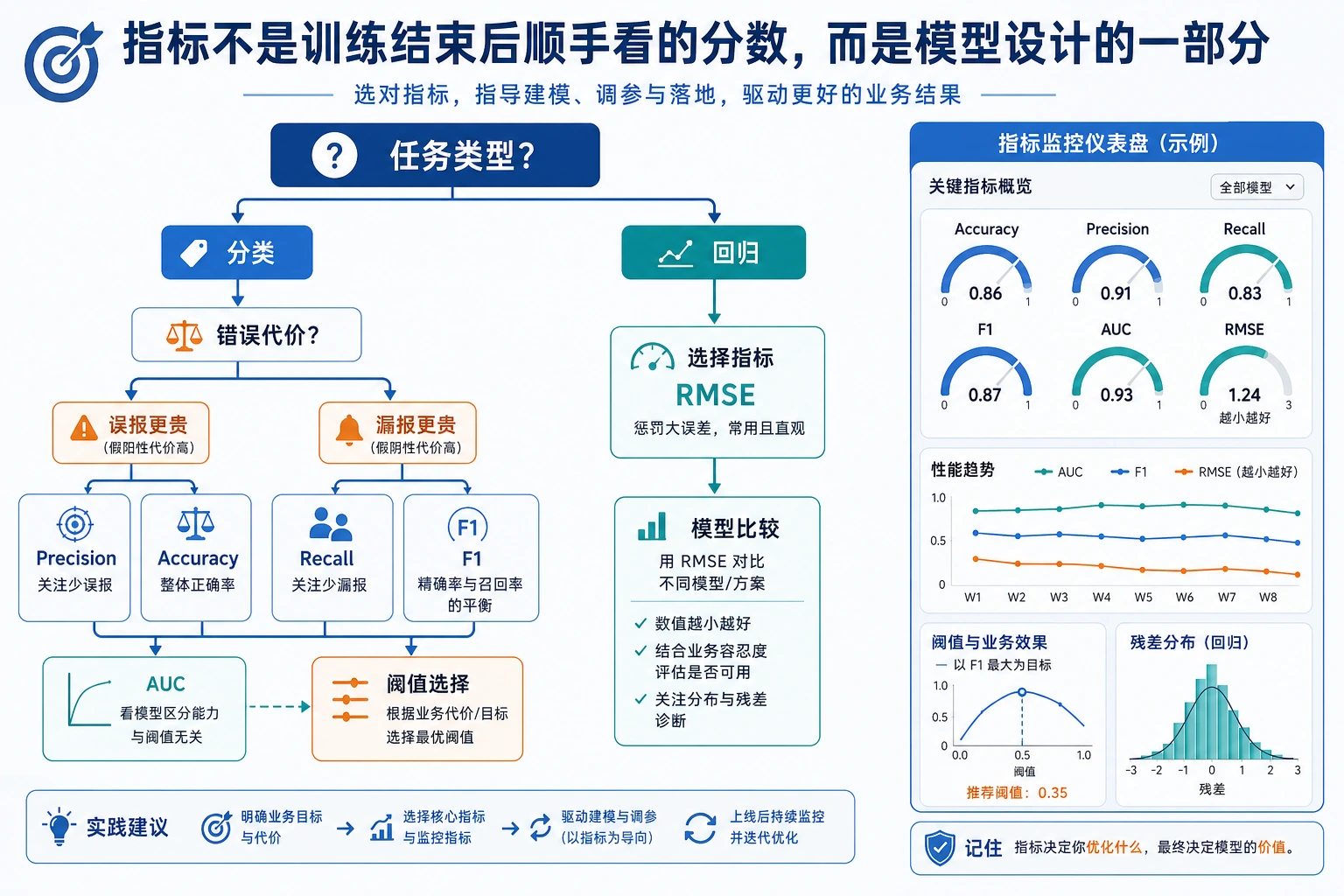
5.4.2 评估指标
你会做出什么
Section titled “你会做出什么”这一节会完成一个评估实验:
- 在不平衡分类中看清 accuracy 陷阱;
- 调整阈值,并读取误报/漏报;
- 比较 ROC AUC 与 average precision;
- 用 MAE、RMSE、R2 评估回归;
- 从产品成本选择指标,而不是凭习惯。
先看图:
| 术语 | 实用含义 |
|---|---|
TP | true positive,真实为正且预测为正 |
FP | false positive,真实为负但预测为正 |
FN | false negative,真实为正但漏掉 |
precision | 预测为正的样本里,有多少真的为正 |
recall | 真实为正的样本里,找回了多少 |
F1 | precision 和 recall 的调和平均 |
ROC AUC | 多个阈值下的排序质量;正类很少时可能显得乐观 |
average_precision | precision-recall 曲线面积;正类稀少时通常更有参考价值 |
MAE | 回归平均绝对误差 |
RMSE | 均方根误差,对大错误惩罚更重 |
python -m pip install -U scikit-learn运行完整实验
Section titled “运行完整实验”新建 metrics_lab.py:
from sklearn.datasets import load_diabetes, make_classificationfrom sklearn.dummy import DummyClassifier, DummyRegressorfrom sklearn.linear_model import LinearRegression, LogisticRegressionfrom sklearn.metrics import ( accuracy_score, average_precision_score, confusion_matrix, f1_score, mean_absolute_error, mean_squared_error, precision_score, r2_score, recall_score, roc_auc_score,)from sklearn.model_selection import train_test_splitfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScaler
X, y = make_classification( n_samples=1200, n_features=12, n_informative=5, n_redundant=2, weights=[0.92, 0.08], class_sep=1.2, random_state=42,)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y)
baseline = DummyClassifier(strategy="most_frequent")baseline.fit(X_train, y_train)base_pred = baseline.predict(X_test)print("classification_baseline")print(f"accuracy={accuracy_score(y_test, base_pred):.3f}")print(f"precision={precision_score(y_test, base_pred, zero_division=0):.3f}")print(f"recall={recall_score(y_test, base_pred):.3f}")
model = Pipeline([ ("scale", StandardScaler()), ("clf", LogisticRegression(max_iter=2000, random_state=42)),])model.fit(X_train, y_train)prob = model.predict_proba(X_test)[:, 1]
print("threshold_lab")for threshold in [0.2, 0.5, 0.8]: pred = (prob >= threshold).astype(int) tn, fp, fn, tp = confusion_matrix(y_test, pred).ravel() print( f"threshold={threshold:.1f} " f"accuracy={accuracy_score(y_test, pred):.3f} " f"precision={precision_score(y_test, pred, zero_division=0):.3f} " f"recall={recall_score(y_test, pred):.3f} " f"f1={f1_score(y_test, pred):.3f} " f"fp={fp} fn={fn}" )print(f"roc_auc={roc_auc_score(y_test, prob):.3f}")print(f"average_precision={average_precision_score(y_test, prob):.3f}")
print("regression_lab")X, y = load_diabetes(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42)for name, reg in [ ("mean_baseline", DummyRegressor(strategy="mean")), ("linear", LinearRegression()),]: reg.fit(X_train, y_train) pred = reg.predict(X_test) rmse = mean_squared_error(y_test, pred) ** 0.5 print( f"{name:<13} " f"mae={mean_absolute_error(y_test, pred):.1f} " f"rmse={rmse:.1f} " f"r2={r2_score(y_test, pred):.3f}" )运行:
python metrics_lab.py预期输出:
classification_baselineaccuracy=0.917precision=0.000recall=0.000threshold_labthreshold=0.2 accuracy=0.907 precision=0.462 recall=0.720 f1=0.562 fp=21 fn=7threshold=0.5 accuracy=0.943 precision=0.833 recall=0.400 f1=0.541 fp=2 fn=15threshold=0.8 accuracy=0.923 precision=1.000 recall=0.080 f1=0.148 fp=0 fn=23roc_auc=0.889average_precision=0.660regression_labmean_baseline mae=65.5 rmse=74.9 r2=-0.014linear mae=41.5 rmse=53.4 r2=0.485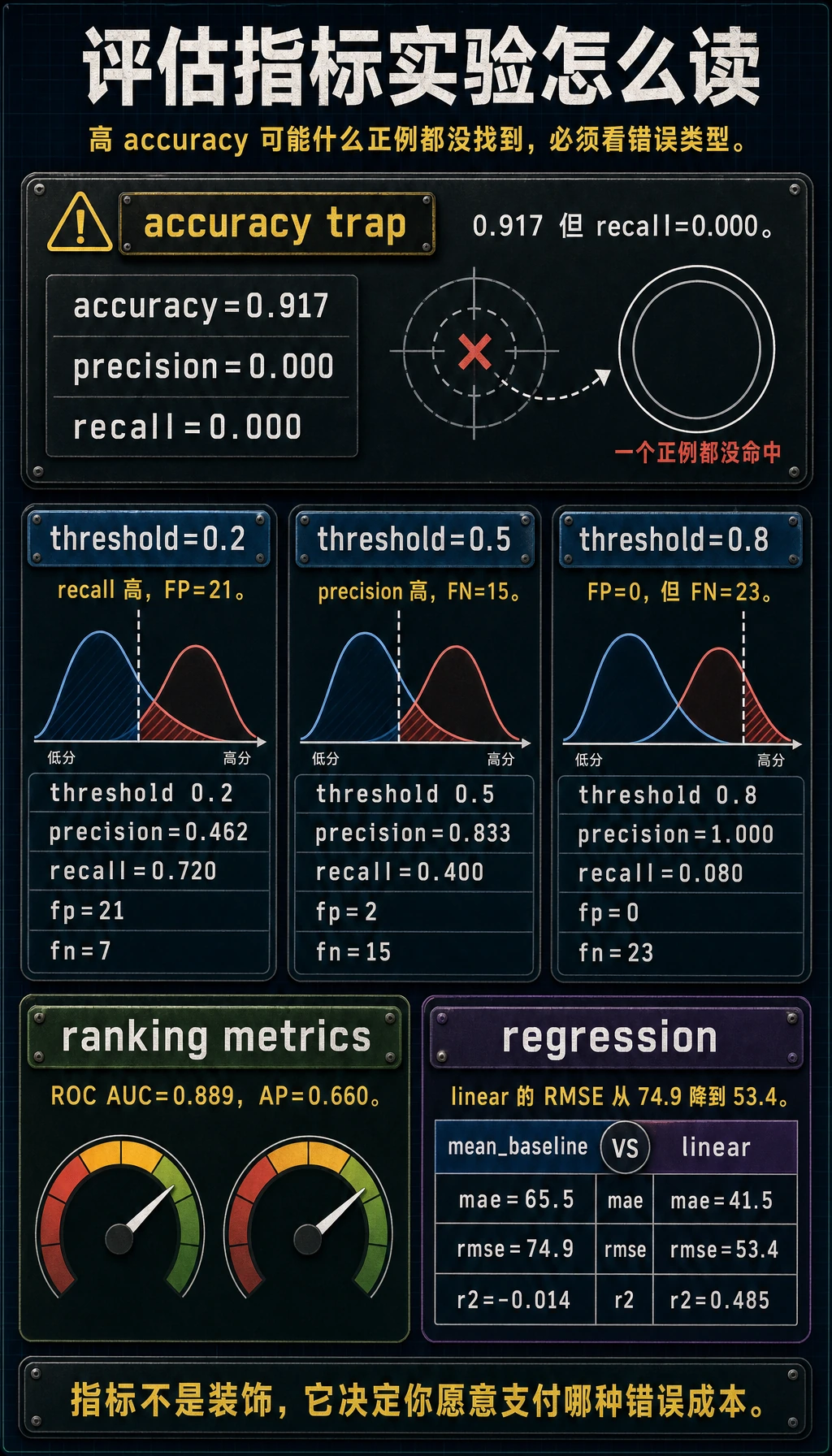
Accuracy 陷阱
Section titled “Accuracy 陷阱”baseline 每次都预测多数类:
accuracy=0.917precision=0.000recall=0.000accuracy 看起来很高,但它一个正类都没找到。对不平衡分类来说,只看 accuracy 可能非常误导。
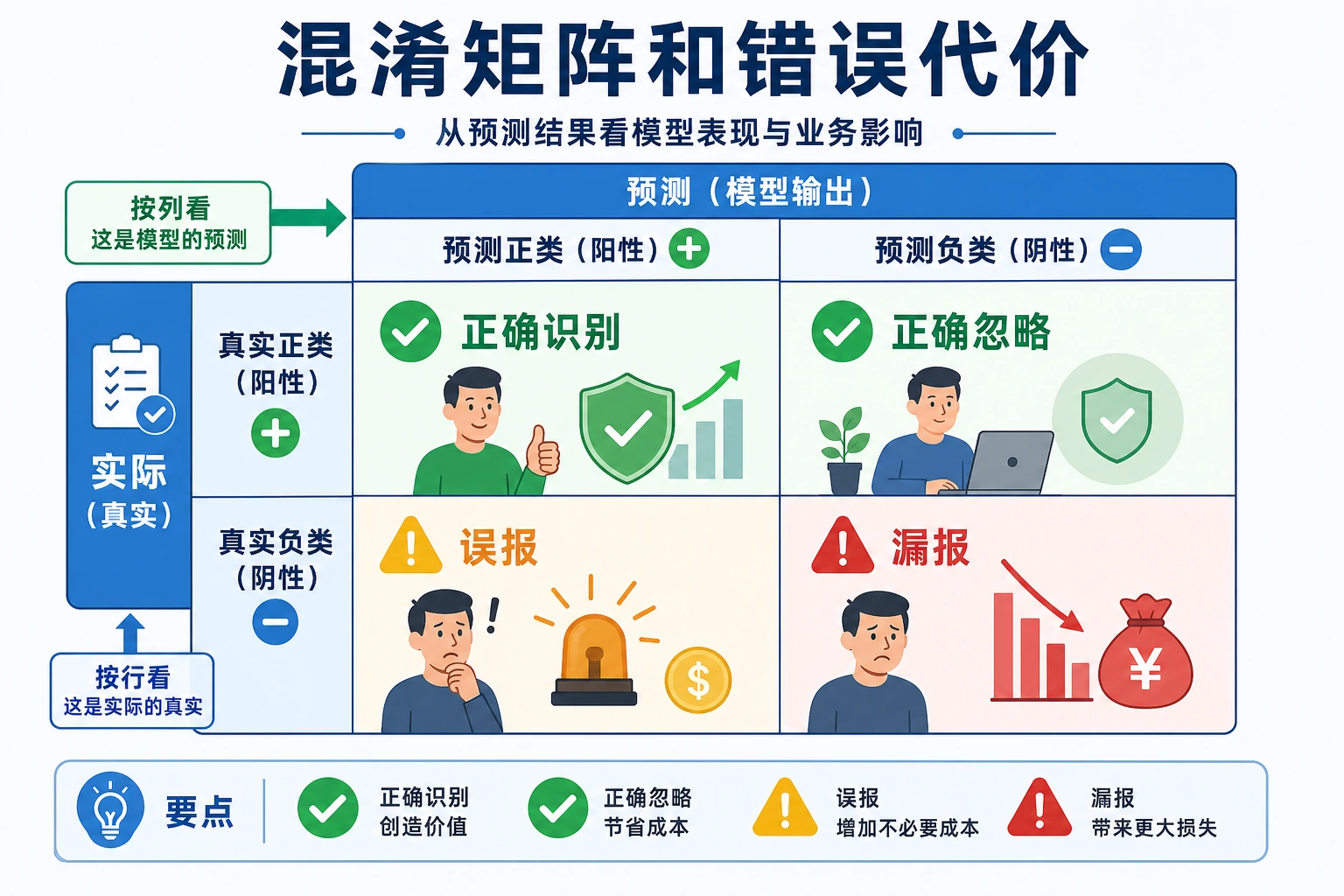
先看混淆矩阵
Section titled “先看混淆矩阵”所有分类指标都来自四个数量:
| 数量 | 含义 |
|---|---|
TP | 正类被正确找出 |
FP | 正常样本被误报 |
FN | 正类被漏掉 |
TN | 正常样本被正确忽略 |
选指标前先问:
FP更贵,还是FN更贵?- 模型用于初筛、排序、拦截,还是最终决定?
- 人工能复核多少样本?
阈值会改变故事
Section titled “阈值会改变故事”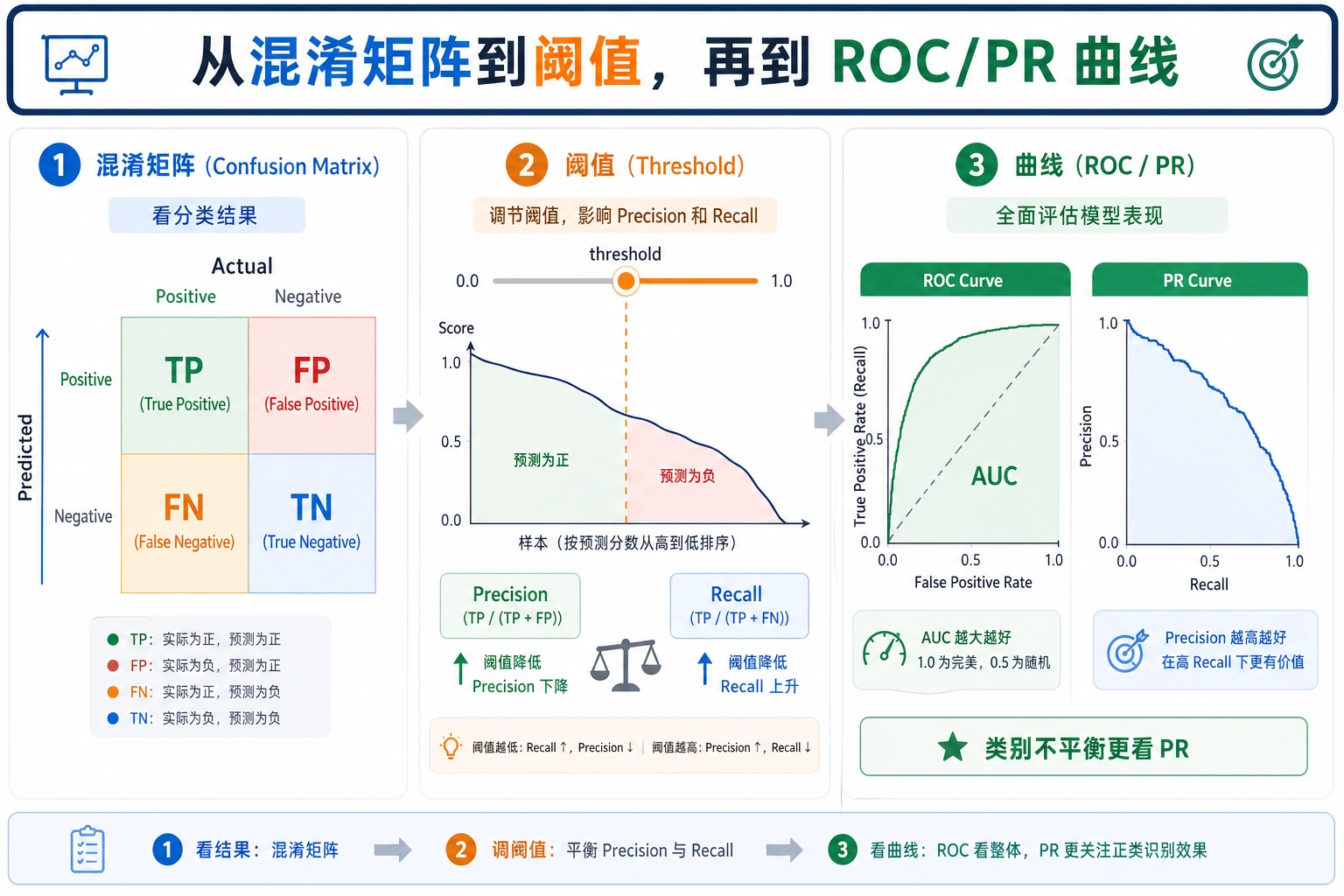
同一个模型在不同阈值下表现不同:
threshold=0.2 precision=0.462 recall=0.720 fp=21 fn=7threshold=0.8 precision=1.000 recall=0.080 fp=0 fn=23降低阈值会抓到更多正类,但误报也更多。提高阈值会减少误报,但漏掉更多正类。
可以这样选:
| 产品目标 | 主要指标 |
|---|---|
| 尽量找回正类 | recall |
| 告警要可信 | precision |
| 平衡 precision 和 recall | F1 |
| 跨阈值排序候选 | ROC AUC |
| 正类稀少 | average precision / PR curve |
ROC AUC 与 Average Precision
Section titled “ROC AUC 与 Average Precision”roc_auc=0.889 表示模型在多个阈值下,把正类排在负类前面的能力还不错。
average_precision=0.660 对稀有正类更严格,因为它关注 precision-recall 行为。欺诈、医疗筛查、安全告警、流失挽回这类任务,一定要看 precision-recall 指标,而不是只看 ROC AUC。
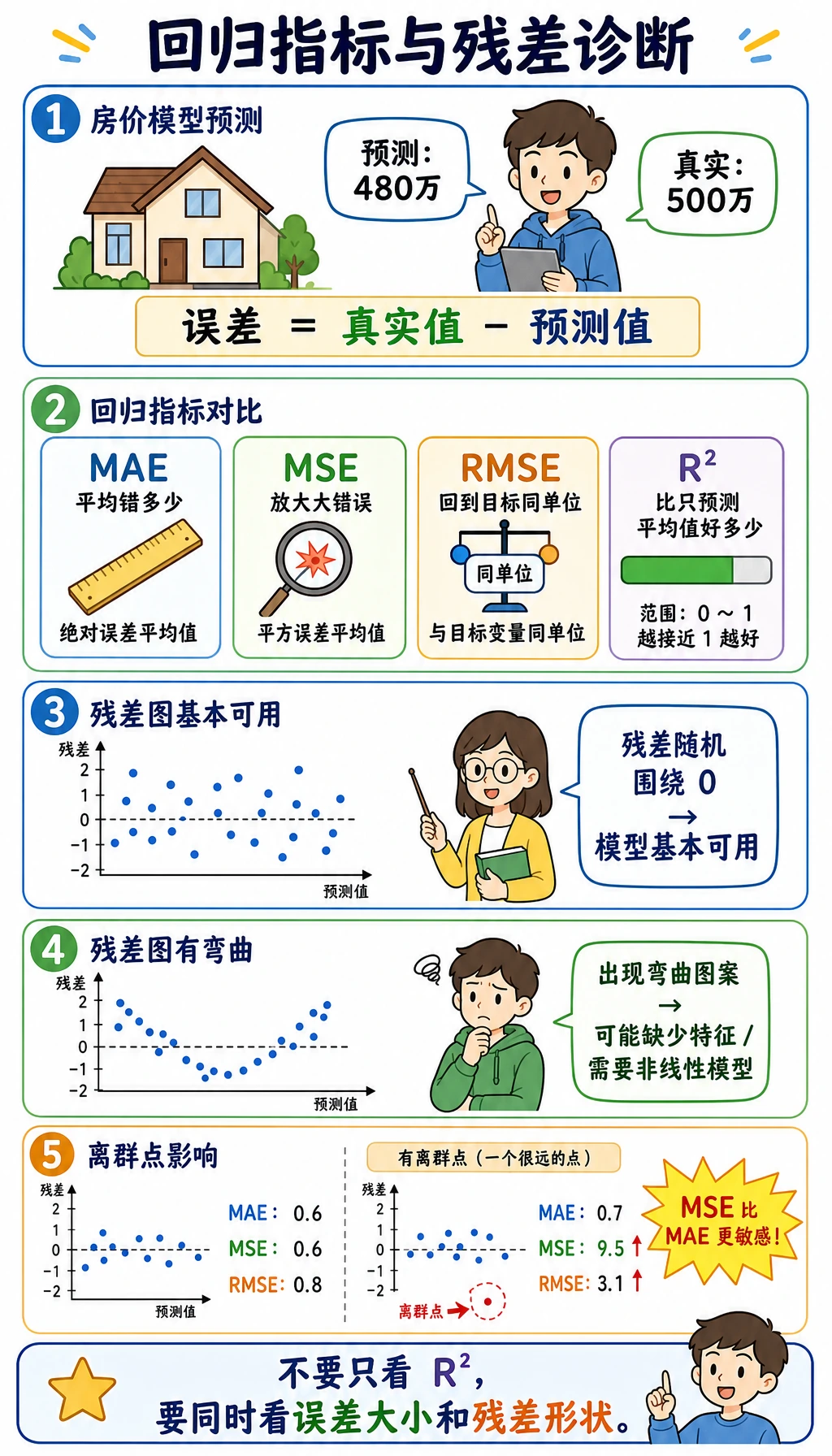
回归实验比较了均值基线和线性模型:
mean_baseline mae=65.5 rmse=74.9 r2=-0.014linear mae=41.5 rmse=53.4 r2=0.485这样读:
| 指标 | 适合场景 |
|---|---|
MAE | 希望用原始单位理解平均误差 |
RMSE | 大错误特别痛时 |
R2 | 想知道模型比均值基线好多少 |
不要只依赖 R2。一个模型可能 R2 还可以,但在关键样本上误差不可接受。
实用指标选择
Section titled “实用指标选择”| 任务 | 先看 | 再检查 |
|---|---|---|
| 平衡分类 | accuracy、F1 | 混淆矩阵 |
| 不平衡分类 | precision、recall、F1 | PR 曲线、阈值表 |
| 初筛 / 检测 | recall | 告警量与误报 |
| 最终批准 / 拦截 | precision | 漏报与人工复核策略 |
| 排序 | ROC AUC、average precision | top-k precision |
| 回归 | MAE、RMSE | 残差图和分组误差 |
给有经验的读者:要按分群评估。全局指标可能掩盖某个地区、客户群、语言、设备类型或稀有类别的失败。
学完这一页,至少保留这张证据卡:
- 评估设置
- 划分、交叉验证、指标、基线和对比目标
- 结果
- 分数表、曲线、混淆矩阵、验证结果,或搜索结果
- 决策
- 是否更改数据、特征、模型、阈值或超参数
- 失败检查
- 泄漏、验证不稳定、指标错误或在测试集上调参
- 期望产出
- 支持下一步建模决策的评估记录
常见排查清单
Section titled “常见排查清单”| 现象 | 可能原因 | 修复方式 |
|---|---|---|
| accuracy 很高但 recall 为零 | 类别不平衡 | 看混淆矩阵和 recall |
| ROC AUC 好但告警很差 | 阈值不合适或正类稀少 | 看 PR 曲线和告警量 |
| F1 提升但产品变差 | 指标不匹配业务成本 | 明确定义 FP/FN 成本 |
| 回归平均误差看起来还行 | 某些分群里隐藏大错误 | 按分群检查残差 |
| 线上指标下降 | 分布漂移 | 监控数据和指标漂移 |
- 把类别权重改成
[0.98, 0.02]。accuracy 和 recall 怎么变? - 加入阈值
[0.1, 0.3, 0.7, 0.9]。如果是初筛任务,你会选哪个? - 为每个阈值打印
tp、fp、fn、tn。 - 加入一个树模型,比较 ROC AUC 和 average precision。
- 回归部分打印绝对误差最大的五个样本,并检查输入。
参考实现与讲解
- 正类只有 2% 时,accuracy 可能很好看,即使模型漏掉很多正类。此时 recall、precision 比单纯 accuracy 更有解释力。
- 初筛任务通常更偏向低阈值,例如
0.1或0.3,因为要减少漏报。代价是误报增加,所以最终选择要看人工复核能力。 - 混淆矩阵计数应呈现清晰趋势:阈值降低时
tp和fp增加;阈值升高时fp减少,但fn增加。 - 稀有正类任务里 ROC AUC 可能仍然好看,average precision 通常更能反映模型是否把少数正类排在前面。
- 最大回归误差经常暴露数据质量、少数群体或缺失特征问题。它比单个平均指标更能指导下一步特征修复。
你能解释下面几点,就完成本节:
- 不平衡数据上 accuracy 可能误导;
- precision 和 recall 对应不同错误成本;
- 阈值选择是产品设计的一部分;
- ROC AUC 与 PR 指标回答的问题不同;
- 回归指标需要配合残差和分群检查。