只是“多””多 Agent 最大风险:不是没人干活,而是大家都干不对
Section titled “多 Agent 最大风险:不是没人干活,而是大家都干不对”多 Agent 系统里常见失败不只是:
- 没人做
更常见的是:
- 两个人重复做
- 错的人接了任务
- 任务顺序错了
- 结果回不来
所以真正的重点是:
怎样让对的人,在对的时机,做对的事。
一个生活类比
Section titled “一个生活类比”像做一个小项目:
- 有人负责找资料
- 有人负责写代码
- 有人负责评审
如果分配乱了,再聪明的人也会低效。
最常见的三种任务分配方式
Section titled “最常见的三种任务分配方式”任务和角色提前写死。
例如:
- 检索一定交给检索者
- 写作一定交给撰写者
优点:
- 稳定
- 易调试
缺点:
- 灵活性差
系统根据当前任务内容决定交给谁。
例如:
- 法律问题交给 legal_agent
- 技术问题交给 tech_agent
优点:
- 更灵活
缺点:
- 路由错了就会连锁出错
不是按名字分,而是按能力特征分:
- 谁更适合检索?
- 谁更适合总结?
- 谁更适合审查?
这更像“按岗位能力派活”。
一个最小任务分配示例
Section titled “一个最小任务分配示例”agents = { "researcher": {"skills": ["search", "retrieve"]}, "writer": {"skills": ["write", "summarize"]}, "reviewer": {"skills": ["review", "critique"]}}
tasks = [ {"name": "查资料", "skill": "search"}, {"name": "写总结", "skill": "write"}, {"name": "做评审", "skill": "review"}]
def assign_task(task, agents): for agent_name, profile in agents.items(): if task["skill"] in profile["skills"]: return agent_name return None
for task in tasks: print(task["name"], "->", assign_task(task, agents))预期输出:
查资料 -> researcher写总结 -> writer做评审 -> reviewer这段代码在教你什么?
Section titled “这段代码在教你什么?”它在教你一个非常重要的抽象:
任务分配不是随机发活,而是“任务需求”和“Agent 能力”之间的匹配。
任务协调不只是分配,还包括顺序控制
Section titled “任务协调不只是分配,还包括顺序控制”有些任务不能并行
Section titled “有些任务不能并行”例如:
- 先查资料
- 再写总结
- 最后再评审
如果顺序反了,系统就会乱。
一个最小顺序调度示例
Section titled “一个最小顺序调度示例”dependencies = { "retrieve": [], "write": ["retrieve"], "review": ["write"]}
done = set()execution_order = []
while len(done) < len(dependencies): for task, need in dependencies.items(): if task not in done and all(n in done for n in need): done.add(task) execution_order.append(task)
print(execution_order)输出会是:
['retrieve', 'write', 'review']这就是多 Agent 协调里很重要的一层: 不仅知道谁做,还要知道先后顺序。
任务协调里最常见的冲突
Section titled “任务协调里最常见的冲突”两个 Agent 都去做同一件事。
一个 Agent 说“可以退款”,另一个说“不可以退款”。
writer 还以为资料没找到,但 retriever 其实已经返回了。
为什么这些问题很常见?
Section titled “为什么这些问题很常见?”因为多 Agent 本质上就是“分布式系统的小型版”。 只要一旦分工,就会出现:
- 同步
- 冲突
- 收敛
这些问题。
一个带冲突解决思路的小例子
Section titled “一个带冲突解决思路的小例子”results = { "agent_a": {"decision": "approve", "confidence": 0.7}, "agent_b": {"decision": "reject", "confidence": 0.9}}
def resolve_conflict(results): best_agent = max(results.items(), key=lambda x: x[1]["confidence"]) return { "final_decision": best_agent[1]["decision"], "source": best_agent[0] }
print(resolve_conflict(results))预期输出:
{'final_decision': 'reject', 'source': 'agent_b'}为什么这只是最小版?
Section titled “为什么这只是最小版?”真实系统里,冲突解决可能会用:
- 置信度
- 投票
- 审核者裁决
- 监督者最终拍板
但你至少要先意识到:
多 Agent 一定会有冲突,冲突不是异常,而是常态。
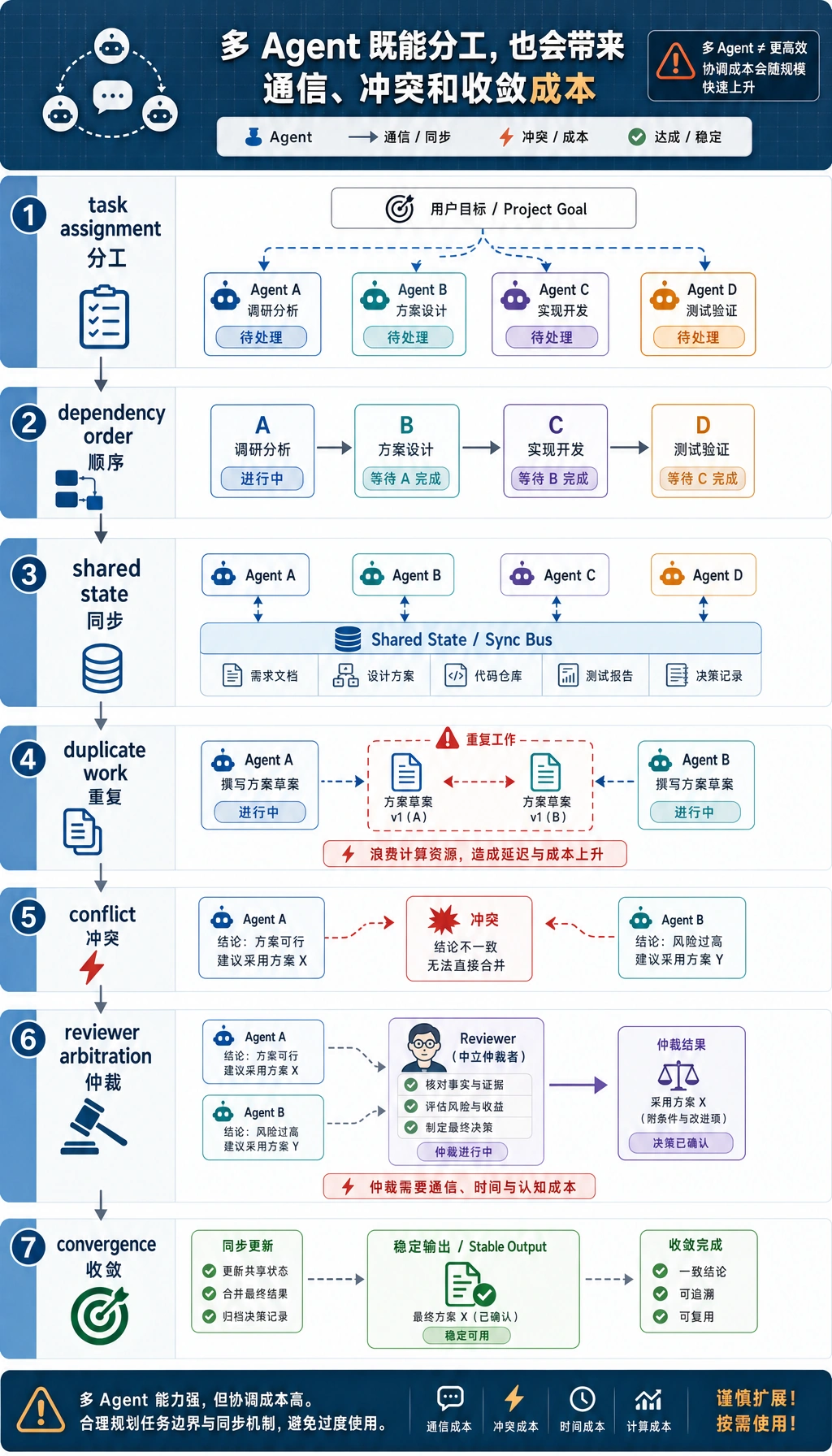
任务协调和通信有什么关系?
Section titled “任务协调和通信有什么关系?”通信解决的是:
- 信息怎么传
协调解决的是:
- 任务怎么排
- 谁负责什么
- 出现冲突怎么收敛
所以可以记成:
- 通信更像“线路”
- 协调更像“调度”
两者缺一不可。
真实系统里常见的协调策略
Section titled “真实系统里常见的协调策略”由 supervisor 统一决定任务流转。
优点:
- 最容易管控
Agent 之间互相提议、协商。
优点:
- 灵活
缺点:
- 难调
大方向由 supervisor 控制,细节由 worker 自主。
这在实际工程里往往是个比较平衡的选择。
初学者最常踩的坑
Section titled “初学者最常踩的坑”只分工,不设计收尾
Section titled “只分工,不设计收尾”任务做了一半没人负责收尾,是非常常见的问题。
只设计成功路径
Section titled “只设计成功路径”一旦有 Agent 超时、失败、冲突,系统就乱了。
以为“更多 Agent = 更高效率”
Section titled “以为“更多 Agent = 更高效率””如果协调做不好,更多 Agent 只会带来更多管理成本。
学完这一页,至少保留这张证据卡:
- 角色
- 负责人、执行者、评审者,或专家职责
- 消息契约
- artifact、request、response 和交接状态
- 协同
- 路由、任务拆分、冲突解决和最终负责人
- 失败检查
- 重复工作、上下文丢失、没有明确负责人或消息循环
- 评估动作
- 将多 Agent 结果与单 Agent 基线对比
这一节最重要的不是把任务“分出去”,而是理解:
任务分配与协调的核心,是让任务、角色、顺序和冲突处理形成一个能收敛的系统。
这才是多 Agent 从“看起来热闹”走向“真正高效协作”的关键。
- 给任务分配示例再加一个
plannerAgent,并让它决定执行顺序。 - 设计一个“检索 -> 写作 -> 审核 -> 修订”的协调流程。
- 想一想:如果两个 Agent 结论冲突,你更倾向于投票、置信度裁决,还是审核者拍板?为什么?
- 用自己的话解释:为什么说多 Agent 协调本质上很像一个小型任务调度系统?
参考实现与讲解
- planner Agent 应生成带依赖关系的有序任务列表,例如先 retrieve,有证据后 write,有 draft 后 review,只有 review 要求修改时才 revise。
- 协调流程可以是:retrieve evidence -> write draft with citations -> review correctness and gaps -> revise rejected parts -> final check。
- 冲突结论要按风险选择仲裁方式。低风险意见可投票;有可度量证据时可参考 confidence;需要标准和责任时,更适合让 reviewer 判断。
- 多 Agent 协调像任务调度系统,因为它要管理依赖、资源使用、顺序、重试、停止条件和最终验收。